Optimization Methods for YOLOv8 Model: Network Pruning and Quantization
发布时间: 2024-09-15 07:31:59 阅读量: 52 订阅数: 28 

First-Order and Stochastic Optimization Methods for Machine Learning.pdf
# Optimization Techniques for the YOLOv8 Model: Network Pruning and Quantization
## 1. Introduction to YOLOv8 Model
YOLOv8 is the latest object detection algorithm released by Megvii Technology in 2022, which has achieved significant improvements in both speed and accuracy. YOLOv8 adopts a new network architecture and incorporates various optimization techniques, giving it outstanding performance in a wide range of application scenarios.
The network structure of YOLOv8 employs CSPDarknet53 as the backbone network, characterized by its lightweight and high efficiency. Building upon CSPDarknet53, YOLOv8 also introduces a new PAN path aggregation module, which effectively fuses features of different scales, thereby improving the model's detection accuracy.
Beyond network architecture optimization, YOLOv8 also employs a variety of optimization techniques, including:
***Data Augmentation Techniques:** YOLOv8 employs a variety of data augmentation techniques, such as random scaling, cropping, flipping, etc., to enhance the model's generalization capability.
***Loss Function Optimization:** YOLOv8 adopts a new loss function that can effectively balance classification loss and regression loss, thereby improving the model's detection accuracy.
***Training Strategy Optimization:** YOLOv8 adopts a new training strategy that can effectively improve the model's convergence speed and accuracy.
## ***work Pruning Optimization
### 2.1 Overview of Pruning Strategies
Pruning is a network optimization technique that reduces the model size and computational requirements by removing unimportant weights or channels. Pruning strategies can be broadly categorized into two types:
#### 2.1.1 Weight Pruning
Weight pruning involves removing unimportant weights from the model. The importance of weights can be measured by their absolute values, gradients, ***mon weight pruning algorithms include:
- **L1 Norm Pruning:** Removing weights with the smallest absolute values.
- **L2 Norm Pruning:** Removing weights with the smallest norms.
- **Gradient Pruning:** Removing weights with the smallest gradients.
#### 2.1.2 Channel Pruning
Channel pruning involves removing unimportant channels from the model. The importance of channels can be measured by their activation values, gradients, ***mon channel pruning algorithms include:
- **Max Average Pooling Pruning:** Removing channels with the smallest max average pooling values.
- **L1 Norm Pruning:** Removing channels with the smallest absolute values.
- **Gradient Pruning:** Removing channels with the smallest gradients.
### 2.2 Pruning Algorithms
Pruning algorithms can be broadly classified into two categories:
#### 2.2.1 Sparsification Pruning
Sparsification pruning creates sparse models by setting weights or channels to zero. Sparsification pruning algorithms include:
- **Threshold Pruning:** Setting weights or channels with absolute values below a threshold to zero.
- **Random Pruning:** Randomly removing weights or channels.
- **Structured Pruning:** Removing entire convolution kernels or channels.
#### 2.2.2 Structured Pruning
Structured pruning creates structured sparse models by removing entire convolution kernels or channels. Structured pruning algorithms include:
- **Pruning Convolution:** Removing entire convolution kernels.
- **Pruning Channels:** Removing entire channels.
- **Pruning Layers:** Removing entire layers.
### 2.3 Model Restoration After Pruning
After pruning, the model's accuracy may decline. To restore accuracy, ***mon restoration methods include:
- **Retraining:** Using the pruned model as initialization, retrain the model.
- **Fine-tuning:** Fine-tuning the pruned model to restore accuracy.
- **Knowledge Distillation:** Using knowledge distillation with the pruned model and an unpruned model to restore accuracy.
## 3. Quantization Optimization
### 3.1 Overview of Quantization
Quantization is a technique that converts floating-point data into fixed-point data, effectively reducing the model's storage and computational costs. In deep learning, quantization is often used to compress model size and increase inference speed.
#### 3.1.1 Types of Quantization
Quantization types are mainly divided into the following two:
- **Linear Quantization:** Linearly maps floating-point data to fixed-point data, maintaining the shape of the data distribution.
- **Symmetric Quantization:** Symmetrically maps floating-point data to fixed-point data, with the data distribution centered around zero.
#### 3.1.2 Methods of Quantization
Quantization methods are mainly divided into the following two:
- **Post-Training Quantization:** Quantizes model parameters and activation values after model training.
- **Training-Aware Quantization:** Incorporates quantization as part of the training process, allowing the model to maintain high accuracy after quantization.
### 3.2 Quantization Algorithms
#### 3.2.1 Linear Quantization
The linear quantization algorithm linearly maps floating-point data `x` to fixed-point data `y`:
```python
def linear_quantization(x, n_bits):
"""Linear quantization algorithm
Args:
x: Floating-point data
n_bits: Number of bits for fixed-point data
Returns:
Quantized fixed-point data
"""
min_val = np.min(x)
max_val = np.max(x)
scale = (max_val - min_val) / (2 ** n_bits - 1)
y = np.round((x - min_val) / scale)
return y
```
**Parameter Explanation:**
- `x`: Floating-point data
- `n_bits`: Number of bits for fixed-point data
**Code Logic Analysis:**
1. Calculate the minimum and maximum values of the floating-point data.
2. Calculate the quantization scale, which is the ratio of the floating-point data range to the fixed-point data range.
3. Subtract the minimum value from the floating-point data, then divide

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【西数硬盘维修WDR5.3新手指南】:一步步教你基础入门和工具使用

# 摘要
本文系统介绍了西数硬盘维修软件WDR5.3的操作流程和技巧。文章首先概述了硬盘的工作原理和常见故障类型,随后详细阐释了WDR5.3软件的基本理论知识、操作实践、进阶技巧以及性能优化方法。通过详细分析真实案例,本文评估了维修前后的硬盘性能和数据恢复成功率。最后,文章总结了维修过程中的成功和失败经验,并对硬盘维修行业未来的发展趋势进行了展望。
# 关键字
硬盘维修;WDR5.3软件;故障诊断;数据恢复;性能
编程传奇:雷军如何用汇编代码重塑编程世界

# 摘要
本文全面探讨了汇编语言编程的历史演变、基础理论、编程实践技巧、雷军与汇编语言的关联故事以及其现代应用和未来展望。文章第一章回顾了汇编语言的发展历程
【BSF服务部署策略】:从理论到实际的转变

# 摘要
BSF服务部署策略是一个关键领域,涉及服务的概念、优势、部署环境、配置、优化和故障处理。本文全面概述了BSF服务的部署策略,提供了基础理论知识,并介绍了配置和优化的实际方法。文中还探讨了BSF服务的安全策略、集群部署和API集成
【智能电网新纪元】:继电保护技术的革新与IT融合
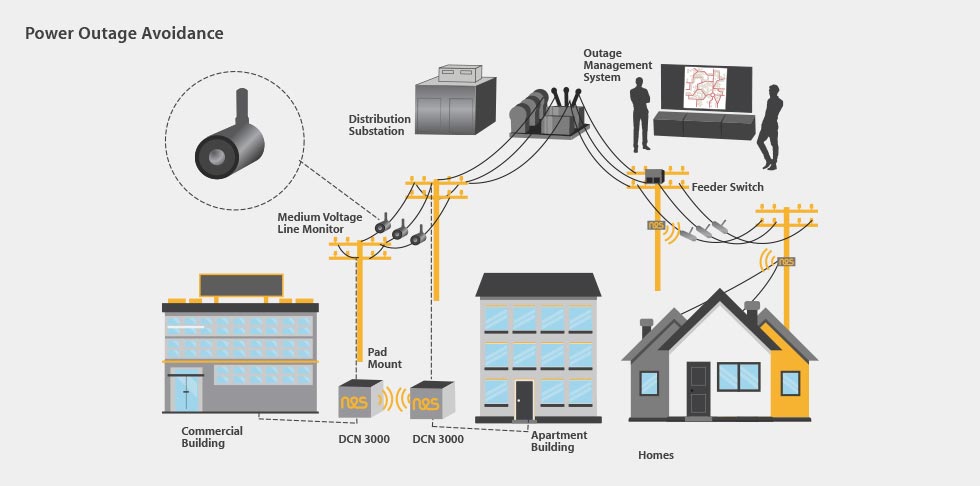
# 摘要
智能电网与继电保护技术是电力系统现代化的两大核心领域。本文首先概述了智能电网与继电保护技术的基本概念和理论基础,随后探讨了继电保护技术的创新进展和可靠性分析,同时分析了IT技术在继电保护领域的应用以及智能化系统架构和网络安全策略。在智能电网的IT技术融合实践章节,文章讨论了通信协议标准、IT系统实践案例和可持续发展策略。最后,文章展望了未来电网技术的发展方向,电网智能化面临的挑战和对策,并提出了创新与实践
【GMDSS通信原理揭秘】:深入理解与模拟实践技巧
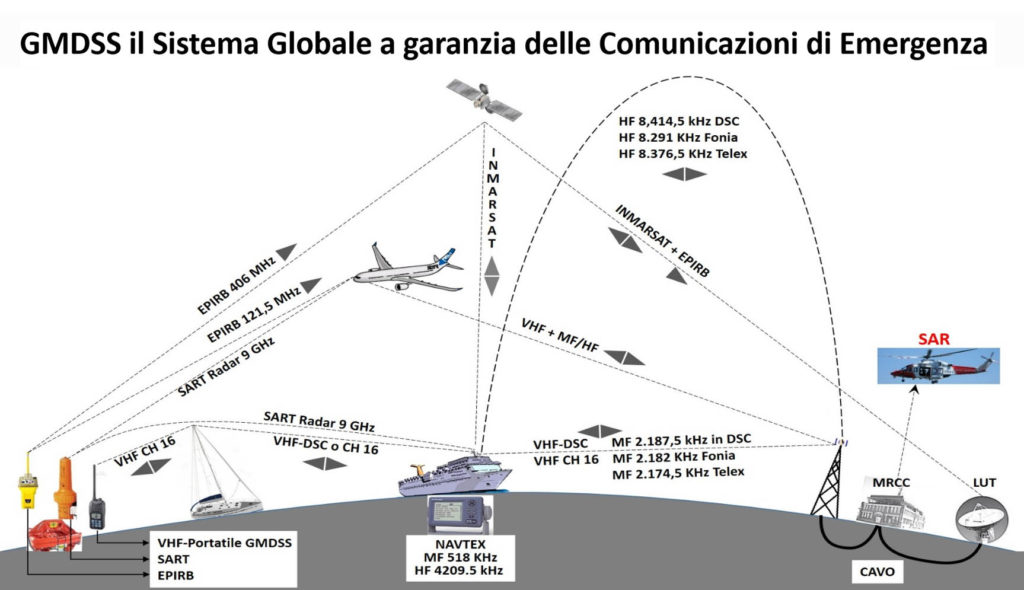
# 摘要
本文综述了全球海上遇险与安全系统(GMDSS)的通信技术,覆盖了硬件构成、通信协议、信号处理、模拟仿真,以及系统的安全与可靠性分析。在硬件构成方面,详细探讨了GMDSS主要设备的功能与分类、通信终端技术,以及导航设备与辅助系统。通信协议与信号部分介绍了GMDSS的标准协议、信号编码与调制技术,以及安全与紧急通信流程。模拟与仿真是通过软件进行通信测试和场景模拟,重点在于实验结果的分析与验证。安全与可靠性
【硬盘克隆进阶】:深入理解扇区级复制,个性化Ghost设置详解

# 摘要
随着信息技术的飞速发展,硬盘克隆技术已成为数据备份、迁移与恢复的重要手段。本文首先概述了硬盘克隆的基本概念及其在数据保护中的作用。随后,深入分析了扇区级复制的理论基础,包括硬盘结构、扇区定义及其复制原理。在个性化Ghost设置部分,本文详细介绍了Ghost软件的操作方法、硬件加速技巧以及扇区映射和错误检测的技术。通过实践操作部分,本文指导读者如何手动和通过自
FT232H接口设计:硬件与软件的考量要点

# 摘要
FT232H作为一种常用的USB转串口芯片,在数据通信领域发挥着重要作用。本文首先概述了FT232H接口的基本概念及其工作原理,然后深入分析了硬件设计的关键考量,包括电气特性、电源管理、PCB设计等。接着,文章探讨了软件驱动开发中固件与驱动架构、跨平台兼容性以及高级通信协议实现的重要性。通过不同领域应用实例的分析,展示了F
研发部门绩效考核案例研究:构建高效研发团队的KPI系统秘籍

# 摘要
绩效考核在研发团队管理中扮演着至关重要的角色,它直接关联到团队的工作效率和目标达成。本文深入探讨了KPI(关键绩效指标)与研发团队绩效之间的紧密联系,以及如何设计有效的KPI体系以确保其与组织目标的一致性。文章通过具体实践案例,分析了建立高效研发团队KPI系统的过程,并指出
【网络启动故障不求人】:一步步教你排查与解决PXE和GHOST常见问题

# 摘要
网络启动技术是现代IT基础设施部署中不可或缺的一部分,本文旨在探讨网络启动技术的基础原理、故障排查以及高级应用。首先,介绍了PXE启动技术及其故障排查,包括PXE的工作原理、常见故障类型和排查方法。接着,深入分析了GHOST部署中遇到的故障问题及其解决策略。此外,本文还探讨了网络启动的高级应用,例如集中管理和自动化部署,以及如何通过工具
STM32定时器高级应用:HAL库定时技巧与案例分析
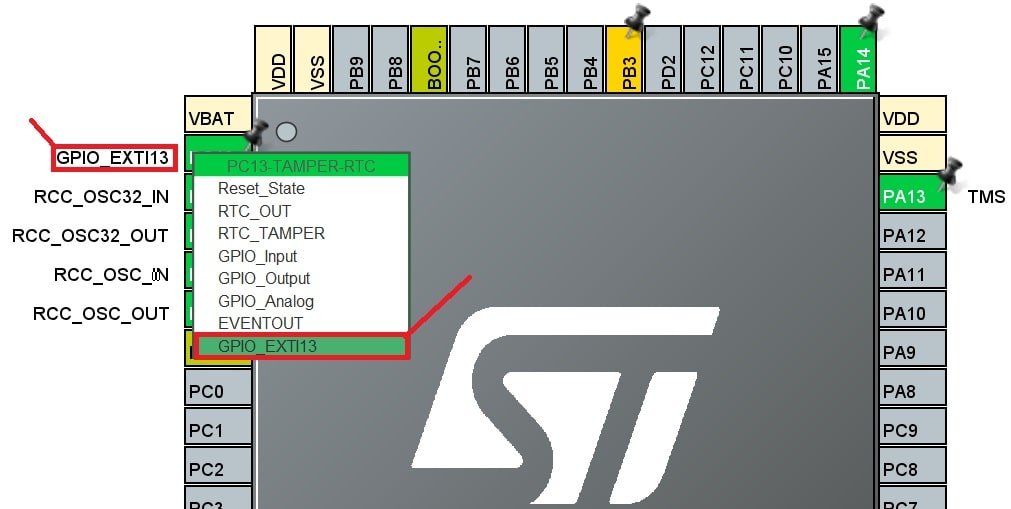
# 摘要
本文系统地探讨了STM32微控制器中定时器的功能、配置和应用。首先,介绍了定时器的基本工作原理和HAL库提供的API函数,以及定时器配置参数的详细解析。随后,本文深入阐述了定时器编程技巧,包括如何精确配置定时器时间和实现高级应用。文章进一步分析了定时器在不同应用场景中的实际运用,比如通信
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )