YOLOv8 Real-world Application: Product Recognition and Localization in Smart Retail
发布时间: 2024-09-15 07:43:54 阅读量: 21 订阅数: 24 

yolov8系列--Automatic Number Plate Recognition (ANPR) Using .zip
# 1. Introduction to YOLOv8 and Its Applications
YOLOv8 is one of the most advanced real-time object detection algorithms known for its speed and accuracy. It utilizes deep learning technology, specifically Convolutional Neural Networks (CNN), to extract features from images and predict the location and category of objects.
The network structure of YOLOv8 consists of a backbone network and a detection head. The backbone network is responsible for feature extraction from images, while the detection head predicts the location and category of objects. The backbone network often uses pre-trained models such as ResNet or EfficientNet, whereas the detection head is a custom network designed for object detection tasks.
# 2. Practical Applications of YOLOv8
### 2.1 Constructing a Dataset for Product Identification and Localization
#### 2.1.1 Data Collection and Annotation
Building a dataset for product identification and localization is fundamental to model training. For product identification tasks, we need to collect a large number of images of various products and annotate the products within the images. The annotation information usually includes the category, location, and size of the products.
**Data Collection**
Data collection can be done in various ways, such as:
- Downloading product images from online stores or social media platforms.
- Using smartphones or cameras to capture product images.
- Collaborating with retailers to obtain product images.
**Data Annotation**
Data annotation can be done using specialized tools like LabelImg or VGG Image Annotator. During annotation, the following operations need to be performed for each product in the images:
- **Category Annotation:** Assign a category label to the product, such as "Food," "Clothing," or "Electronics."
- **Location Annotation:** Use bounding boxes or polygons to mark the location of the product in the image.
- **Size Annotation:** Record the width and height of the product.
#### 2.1.2 Data Preprocessing and Augmentation
Before model training, collected data needs to be preprocessed and augmented. Preprocessing includes:
- **Image Adjustment:** Adjust image size, format, and color space.
- **Data Augmentation:** Enhance the dataset by randomly cropping, rotating, flipping, and adding noise to improve the model's generalization capabilities.
**Code Example:**
```python
import cv2
import numpy as np
# Load image
image = cv2.imread("image.jpg")
# Adjust image size
image = cv2.resize(image, (416, 416))
# Random crop
image = cv2.randomCrop(image, (416, 416))
# Random rotation
image = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
# Random flip
image = cv2.flip(image, 1)
# Add noise
image = image + np.random.normal(0, 10, image.shape)
```
### 2.2 Training and Evaluating the YOLOv8 Model
#### 2.2.1 Model Configuration and Training Parameters
The configuration and training parameters of the YOLOv8 model greatly affect its performance. Main configuration parameters include:
- **Backbone:** The network structure used to extract features, such as Darknet53 or CSPDarknet53.
- **Neck:** The network structure that connects the backbone and the detection head, such as PANet or FPN.
- **Detection Head:** The network structure responsible for predicting the location and category of objects, such as YOLO Head or RetinaNet Head.
- **Training Parameters:** Including learning rate, batch size, and number of training epochs.
**Code Example:**
```python
import torch
# Model configuration
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# Training parameters
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
batch_size = 16
num_epochs = 100
```
#### 2.2.2 Model Training Process and Evaluation Metrics
The model training process involves the following steps:
1. Load data into the trainer.
2. Feed d

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
永磁同步电机控制策略仿真:MATLAB_Simulink实现
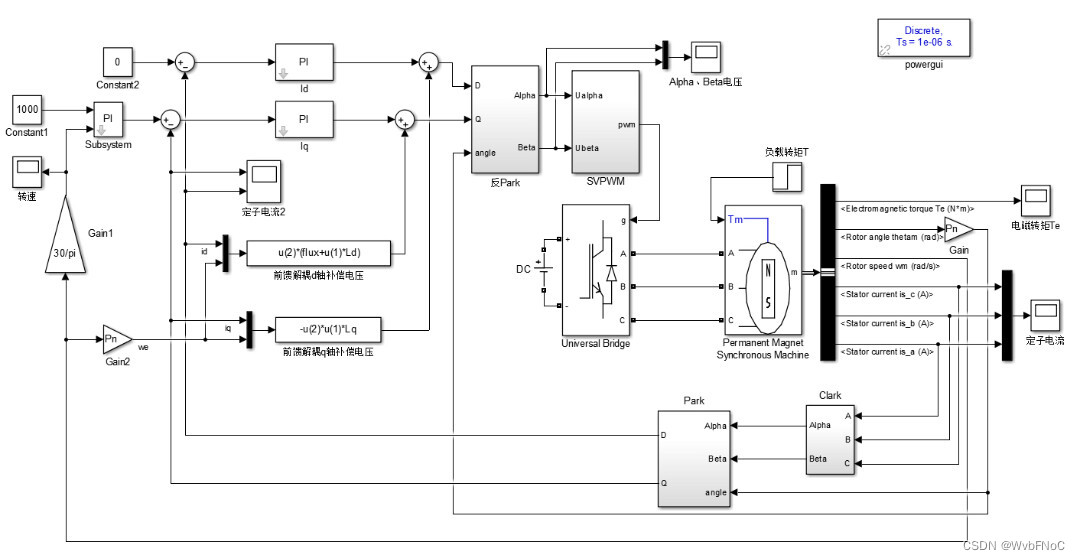
# 摘要
本文概述了永磁同步电机(PMSM)的控制策略,首先介绍了MATLAB和Simulink在构建电机数学模型和搭建仿真环境中的基础应用。随后,本文详细分析了基本控制策略,如矢量控制和直接转矩控制,并通过仿真结果进行了性能对比。在高级控制策略部分,我们探讨了模糊控制和人工智能控制策略在电机仿真中的应用,并对控制策略进行了优化。最后,通过实际应用案例,验证了仿真模型的有效性,并
【编译器性能提升指南】:优化技术的关键步骤揭秘
# 摘要
编译器性能优化对于提高软件执行效率和质量至关重要。本文详细探讨了编译器前端和后端的优化技术,包括前端的词法与语法分析优化、静态代码分析和改进以及编译时优化策略,和后端的中间表示(IR)优化、指令调度与并行化技术、寄存器分配与管理。同时,本文还分析了链接器和运行时优化对性能的影响,涵盖了链接时代码优化、运行时环境的性能提升和调试工具的应用。最后,通过编译器优化案例分析与展望,本文对比了不同编译器的优化效果,并探索了机器学习技术在编译优化中的应用,为未来的优化工作指明了方向。
# 关键字
编译器优化;前端优化;后端优化;静态分析;指令调度;寄存器分配
参考资源链接:[编译原理第二版:
Catia打印进阶:掌握高级技巧,打造完美工程图输出
# 摘要
本文全面探讨了Catia软件中打印功能的应用和优化,从基本打印设置到高级打印技巧,为用户提供了系统的打印解决方案。首先概述了Catia打印功能的基本概念和工程图打印设置的基础知识,包括工程图与打印预览的使用技巧以及打印参数和布局配置。随后,文章深入介绍了高级打印技巧,包括定制打印参数、批量打印、自动化工作流以及解决打印过程中的常见问题。通过案例分析,本文探讨了工程图打印在项目管理中的实际应用,并分享了提升打印效果
快速排序:C语言中的高效稳定实现与性能测试
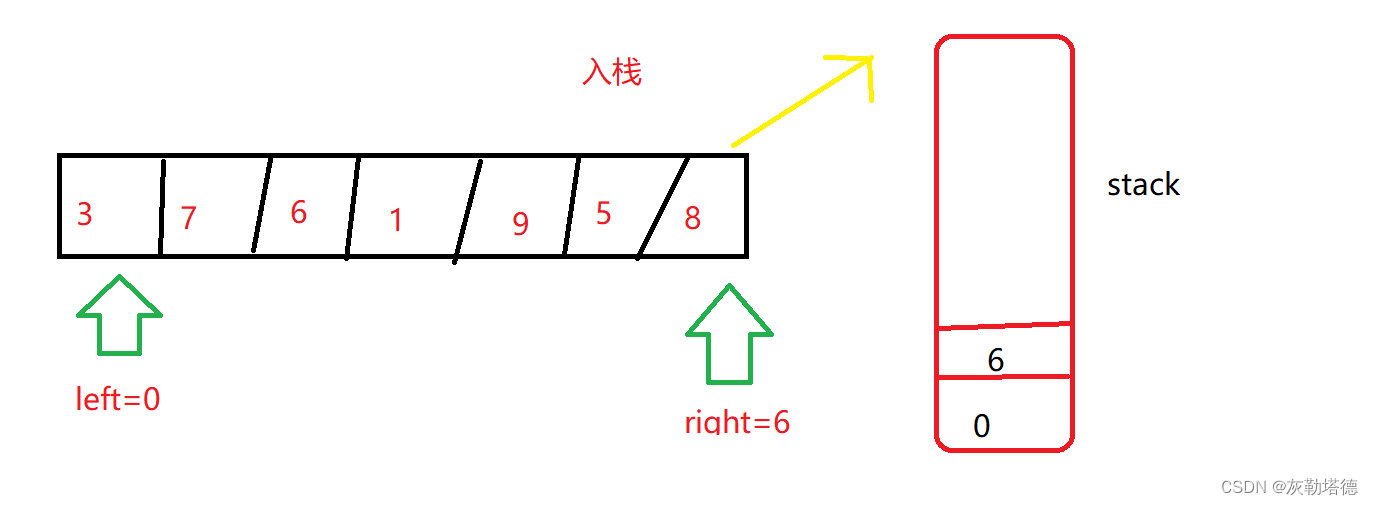
# 摘要
快速排序是一种广泛使用的高效排序算法,以其平均情况下的优秀性能著称。本文首先介绍了快速排序的基本概念、原理和在C语言中的基础实现,详细分析了其分区函数设计和递归调用机制。然后,本文探讨了快速排序的多种优化策略,如三数取中法、尾递归优化和迭代替代递归等,以提高算法效率。进一步地,本文研究了快速排序的高级特性,包括稳定版本的实现方法和非递归实现的技术细节,并与其他排序算法进行了比较。文章最后对快速排序的C语言代码实现进行了分析,并通过性能测
CPHY布局全解析:实战技巧与高速信号完整性分析
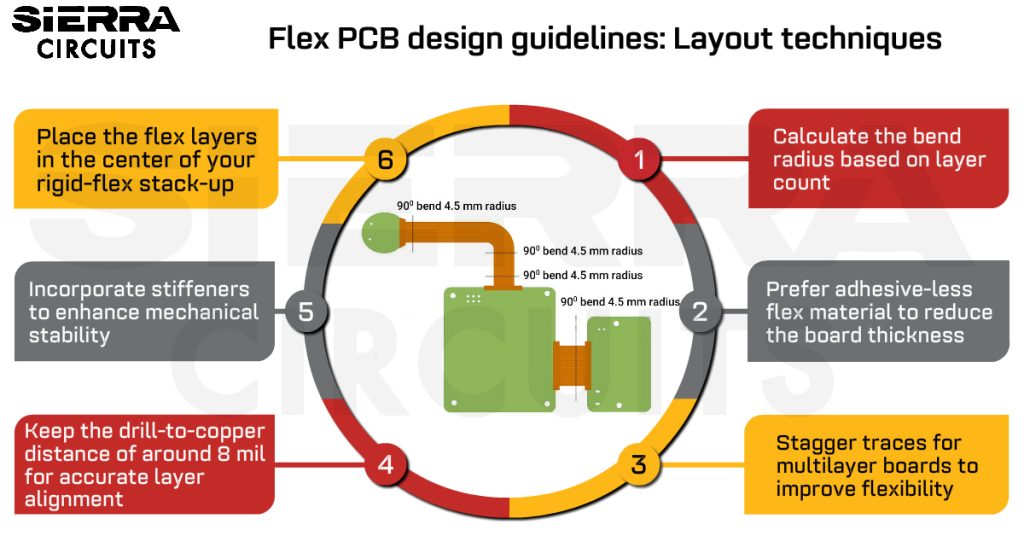
# 摘要
CPHY布局技术是支持高数据速率和高分辨率显示的关键技术。本文首先概述了CPHY布局的基本原理和技术要点,接着深入探讨了高速信号完整性的重要性,并介绍了分析信号完整性的工具与方法。在实战技巧方面,本文提供了CPHY布局要求、走线与去耦策略,以及电磁兼容(EMC)设计的详细说明。此外,本文通过案
四元数与复数的交融:图像处理创新技术的深度解析

# 摘要
本论文深入探讨了图像处理与数学基础之间的联系,重点分析了四元数和复数在图像处理领域内的理论基础和应用实践。首先,介绍了四元数的基本概念、数学运算以及其在图像处理中的应用,包括旋转、平滑处理、特征提取和图像合成等。其次,阐述了复数在二维和三维图像处理中的角色,涵盖傅里叶变换、频域分析、数据压缩、模型渲染和光线追踪。此外,本文探讨了四元数与复数结合的理论和应用,包括傅里叶变
【性能优化专家】:提升Illustrator插件运行效率的5大策略

# 摘要
随着数字内容创作需求的增加,对Illustrator插件性能的要求也越来越高。本文旨在概述Illustrator插件性能优化的有效方法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )