虚拟化中的链式存储:提升性能和灵活性
发布时间: 2024-08-25 16:54:32 阅读量: 29 订阅数: 26 
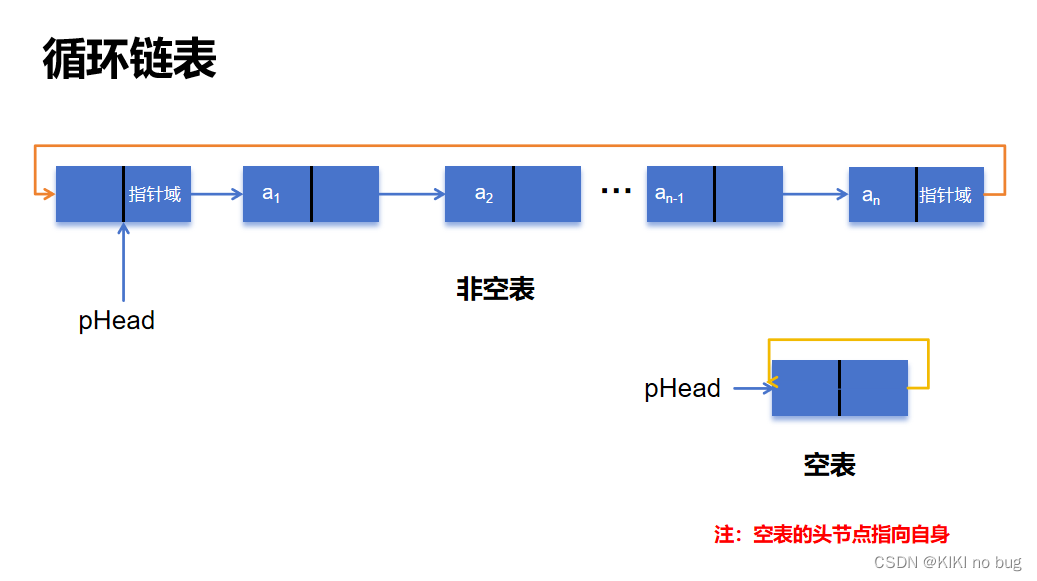
# 1. 虚拟化中的链式存储概述
链式存储是一种虚拟化存储技术,它将多个物理存储设备聚合为一个逻辑存储池。这种技术允许管理员将存储资源视为一个统一的实体,从而简化存储管理并提高资源利用率。
链式存储通过将数据块链接在一起形成链条来实现数据存储。每个数据块都有一个指向下一个块的指针,形成一个连续的数据流。这种存储方式消除了传统存储系统中常见的碎片化问题,并提高了数据访问性能。
链式存储还提供了高级数据管理功能,例如动态卷扩展、存储池的无缝扩展以及数据重复删除和压缩。这些功能使管理员能够灵活地管理存储资源,并最大限度地提高存储效率。
# 2. 链式存储的理论基础
### 2.1 存储池和卷管理
**存储池**
存储池是链式存储系统中管理物理存储资源的基本单位,它将一组物理存储设备(如硬盘、SSD)聚合为一个逻辑单元。存储池提供了一个统一的存储空间,允许管理员轻松地分配和管理存储资源。
**卷管理**
卷是存储池中创建的逻辑存储单元,它为操作系统和应用程序提供存储空间。卷可以是固定大小的(预分配)或动态扩展的(按需分配)。卷管理涉及创建、删除、扩展和配置卷,以满足特定的存储需求。
### 2.2 数据块寻址和分配
**数据块寻址**
链式存储系统使用逻辑块寻址(LBA)机制来访问数据。LBA将物理存储设备上的数据块映射到一个连续的逻辑地址空间。这使得应用程序和操作系统可以以一致的方式访问数据,而无需了解底层存储设备的物理布局。
**数据块分配**
当数据写入链式存储系统时,它会被分配到存储池中的可用数据块中。数据块分配算法决定了如何选择和分配数据块,以优化性能和空间利用率。常见的分配算法包括:
- **连续分配:**数据块按顺序分配,以提高顺序读写性能。
- **条带化分配:**数据块跨多个物理存储设备分配,以提高并行读写性能。
- **镜像分配:**数据块在多个物理存储设备上创建副本,以提高数据冗余和可用性。
### 2.3 数据保护和恢复
**数据保护**
链式存储系统提供多种数据保护机制,以防止数据丢失或损坏。这些机制包括:
- **RAID(冗余阵列独立磁盘):**RAID使用数据冗余技术来保护数据,即使一个或多个物理存储设备发生故障。
- **快照:**快照是数据在特定时间点的只读副本,它允许在数据损坏或意外删除时恢复数据。
- **克隆:**克隆是现有卷的完全副本,它允许快速创建新卷,而无需复制数据。
**数据恢复**
如果数据丢失或损坏,链式存储系统提供各种数据恢复选项。这些选项包括:
- **RAID重建:**当一个RAID组中的物理存储设备发生故障时,RAID系统会自动重建故障设备上的数据。
- **快照恢复:**如果数据损坏或删除,可以从快照中恢复数据。
- **克隆恢复:**如果一个卷损坏或丢失,可以从其克隆中恢复数据。
# 3.1 性能优化技术
#### 3.1.1 条带化和缓存
**条带化**
条带化是一种数据分布技术,它将数据块跨越多个物理磁盘进行存储。这样做可以提高读取和写入性能,因为多个磁盘可以同时访问数据。
**缓存**
缓存是一种高速存储设备,用于存储经常访问的数据。当数据从存储池中读取时,它将被复制到缓存中。下次需要该数据时,它可以从缓存中快速读取,而无需访问存储池。
#### 3.1.2 分层存储
分层存储是一种将数据存储在不同类型的存储介质中的技术。例如,经常访问的数据可以存储在固态硬盘(SSD)中,而较少访问的数据可以存储在机械硬盘(HDD)中。这样做可以优化性能和成本,因为 SSD 比 HDD 更快,但成本也更高。
**代码块:**
```python
import os
# 创建一个条带化文件系统
os.mkfs.ext4 -O stripe=64 /dev/sdc
# 创建一个缓存文件系统
os.mkfs.ext4 -O cache=writeback /dev/sdd
# 创建一个分层存储文件系统
os.mkfs.ext4 -O tiered=auto /dev/sde
```
**逻辑分析:**
* `os.mkfs.ext4 -O stripe=64 /dev/sdc`:使用 64KB 的条带大小创建条带化文件系统。
* `os.mkfs.ext4 -O cache=writeback /dev/sdd`:使用回写缓存策略创建缓存文件系统。
* `os.mkfs.ext4 -O tiered=auto /dev/sde`:创建具有自动分层策略的分层存储文件系统。
**参数说明:**
* `stripe`:条带大小(以 KB 为单位)。
* `cache`:缓存策略(可以是 writeback、writethrough 或 none)。
* `tiered`:分层策略(可以是 auto、performance 或 capacity)。
# 4. 链式存储的进阶技术
### 4.1 数据重复删除和压缩
#### 4.1.1 重复删除原理
数据重复删除是一种技术,它通过识别和消除数据中的重复副本,从而减少存储空间的占用。链式存储系统通常使用基于块的重复删除算法,该算法将数据块与存储池中的其他块进行比较,如果找到匹配项,则只保留一个副本。
#### 4.1.2 压缩算法和应用
数据压缩是一种技术,它通过减少数据的大小来节省存储空间。链式存储系统通常支持多种压缩算法,包括:
- **无损压缩:**保留原始数据的完整性,例如 LZ4、Zlib
- **有损压缩:**可以丢失一些数据,但通常对应用程序的影响很小,例如 JPEG、MPEG
压缩算法的选择取决于数据类型和所需的压缩率。例如,对于文本文件,无损压缩算法可以提供较高的压缩率,而对于图像和视频文件,有损压缩算法可以提供更好的压缩率。
### 4.2 快照和克隆
#### 4.2.1 快照的创建和管理
快照是数据卷在特定时间点的只读副本。链式存储系统允许快速创建和管理快照,这对于数据保护和恢复非常有用。创建快照不会消耗额外的存储空间,因为它们只是指向原始数据块的引用。
#### 4.2.2 克隆的创建和用途
克隆是数据卷的可写副本。链式存储系统允许快速创建和管理克隆,这对于测试、开发和部署新应用程序非常有用。克隆与原始卷共享相同的数据块,因此创建克隆不会消耗额外的存储空间。
### 代码示例
以下代码块展示了如何在链式存储系统中创建快照:
```python
import pyVmomi
# 连接到 vCenter Server
vcenter_ip = "10.10.10.10"
vcenter_username = "administrator"
vcenter_password = "password"
vcenter = pyVmomi.vcenter.Vcenter(vcenter_ip, vcenter_username, vcenter_password)
# 获取数据卷
datastore = vcenter.find_datastore("datastore1")
volume = datastore.find_volume("volume1")
# 创建快照
snapshot = volume.create_snapshot("snapshot1")
```
以下 mermaid 流程图展示了创建克隆的过程:
```mermaid
sequenceDiagram
participant User
participant Storage System
User->Storage System: Create clone request
Storage System->Storage System: Copy data blocks from source volume
Storage System->Storage System: Create new volume
Storage System->User: Clone created
```
### 表格
下表总结了链式存储的进阶技术及其优点:
| 技术 | 优点 |
|---|---|
| 数据重复删除 | 减少存储空间占用 |
| 数据压缩 | 减少存储空间占用 |
| 快照 | 数据保护和恢复 |
| 克隆 | 测试、开发和部署 |
# 5. 链式存储的未来发展
随着技术的发展,链式存储也在不断演进,出现了许多新的技术和趋势。
### 5.1 软件定义存储(SDS)
软件定义存储(SDS)是一种将存储软件与底层硬件分离开来的架构。它允许管理员使用软件来管理存储资源,而无需依赖于特定硬件供应商。SDS 提供了更大的灵活性、可扩展性和成本效益。
### 5.2 超融合基础设施(HCI)
超融合基础设施(HCI)将计算、存储和网络功能集成到一个单一的设备中。HCI 简化了部署和管理,并提供了更高的性能和效率。
### 5.3 云原生存储
云原生存储是专门为云环境设计的存储解决方案。它提供了按需扩展、高可用性和弹性。云原生存储使组织能够轻松地扩展其存储容量,以满足不断变化的业务需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“链式存储的基本概念与应用实战”专栏深入探讨了链式存储技术在各个领域的广泛应用。它揭示了链式存储在文件系统、数据库、虚拟化、数据保护、容量管理、故障排除、云计算、人工智能和医疗保健等领域的秘密武器,阐述了如何利用链式存储优化存储和查询效率、提升性能和灵活性、保障数据安全和业务连续性、优化存储空间和成本、快速诊断和解决常见问题、实现弹性、可扩展和高可用、加速数据处理和模型训练,以及优化患者数据管理和提高医疗质量。该专栏为读者提供了全面且实用的见解,帮助他们了解和应用链式存储技术以实现其存储和数据管理目标。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32F103VET6 PCB布局艺术:高速信号处理的秘密
参考资源链接:[STM32F103VET6 PCB原理详解:最小系统板与电路布局](https://wenku.csdn.net/doc/6412b795be7fbd1778d4ad36?spm=1055.2635.3001.10343)
# 1. STM32F103VET6微控制器简介
STM32F103VET6是STMicroelectronics公司生产的一款基于ARM Cortex-M3内核的高性能微控制器(MCU),
【PFC5.0项目案例分析】:专家分享如何在实际工作中有效运用

参考资源链接:[PFC5.0用户手册:入门与教程](https://wenku.csdn.net/doc/557hjg39sn?spm=1055.2635.3001.10343)
# 1. PFC5.0项目概览
PFC5.0项目是一套先进的项目管理与团队协作平台,旨在提供端到端的解决方案,以满足现代企业在项目规划、风险控制、团队协作等方面的复杂需求。本章节将首先介绍PFC5.0的整体架
磁盘SMART指标解析:监控硬盘健康状态
参考资源链接:[硬盘SMART错误警告解决办法与诊断技巧](https://wenku.csdn.net/doc/7cskgjiy20?spm=1055.2635.3001.10343)
# 1. 磁盘SMART技术概述
在信息技术迅猛发展的今天,数据存储设备的可靠性直接关联到企业的运营效率和数据安全。**SMART技术**(Self-Monitoring, Analysis and Reporting Technology,自监测分析报告技术)是硬盘制造行业中的一个标准功能,它能够在硬盘出现故障前进行早期预警,从而减少数据丢失的风险。
磁盘SMART技术为管理员提供了一种监控硬盘健康状态
【ASP.NET Core Web API设计】:构建RESTful服务的最佳实践

参考资源链接:[ASP.NET实用开发:课后习题详解与答案](https://wenku.csdn.net/doc/649e3a1550e8173efdb59dbe?spm=1055.2635.3001.10343)
# 1. ASP.NET
WINCC与操作系统版本兼容性:专家分析与实用指南
参考资源链接:[Windows XP下安装WINCC V6.0/V6.2错误解决方案](https://wenku.csdn.net/doc/6412b6dcbe7fbd1778d483df?spm=1055.2635.3001.10343)
# 1. WinCC与操作系统兼容性的基础了解
## 1.1 软件与操作系统兼容性的重要性
在工业自动化领域,Win
iSecure Center自动化监控:API使用与数据集成实战指南
参考资源链接:[iSecure Center 安装指南:综合安防管理平台部署步骤](https://wenku.csdn.net/doc/2f6bn25sjv?spm=1055.2635.3001.10343)
# 1. iSecure Center自动化监控概述
在当前信息技术迅速发展的背景下,企业对于自动化监控的需求越来越迫切。iS
电动汽车充电效率提升:SAE J1772标准实施难点的解决方案

参考资源链接:[SAE J1772-2017.pdf](https://wenku.csdn.net/doc/6412b74abe7fbd1778d
【高级控制算法】:提高FANUC 0i-MF系统精度的算法优化,技术解析
参考资源链接:[FANUC 0i-MF 加工中心系统操作与安全指南](https://wenku.csdn.net/doc/6401ac08cce7214c316ea60a?spm=1055.2635.3001.10343)
# 1. ```
# 第一章:FANUC 0i-MF系统与控制算法概述
FANUC 0i-MF系统作为现代工业自动化领域的重要组成部分,以其卓越的控制性能和可靠性在数控机床等领域得到广泛应用。本章将从系统架构、控制算法类型
Strmix Simplis安装配置:最佳实践指南,避免仿真软件的坑

参考资源链接:[Simetrix/Simplis仿真教程:从基础到进阶](https://wenku.csdn.net/doc/t5vdt9168s?spm=1055.2635.3001.10343)
# 1. Strmix Simplis软件介绍与安装前准备
Strmix Sim
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )