An Overview of YOLOv8's Application in Object Detection
发布时间: 2024-09-15 07:12:41 阅读量: 43 订阅数: 46 
# Overview of YOLOv8 Application in Object Detection
**1. Overview of the YOLOv8 Object Detection Algorithm**
YOLOv8 marks a groundbreaking advancement in the field of object detection, elevating both accuracy and speed to unprecedented levels. YOLOv8 is a single-stage object detection algorithm, capable of predicting the location and category of objects in a single forward pass. This efficient design gives YOLOv8 a significant edge in real-time applications such as video surveillance, autonomous driving, and robotics.
**2. Theoretical Foundations of YOLOv8**
### 2.1 Convolutional Neural Networks (CNN)
A Convolutional Neural Network (CNN) is a type of deep learning model particularly suited for processing grid-structured data, such as images. A CNN consists of key layers:
- **Convolutional Layer:** Uses a set of filters, or weight matrices, to slide over input data to extract features.
- **Pooling Layer:** Downsamples the output of convolutional layers to reduce the size of feature maps.
- **Fully Connected Layer:***
**N learns the hierarchical structure of data by extracting increasingly abstract features at different layers.
### 2.2 Evolution of Object Detection Algorithms
Object detection algorithms aim to identify and locate objects of interest within images. With the rise of deep learning, significant progress has been made in object detection.
- **Traditional Methods:** Based on sliding windows and manual features, computationally expensive and limited in accuracy.
- **Region-based Convolutional Neural Networks (R-CNN):** Use CNN to extract region proposals, followed by classification and bounding box regression.
- **Single Shot Multibox Detector (SSD):** Divides the image into a grid and predicts bounding boxes and categories for each grid cell.
- **You Only Look Once (YOLO):** Directly predicts bounding boxes and categories from the image, eliminating the need for region proposals or post-processing.
### 2.3 Innovations in YOLOv8
YOLOv8 builds upon the YOLO series algorithms and introduces the following innovations:
- **Bag-of-Freebies:** A collection of data augmentation techniques and regularization strategies that enhance performance without additional training costs.
- **Cross-Stage Partial Connections:** Optimizes the connection of feature pyramid networks (FPN), improving feature utilization.
- **Deep Supervision:** Adds auxiliary supervision loss at different stages of the network, enhancing model robustness.
- **Mish Activation Function:** Introduces the Mish activation function, which offers smooth non-monotonicity, improving the model's nonlinear expression capabilities.
- **Path Aggregation Network (PAN):** Fuses features at different scales, strengthening the model's multi-scale detection ability.
These innovations collectively enhance the precision, speed, and generalizability of YOLOv8.
**3.1 Dataset Preparation and Preprocessing**
#### Dataset Preparation
Training object detection models requires a substantial amount of well-annotated datasets. YOLOv8 supports a variety of image datasets, including COCO, VOC, and ImageNet.
1. **Image Collection:** Gather images relevant to the object detection task. Images can be downloaded from the internet, taken personally, or sourced from existing datasets.
2. **Image Annotation:** Use annotation tools (such as LabelImg or VGG Image Annotator) to label the objects in the images with bounding boxes and category labels.
#### Data Preprocessing
Data preprocessing is essential before training the model to enhance performance. YOLOv8 supports the following data preprocessing techniques:
1. **Image Adjustments:** Resize, crop, and flip images to increase the diversity of the dataset.
2. **Color Jittering:** Randomly alter the brightness, contrast, saturation, and hue of images to improve the model's robustness to lighting variations.
3. **Mosaic Data Augmentation:** Combine four images into a single mosaic image to enhance contextual information of the targets.
**3.2 Model Training and Evaluation**
#### Model Training
YOLOv8 is trained using the PyTorch framework. The training process includes the following steps:
1. **Initialize Model:** Load pre-trained model weights or initialize model weights from scratch.
2. **Define Loss Function:** Use a combination of cross-entropy loss and bounding box regression loss as the loss function.
3. **Optimizer Selection:** Use optimizers such as Adam or SGD to update model weights.
4. **Training Loop:** Feed data batches into the model, compute loss, and update model weights.
#### Model Evaluation
Throughout the training process, regular evaluation of the model's performance is necessary to track progress and make adjustments. YOLOv8 supports the following evaluation metrics:
1. **Mean Average Precision (mAP):** Measures the accuracy and recall of the model's object detection.
2. **Loss Function:** The descent of the loss function during training reflects the model's convergence.
3. **Training Time:** Record the time required to train the model to optimize the training process.
**3.3 Model Deployment and Inference**
#### Model Deployment
The trained YOLOv8 model can be deployed on various platforms, including servers, embedded devices, and mobile devices. The deployment process involves:
1. **Export Model:** Export the trained model into formats such as ONNX, TensorFlow Lite, or Core ML.
2. **Optimize Model:** Optimize the model size and inference speed using techniques like quantization, pruning, and distillation.
#### Model Inference
The deployed model can be used for real-time object detection. The inference process includes:
1. **Load Model:** Load the exported model into the inference engine.
2. **Preprocess Image:** Preprocess the input image, such as resizing and color jittering.
3. **Object Detection:** Feed the preprocessed image into the model and obtain the bounding boxes and category labels of the objects.
4. **Postprocessing:** Perform postprocessing on the detection results, such as Non-Maximum Suppression (NMS) and confidence thresholding.
**4. Optimizations and Enhancements for YOLOv8**
### 4.1 Model Compression and Acceleration
**Model Compression**
Model compression aims to reduce the size of the model while maintaining its accuracy. This is crucial for models deployed on embedded or mobile devices. YOLOv8 provides various model compression techniques, including:
- **Knowledge Distillation:** Transfer the knowledge from a large teacher model to a smaller student model.
- **Pruning:** Remove weights and neurons that have a minimal impact on model accuracy.
- **Quantization:** Convert floating-point weights and activations to lower-precision formats, such as int8 or int16.
**Model Acceleration**
Model acceleration aims to improve the model's inference speed, which is vital for real-time applications. YOLOv8 provides the following acceleration techniques:
- **Lightweight Network Architecture:** Use fewer layers and smaller convolution kernels to reduce computation.
- **Depthwise Separable Convolution:** Decompose depthwise convolution into depthwise and pointwise convolutions to reduce the number of parameters.
- **MobileNetV3 Blocks:** Utilize Inverted Residual blocks for higher computational efficiency.
**Example Code:**
```python
import tensorflow as tf
# Load the pre-trained YOLOv8 model
model = tf.keras.models.load_model("yolov8.h5")
# Quantize the model to int8 using quantization tools
quantized_model = tf.quantization.quantize_model(model)
# Evaluate the quantized model
loss, accuracy = quantized_model.evaluate(test_dataset)
print("Loss of the quantized model:", loss)
print("Accuracy of the quantized model:", accuracy)
```
### 4.2 Enhancing Model Robustness and Generalizability
**Model Robustness**
Model robustness refers to a model's resistance to noise, distortion, and changes. To enhance the robustness of YOLOv8, the following techniques are employed:
- **Data Augmentation:** Enrich training data using techniques like random cropping, flipping, and color jittering.
- **Adversarial Training:** Train the model using adversarial examples to make it more robust to attacks.
- **Regularization:** Use L1 and L2 regularization to prevent overfitting.
**Model Generalizability**
Model generalizability refers to the performance of a model across different datasets and scenarios. To improve the generalizability of YOLOv8, the following techniques are utilized:
- **Multi-task Learning:** Train the model to perform multiple tasks simultaneously, such as object detection and semantic segmentation.
- **Transfer Learning:** Use models pre-trained on large datasets as the initialization weights for YOLOv8.
- **Adaptive Learning:** Utilize adaptive learning rates and optimizers to adjust the training process.
**Example Code:**
```python
import tensorflow as tf
# Load the pre-trained YOLOv8 model
model = tf.keras.models.load_model("yolov8.h5")
# Use adversarial training to enhance model robustness
adversarial_training = tf.keras.callbacks.AdversarialTraining(
epsilon=0.1,
num_iterations=10
)
# Train the model
model.fit(train_dataset, epochs=10, callbacks=[adversarial_training])
```
### 4.3 Customization for Specific Scenarios
YOLOv8 can be customized for specific scenarios to improve performance, achieved through the following methods:
- **Change the Backbone Network:** Use different backbone networks, such as ResNet or EfficientNet, to meet various accuracy and speed requirements.
- **Adjust Hyperparameters:** Modify training hyperparameters, such as learning rate, batch size, and optimizer, to optimize model performance.
- **Add Custom Layers:** Add custom layers, like Spatial Pyramid Pooling (SPP) or attention mechanisms, to enhance the model's feature extraction capabilities.
**Example Code:**
```python
import tensorflow as tf
# Load the pre-trained YOLOv8 model
model = tf.keras.models.load_model("yolov8.h5")
# Replace the backbone network with EfficientNet
model.layers[0] = tf.keras.applications.EfficientNetB0(
include_top=False,
input_shape=(416, 416, 3)
)
# ***
***pile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001))
# Train the model
model.fit(train_dataset, epochs=10)
```
**5.1 Continuous Algorithm Improvement**
As an evolving algorithm, YOLOv8's future development focuses on the following aspects:
- **Accuracy Improvement:** Further enhance the detection accuracy of the algorithm by optimizing the network structure, introducing new activation functions, and regularization techniques.
- **Speed Optimization:** Explore lightweight network design, model pruning, and quantization to improve the algorithm's inference speed, making it suitable for real-time applications.
- **Robustness Enhancement:** Strengthen the algorithm's robustness against noise, occlusion, and changes in lighting, ensuring stable performance in complex environments.
- **Generalizability Improvement:** Improve the algorithm's generalization across different datasets and scenarios using data augmentation techniques, multi-task learning, and transfer learning.
**5.2 Expansion of Application Scenarios**
YOLOv8 has a wide range of application prospects in the field of object detection, with future scenarios continually expanding, including:
- **Intelligent Security:** Used for monitoring videos to detect people, vehicles, and objects, enabling anomaly detection and security alerts.
- **Autonomous Driving:** As part of the perception system, detecting pedestrians, vehicles, and obstacles on the road, assisting vehicle decision-making and safe driving.
- **Medical Imaging:** Used for detecting and classifying lesions in medical images, aiding doctors in diagnosis and treatment.
- **Industrial Inspection:** Used to detect defective products and anomalies on production lines, enhancing production efficiency and product quality.
- **Retail:** Used for store traffic analysis, product recognition, and inventory management, optimizing store operations and improving customer experience.
**5.3 Integration with Other Technical Fields**
YOLOv8 has the potential to integrate with other technical fields, with breakthroughs expected in the following areas:
- **Edge Computing:** Combined with edge computing devices to achieve low-latency, low-power object detection, suitable for resource-constrained scenarios such as IoT and mobile devices.
- **Cloud Computing:** Integrated with cloud computing platforms to leverage powerful computing and storage resources for training and inference on large-scale datasets.
- **Artificial Intelligence:** Combined with other fields of AI, such as Natural Language Processing and Knowledge Graphs, to build smarter and more comprehensive solutions.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【R语言Capet包集成挑战】:解决数据包兼容性问题与优化集成流程
# 1. R语言Capet包集成概述
随着数据分析需求的日益增长,R语言作为数据分析领域的重要工具,不断地演化和扩展其生态系统。Capet包作为R语言的一个新兴扩展,极大地增强了R在数据处理和分析方面的能力。本章将对Capet包的基本概念、功能特点以及它在R语言集成中的作用进行概述,帮助读者初步理解Capet包及其在
【多层关联规则挖掘】:arules包的高级主题与策略指南
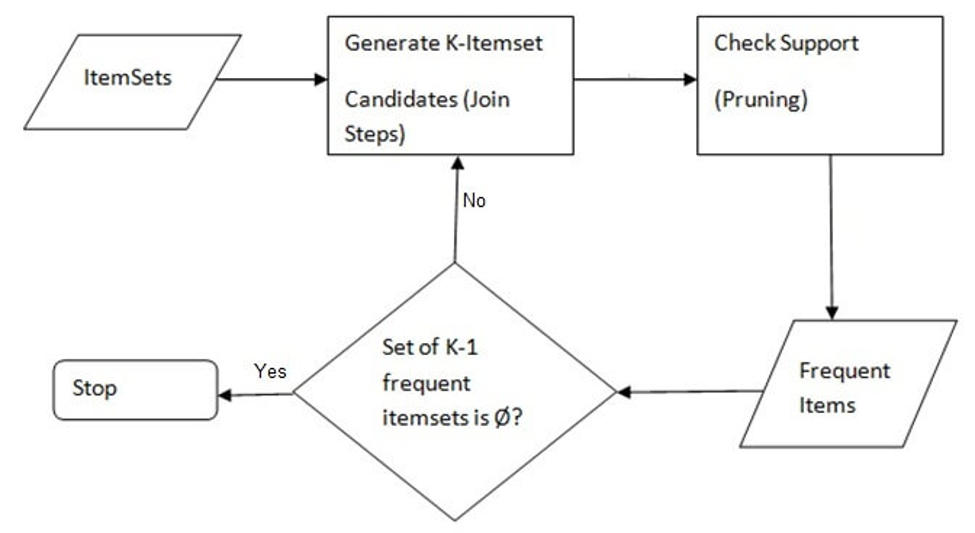
# 1. 多层关联规则挖掘的理论基础
关联规则挖掘是数据挖掘领域中的一项重要技术,它用于发现大量数据项之间有趣的关系或关联性。多层关联规则挖掘,在传统的单层关联规则基础上进行了扩展,允许在不同概念层级上发现关联规则,从而提供了更多维度的信息解释。本章将首先介绍关联规则挖掘的基本概念,包括支持度、置信度、提升度等关键术语,并进一步阐述多层关联规则挖掘的理论基础和其在数据挖掘中的作用。
## 1.1 关联规则挖掘
时间数据统一:R语言lubridate包在格式化中的应用

# 1. 时间数据处理的挑战与需求
在数据分析、数据挖掘、以及商业智能领域,时间数据处理是一个常见而复杂的任务。时间数据通常包含日期、时间、时区等多个维度,这使得准确、高效地处理时间数据显得尤为重要。当前,时间数据处理面临的主要挑战包括但不限于:不同时间格式的解析、时区的准确转换、时间序列的计算、以及时间数据的准确可视化展示。
为应对这些挑战,数据处理工作需要满足以下需求:
【R语言caret包多分类处理】:One-vs-Rest与One-vs-One策略的实施指南
# 1. R语言与caret包基础概述
R语言作为统计编程领域的重要工具,拥有强大的数据处理和可视化能力,特别适合于数据分析和机器学习任务。本章节首先介绍R语言的基本语法和特点,重点强调其在统计建模和数据挖掘方面的能力。
## 1.1 R语言简介
R语言是一种解释型、交互式的高级统计分析语言。它的核心优势在于丰富的统计包
机器学习数据准备:R语言DWwR包的应用教程

# 1. 机器学习数据准备概述
在机器学习项目的生命周期中,数据准备阶段的重要性不言而喻。机器学习模型的性能在很大程度上取决于数据的质量与相关性。本章节将从数据准备的基础知识谈起,为读者揭示这一过程中的关键步骤和最佳实践。
## 1.1 数据准备的重要性
数据准备是机器学习的第一步,也是至关重要的一步。在这一阶
dplyr包函数详解:R语言数据操作的利器与高级技术

# 1. dplyr包概述
在现代数据分析中,R语言的`dplyr`包已经成为处理和操作表格数据的首选工具。`dplyr`提供了简单而强大的语义化函数,这些函数不仅易于学习,而且执行速度快,非常适合于复杂的数据操作。通过`dplyr`,我们能够高效地执行筛选、排序、汇总、分组和变量变换等任务,使得数据分析流程变得更为清晰和高效。
在本章中,我们将概述`dplyr`包的基
R语言中的概率图模型:使用BayesTree包进行图模型构建(图模型构建入门)

# 1. 概率图模型基础与R语言入门
## 1.1 R语言简介
R语言作为数据分析领域的重要工具,具备丰富的统计分析、图形表示功能。它是一种开源的、以数据操作、分析和展示为强项的编程语言,非常适合进行概率图模型的研究与应用。
```r
# 安装R语言基础包
install.packages("stats")
```
## 1.2 概率图模型简介
概率图模型(Probabi
【R语言数据包mlr的深度学习入门】:构建神经网络模型的创新途径

# 1. R语言和mlr包的简介
## 简述R语言
R语言是一种用于统计分析和图形表示的编程语言,广泛应用于数据分析、机器学习、数据挖掘等领域。由于其灵活性和强大的社区支持,R已经成为数据科学家和统计学家不可或缺的工具之一。
## mlr包的引入
mlr是R语言中的一个高性能的机器学习包,它提供了一个统一的接口来使用各种机器学习算法。这极大地简化了模型的选择、训练
R语言文本挖掘实战:社交媒体数据分析

# 1. R语言与文本挖掘简介
在当今信息爆炸的时代,数据成为了企业和社会决策的关键。文本作为数据的一种形式,其背后隐藏的深层含义和模式需要通过文本挖掘技术来挖掘。R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境,它在文本挖掘领域展现出了强大的功能和灵活性。文本挖掘,简而言之,是利用各种计算技术从大量的
R语言e1071包处理不平衡数据集:重采样与权重调整,优化模型训练

# 1. 不平衡数据集的挑战和处理方法
在数据驱动的机器学习应用中,不平衡数据集是一个常见而具有挑战性的问题。不平衡数据指的是类别分布不均衡,一个或多个类别的样本数量远超过其他类别。这种不均衡往往会导致机器学习模型在预测时偏向于多数类,从而忽视少数类,造成性能下降。
为了应对这种挑战,研究人员开发了多种处理不平衡数据集的方法,如数据层面的重采样、在算法层面使用不同
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )