Common Issues and Solutions for Preparing YOLOv8 Training Datasets
发布时间: 2024-09-15 07:15:34 阅读量: 58 订阅数: 24 

【船级社】 BV GUIDANCE FOR STUDYING AND PREPARING A BULK CARRIER
# Overview of Preparing YOLOv8 Training Dataset
The preparation of the YOLOv8 training dataset is a crucial step in training efficient object detection models. A high-quality dataset can improve the accuracy and generalization capabilities of the model. This section outlines the key steps in the YOLOv8 dataset preparation process, including data collection, preprocessing, annotation, and validation.
# 2. Dataset Collection and Preprocessing
### 2.1 Data Collection Strategies
#### 2.1.1 Data Sources and Annotation Tools
**Data Sources:**
* Public datasets: COCO, VOC, ImageNet
* Private datasets: Custom datasets collected by enterprises
* Web crawlers: Collecting images and labels from the internet
**Annotation Tools:**
* LabelImg: An open-source image annotation tool supporting rectangle, polygon, and keypoint annotations
* VGG Image Annotator: A sophisticated annotation tool offering a range of annotation features and quality control
* Labelbox: A cloud-based annotation platform providing collaboration and data management features
#### 2.1.2 Data Diversity and Balance
**Data Diversity:**
* Ensure the dataset includes a variety of scenes, object types, lighting conditions, and backgrounds
* Avoid overrepresented or underrepresented categories in the dataset
**Data Balance:**
* Balance the number of samples across different categories or object sizes
* Use weighted sampling or oversampling techniques to address imbalanced data distribution
### 2.2 Data Preprocessing Workflow
#### 2.2.1 Data Cleaning and Filtering
***Remove damaged or duplicate images:** Use image processing libraries or scripts to check for image integrity and uniqueness
***Filter out low-quality or noisy images:** Based on image resolution, contrast, or other quality metrics
***Verify annotation accuracy:** Manually or with automated tools check for accuracy and consistency in annotations
#### 2.2.2 Data Augmentation and Transformation
***Image augmentation:** Randomly crop, flip, rotate, and resize images to increase data diversity
***Data transformation:** Convert images to different formats or resolutions to fit model requirements
***Generate synthetic data:** Use GANs or other techniques to create new images and annotations to expand the dataset
```python
import cv2
# Randomly crop an image
def random_crop(image, size):
height, width, _ = image.shape
x = np.random.randint(0, width - size[0])
y = np.random.randint(0, height - size[1])
return image[y:y+size[1], x:x+size[0]]
# Randomly flip an image
def random_flip(image):
return cv2.flip(image, 1)
# Randomly rotate an image
def random_rotate(image):
angle = np.random.randint(-30, 30)
return cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE, angle)
```
**Logical Analysis:**
The code blocks above implement random cropping, flipping, and rotating operations for image augmentation. These operations can increase the diversity of the dataset, thereby enhancing the model's generalization ability.
**Parameter Description:**
* `image`: Input image
* `size`: Size of the cropped image
* `angle`: Rotation angle
# 3. Dataset Annotation and Validation
### 3.1 Annotation Tools and Criteria
**3.1.1 Selection of Annotation Tools**
***mon annotation tools include:
- **LabelImg:** An open-source image annotation tool supporting rectangle, polygon, point, etc. annotation types.
- **CVAT:** A browser-based annotation platform offering rich annotation features such as multi-object tracking, video annotation.
- **Labelbox:** A cloud-based annotation platform providing collaborative annotation, data management, and quality control features.
**3.1.2 Annotation Criteria and Quality Control**
Establishing clear annotation criteria is vital to ensuring annotation quality. Criteria should include:
- **Annotation Types:** Define the types of objects to be annotated, such as bounding boxes, semantic segmentation, etc.
- **Annotation Format:** Specify the storage format for annotated data, such as JSON, XML.
- **Annotation Rules:** Clarify rules for annotating targets, such as target boundaries, occlusion handling.
To ensure annotation quality, a strict quality control process should be implemented, including:
- **

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
华为云DevOps工具链:打造快速迭代的高效开发环境
# 摘要
华为云DevOps作为一种先进的开发运维一体化方法论,强调了流程自动化、文化培养和组织变革的重要性。本文首先概述了DevOps的起源、核心价值和关键实践原则,并讨论了工具链整合、流程自动化的基本要素和构建支持DevOps文化所必须的组织结构调整。随后,文章着重介绍了华为云在CI/CD流程搭建、容器化、微服务架构设计、性能测试和自动化监控方面的应用实践。高级特性章节探讨了代码质量管
【ANSYS Fluent网格优化】:网格划分的5大实战技巧,提升仿真实效

# 摘要
随着计算流体力学(CFD)和结构分析在工程领域中的应用越来越广泛,高质量网格生成的重要性日益凸显。本文从基础理论入手,详细介绍了ANSYS Fluent网格优化的入门知识、网格划分的基础理论、实践技巧以及对仿真效率的影响。通过对网格自适应技术、网格划分软件工具的使用、网格质量检查与修正等实践技巧的探讨,文章进
【NR系统可伸缩性】:设计可扩展渲染网络的秘诀
# 摘要
随着技术的发展和应用需求的增加,NR系统的可伸缩性变得越来越重要。本文首先概述了NR系统可伸缩性的概念,接着探讨了其理论基础和设计原则,涵盖了系统伸缩性的定义、分类、架构设计原则,如分层架构、无状态设计、负载均衡与资源分配策略。通过实践案例分析,本文深入研究了网络渲染系统的负载均衡策略、数据分片技术以及系统监控与性能评估的方法。进一步探讨了高级技术的应用与
四元数卷积神经网络:图像识别应用的突破与实践

# 摘要
四元数卷积神经网络是一种新兴的深度学习架构,它结合了四元数数学和卷积神经网络(CNN)的优势,以处理三维和四维数据。本文首先介绍了四元数卷积神经
Catia自定义模板创建:简化复杂项目,实现高效一致打印

# 摘要
Catia自定义模板创建对于提高工程设计效率和标准化流程至关重要。本文从理论基础入手,深入探讨了Catia模板的定义、应用领域、结构、组成以及创建流程。通过实践章节,本文详细介绍了基础模板框架的创建、高级功能的实现、以及模板的测试与优化。此外,本文还探讨了Catia模板在打印管理中的应用,并提供了实际案例研究。最后,本文展望
【Illustrator功能拓展】:高级插件开发案例与实践分析

# 摘要
本文全面探讨了Illustrator插件开发的关键方面,包括开发环境的搭建、必备工具与语言的介绍、功能设计与实现、高级案例分析以及未来的发展趋势与创新。通过对插件与Illustrator的交互原理、开发环境设置、JavaScript for Automation (JXA) 语言和ExtendScript Toolkit工具的讨论,本文为开发人员提供了一套系统性的插件开发指南。同时,详
C语言快速排序与大数据:应对挑战的优化策略与实践
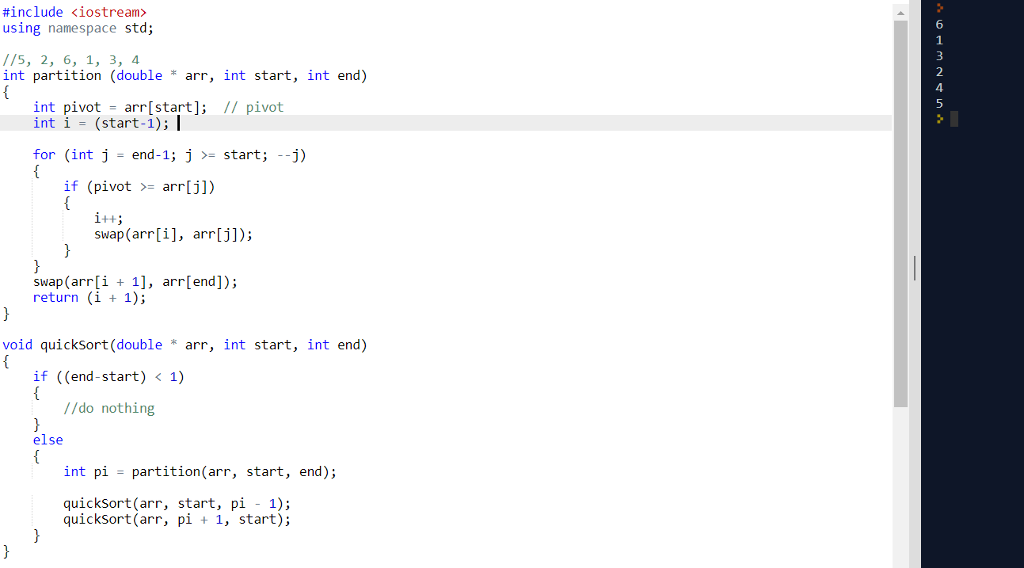
# 摘要
快速排序算法,作为一种高效、广泛应用的排序方法,一直是计算机科学中的研究热点。本文详细探讨了快速排序的基本原理、优化策略以及在大数据环境中的实践应用。通过对大数据环境下的优化实践进行分析,包括内存优化和存储设备上的优化,本文为提高快速排序在实际应用中的效率提供了理论依据和技术支持。同时,本文还研究了快速排序的变种算法和特定数据集上
【统计分析秘籍揭秘】:Applied Multivariate Statistical Analysis 6E中的技巧与实践
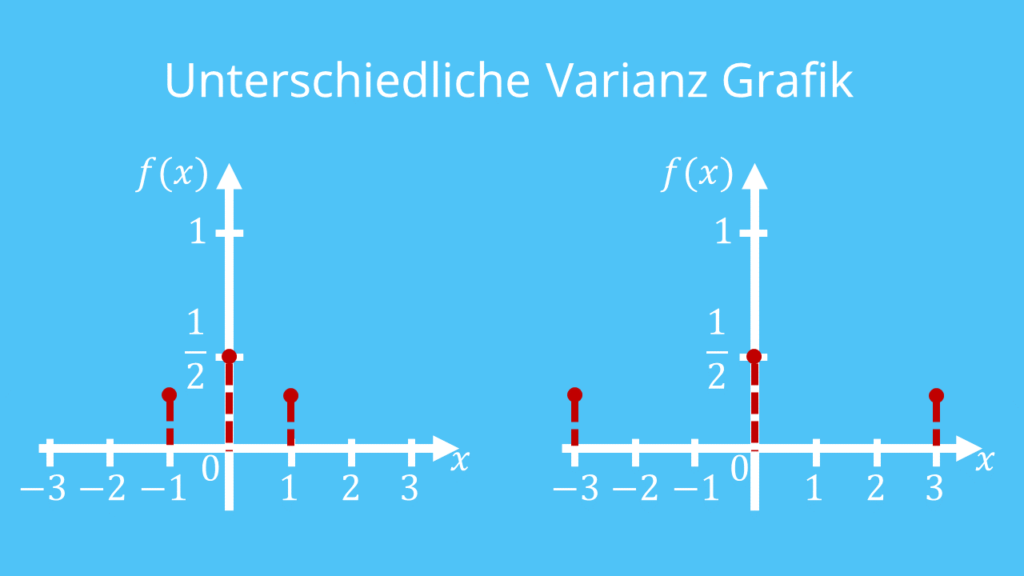
# 摘要
本文系统地介绍了多元统计分析的基本概念、描述性统计分析技巧、多变量分析方法、多元回归分析的深度应用以及高级统计分析技术。首先,概述了多元统计分析的重要性并回顾了描述性统计分析的核心技巧,如数据探索性分析和主成分分析(PCA)。随后,深入探讨了多变量分析方法实践,包含聚类分析、判别分析
降低电磁干扰的秘诀:CPHY布局优化技巧大公开
# 摘要
CPHY接口作为一种高速通信接口,其电磁干扰(EMI)管理对于保证信号的完整性和系统的可靠性至关重要。本文首先介绍了CPHY接口的电磁干扰基础知识和布局设计理论,强调了信号完整性和电磁兼容性的重要性,并探讨了影响这些因素的关键设计原则。接着,本文提供了CPHY布局优化的实践技巧,包括层叠优化、走线布线
【中文编程语言的崛起】:探索高级表格处理的可能性与挑战

# 摘要
随着编程语言的发展,中文编程语言开始受到关注,并展现出独特的语言优势。本文首先介绍了中文编程语言的兴起背景及其优势,随后详细阐述了其语法基础,包括标识符和关键字的命名规则、数据类型、变量的使用以及控制结构的中文表达。文章进一步探讨了中文编程语言在高级表格处理中的应用,涉及数据读取、复杂操作和可视化展示。最后,文章分析了中文编程语言所面临的挑战,包括性能优化、跨平台兼容性问题,并展望了其未来的发展方向和行业应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )