链式存储VS传统存储:优势、劣势和适用场景大揭秘
发布时间: 2024-08-25 16:56:46 阅读量: 54 订阅数: 26 
# 1. 存储技术概述**
存储技术是计算机系统中至关重要的组成部分,负责数据的持久化和访问。随着数据量的不断增长,存储技术也在不断发展,以满足不断变化的需求。
存储技术主要分为两类:链式存储和传统存储。链式存储基于分布式系统原理,将数据分散存储在多个节点上,实现高可用性和可扩展性。传统存储则基于集中式系统原理,将数据集中存储在单个设备或服务器上,具有较高的性能和安全性。
# 2. 链式存储的理论基础
### 2.1 分布式哈希表(DHT)
分布式哈希表(DHT)是一种分布式数据结构,它将键值对存储在分布式网络中的节点上。每个节点负责存储一部分键值对,并且可以通过哈希函数将键映射到相应的节点。DHT 的主要优点是它可以将数据分布在多个节点上,从而提高了系统的可扩展性和容错性。
**代码块:**
```python
import hashlib
class DHT:
def __init__(self, num_nodes):
self.num_nodes = num_nodes
self.nodes = [{} for _ in range(num_nodes)]
def hash(self, key):
return int(hashlib.sha256(key.encode()).hexdigest(), 16) % self.num_nodes
def get(self, key):
node_id = self.hash(key)
return self.nodes[node_id].get(key)
def put(self, key, value):
node_id = self.hash(key)
self.nodes[node_id][key] = value
```
**逻辑分析:**
该代码块实现了分布式哈希表。它使用 SHA-256 哈希函数将键映射到 0 到 `num_nodes - 1` 之间的节点 ID。`get()` 方法用于从 DHT 中获取值,`put()` 方法用于将键值对存储在 DHT 中。
### 2.2 一致性哈希算法
一致性哈希算法是一种哈希算法,它可以确保在节点加入或离开网络时,数据的分布保持一致。一致性哈希算法使用一个虚拟环,每个节点在环上占据一个位置。当一个键被哈希时,它会被映射到环上的一个位置,该位置负责存储该键。
**代码块:**
```python
import hashlib
class ConsistentHashing:
def __init__(self, num_nodes):
self.num_nodes = num_nodes
self.ring = [None] * num_nodes
def hash(self, key):
return int(hashlib.sha256(key.encode()).hexdigest(), 16)
def get_node(self, key):
node_id = self.hash(key) % self.num_nodes
while self.ring[node_id] is None:
node_id = (node_id + 1) % self.num_nodes
return self.ring[node_id]
def add_node(self, node):
node_id = self.hash(node) % self.num_nodes
self.ring[node_id] = node
def remove_node(self, node):
node_id = self.hash(node) % self.num_nodes
self.ring[node_id] = None
```
**逻辑分析:**
该代码块实现了基于虚拟环的一致性哈希算法。它使用 SHA-256 哈希函数将键映射到 0 到 `num_nodes - 1` 之间的虚拟环位置。`get_node()` 方法用于从一致性哈希表中获取节点,`add_node()` 方法用于将节点添加到一致性哈希表中,`remove_node()` 方法用于从一致性哈希表中删除节点。
### 2.3 数据分片和复制
数据分片和复制是链式存储中常用的技术,它们可以提高系统的性能和可靠性。数据分片将数据分成较小的块,并将其存储在不同的节点上。数据复制将数据复制到多个节点上,以防止数据丢失。
**表格:**
| 分片和复制 | 优点 | 缺点 |
|---|---|---|
| 分片 | 提高性能 | 增加存储开销 |
| 复制 | 提高可靠性 | 增加存储开销和网络开销 |
**代码块:**
```python
import random
class DataSharding:
def __init__(self, num_shards):
self.num_shards = num_shards
self.shards = [[] for _ in range(num_shards)]
def shard(self, key):
return random.randint(0, self.num_shards - 1)
def get(self, key):
shard_id = self.shard(key)
return self.shards[shard_id].get(key)
def put(self, key, value):
shard_id = self.shard(key)
self.shards[shard_id][key] = value
```
**逻辑分析:**
该代码块实现了数据分片。它使用随机函数将键映射到 0 到 `num_shards - 1` 之间的分片 ID。`get()` 方法用于从分片存储中获取值,`put()` 方法用于将键值对存储在分片存储中。
**mermaid 流程图:**
```mermaid
graph LR
subgraph 数据分片
A[数据] --> B[分片]
B[分片] --> C[节点 1]
B[分片] --> D[节点 2]
B[分片] --> E[节点 3]
end
subgraph 数据复制
F[数据] --> G[副本 1]
F[数据] --> H[副本 2]
F[数据] --> I[副本 3]
end
```
**流程图分析:**
该流程图展示了数据分片和复制的过程。数据分片将数据分成较小的块,并将其存储在不同的节点上。数据复制将数据复制到多个节点上,以防止数据丢失。
# 3. 链式存储的实践应用**
链式存储技术在实际应用中展现出强大的优势,广泛应用于对象存储服务、分布式数据库和内容分发网络(CDN)等领域。
### 3.1 对象存储服务
对象存储服务(OSS)是一种基于链式存储技术构建的云存储服务,提供海量、低成本、高可靠的数据存储能力。OSS将数据对象存储在分布式集群中,通过一致性哈希算法将数据对象映射到不同的存储节点上。
**优势:**
- **海量存储:**支持存储PB级甚至EB级的数据,满足大规模数据存储需求。
- **低成本:**采用分布式架构,无需昂贵的硬件设备,降低存储成本。
- **高可靠性:**数据多副本存储,即使部分节点故障,也能保证数据安全。
**应用场景:**
- 大数据分析
- 媒体文件存储
- 备份和归档
**代码示例:**
```python
import boto3
# 创建一个 S3 客户端
s3 = boto3.client('s3')
# 创建一个存储桶
bucket_name = 'my-bucket'
s3.create_bucket(Bucket=bucket_name)
# 上传一个文件到存储桶
file_name = 'my-file.txt'
s3.upload_file(file_name, bucket_name, file_name)
# 获取存储桶中的文件列表
for obj in s3.list_objects(Bucket=bucket_name):
print(obj['Key'])
```
**逻辑分析:**
该代码示例演示了如何使用 boto3 库连接到 Amazon S3 对象存储服务,创建存储桶、上传文件并获取文件列表。
### 3.2 分布式数据库
分布式数据库采用链式存储技术,将数据分布在多个节点上,实现高并发、高可用和可扩展性。
**优势:**
- **高并发:**多个节点同时处理请求,提升数据库处理能力。
- **高可用:**节点故障不影响数据库可用性,保证数据安全。
- **可扩展性:**通过增加或减少节点,灵活扩展数据库容量。
**应用场景:**
- 电子商务
- 社交网络
- 金融交易
**代码示例:**
```java
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
public class DistributedDatabaseExample {
public static void main(String[] args) {
// 创建 Spanner 客户端
Spanner spanner = SpannerOptions.getDefaultInstance().getService();
// 创建数据库客户端
DatabaseClient dbClient = spanner.getDatabaseClient(DatabaseId.of("my-project", "my-instance", "my-database"));
// 执行查询
Statement selectStatement = Statement.of("SELECT * FROM Singers");
ResultSet resultSet = dbClient.singleUse().executeQuery(selectStatement);
// 遍历结果集
while (resultSet.next()) {
System.out.println(resultSet.getLong("SingerId") + ": " + resultSet.getString("FirstName") + " " + resultSet.getString("LastName"));
}
}
}
```
**逻辑分析:**
该代码示例演示了如何使用 Google Cloud Spanner API 连接到分布式数据库,执行查询并获取结果集。
### 3.3 内容分发网络(CDN)
CDN 利用链式存储技术,将内容缓存到分布在全球各地的边缘节点上,实现快速、低延迟的内容分发。
**优势:**
- **快速分发:**内容缓存到边缘节点,减少访问延迟,提升用户体验。
- **低成本:**CDN 分担了网站的流量,降低服务器负载,节省带宽成本。
- **高可用性:**边缘节点分布广泛,即使部分节点故障,也能保证内容可访问。
**应用场景:**
- 视频流媒体
- 游戏下载
- 网站加速
**代码示例:**
```xml
<configuration>
<defaultCDN>my-cdn</defaultCDN>
<CDNs>
<CDN id="my-cdn">
<origin>https://my-origin.com</origin>
<edgeLocations>
<edgeLocation>us-east-1</edgeLocation>
<edgeLocation>us-west-1</edgeLocation>
<edgeLocation>eu-central-1</edgeLocation>
</edgeLocations>
</CDN>
</CDNs>
</configuration>
```
**逻辑分析:**
该代码示例演示了如何配置 CDN,包括默认 CDN、CDN ID、源站地址和边缘节点位置。
# 4. 传统存储的理论基础
### 4.1 块设备和文件系统
**块设备**
块设备将存储空间划分为固定大小的块,每个块都有一个唯一的地址。操作系统将块设备视为一个线性地址空间,应用程序可以通过读取或写入块地址来访问数据。常见的块设备包括硬盘驱动器(HDD)、固态硬盘(SSD)和光盘驱动器。
**文件系统**
文件系统是一种逻辑结构,它将块设备上的数据组织成层次结构。文件系统为文件和目录提供了一个抽象层,应用程序可以以文件和目录的形式访问数据,而无需了解底层块设备的细节。常见的文件系统包括 ext4、NTFS 和 FAT32。
### 4.2 RAID技术
RAID(Redundant Array of Independent Disks)技术将多个物理磁盘组合成一个逻辑存储单元,以提高数据可靠性和性能。RAID 有多种级别,每种级别提供不同的数据保护和性能特性。
| RAID 级别 | 数据保护 | 性能 |
|---|---|---|
| RAID 0 | 无 | 最高 |
| RAID 1 | 镜像 | 中等 |
| RAID 5 | 奇偶校验 | 中等 |
| RAID 6 | 双奇偶校验 | 低 |
| RAID 10 | 镜像和条带化 | 最高 |
### 4.3 存储虚拟化
存储虚拟化是一种技术,它将物理存储资源抽象化并将其呈现为一个统一的、可管理的存储池。存储虚拟化允许管理员集中管理和分配存储资源,而无需了解底层物理存储设备的详细信息。常见的存储虚拟化解决方案包括 VMware vSAN 和 Microsoft Storage Spaces Direct。
**代码示例:**
```python
import os
# 创建一个文件系统
os.mkfs.ext4("/dev/sda1")
# 挂载文件系统
os.mount("/dev/sda1", "/mnt/data")
# 创建一个 RAID 5 阵列
mdadm --create /dev/md0 --level=5 --raid-devices=4 /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
# 创建一个存储虚拟化池
vsphere-cli storage.pool.create --name=my-pool --type=thin --disk-size=100GB
```
**逻辑分析:**
* `os.mkfs.ext4()` 函数创建了一个 ext4 文件系统。
* `os.mount()` 函数将文件系统挂载到 `/mnt/data` 目录。
* `mdadm` 命令创建了一个 RAID 5 阵列,并将四个物理磁盘添加到阵列中。
* `vsphere-cli` 命令创建了一个 vSphere 存储虚拟化池。
**参数说明:**
* `--level=5`:指定 RAID 级别为 5。
* `--raid-devices=4`:指定 RAID 阵列中包含 4 个物理磁盘。
* `--name=my-pool`:指定存储虚拟化池的名称。
* `--type=thin`:指定存储虚拟化池的类型为精简配置。
* `--disk-size=100GB`:指定存储虚拟化池的大小为 100GB。
# 5. 链式存储与传统存储的对比
### 5.1 优势对比
**可扩展性:**链式存储基于分布式架构,可以轻松地添加或删除节点以满足不断增长的存储需求。传统存储通常受到物理容量的限制,扩展起来更具挑战性。
**高可用性:**链式存储中的数据通常在多个节点上复制,这提供了更高的数据冗余和可用性。如果一个节点发生故障,数据仍然可以从其他节点访问。传统存储通常依赖于 RAID 技术来提供冗余,但这种冗余通常仅限于单个存储设备。
**成本效益:**链式存储可以利用廉价的商用硬件构建,这使其比传统存储更具成本效益。传统存储通常需要专有硬件,这会增加成本。
**灵活性:**链式存储可以轻松地适应不同的存储需求,例如对象存储、块存储和文件存储。传统存储通常针对特定的存储类型进行了优化,这限制了它们的灵活性。
### 5.2 劣势对比
**性能:**链式存储在某些情况下可能比传统存储性能更低,特别是对于需要低延迟访问的应用程序。这是因为链式存储需要在多个节点之间协调数据访问。
**复杂性:**链式存储的分布式架构可能比传统存储更复杂,这需要额外的管理和维护开销。传统存储通常具有更简单的管理界面。
**数据一致性:**链式存储中的数据复制可能会导致数据不一致,特别是当多个节点同时更新数据时。传统存储通常使用更严格的一致性机制,这可以防止数据不一致。
### 5.3 适用场景对比
**链式存储最适合以下场景:**
* 需要高可扩展性和可用性的应用程序
* 需要成本效益的存储解决方案
* 需要灵活的存储解决方案以适应不同的存储需求
**传统存储最适合以下场景:**
* 需要低延迟访问的应用程序
* 需要简单易管理的存储解决方案
* 需要强数据一致性的应用程序
# 6.1 新兴技术趋势
链式存储领域正在不断发展,涌现出许多新兴技术趋势,包括:
- **异构存储:**将不同类型的存储设备(例如 SSD、HDD、NVMe)集成到一个统一的存储系统中,以优化性能和成本。
- **软件定义存储(SDS):**使用软件来管理和配置存储资源,提供更大的灵活性、可扩展性和成本效益。
- **云原生存储:**专门为云计算环境设计的存储解决方案,提供弹性、可扩展性和按需付费模式。
- **边缘计算存储:**在网络边缘部署存储设备,以减少延迟并提高数据可用性。
- **人工智能(AI)驱动的存储:**利用 AI 技术优化存储性能、预测故障并自动化管理任务。
这些趋势正在塑造链式存储的未来,为企业提供更灵活、更具成本效益和更强大的存储解决方案。
## 6.2 挑战与机遇
链式存储的未来发展也面临着一些挑战和机遇:
**挑战:**
- **数据爆炸:**数据量的持续增长给存储系统带来了巨大的压力。
- **安全威胁:**链式存储系统可能面临数据泄露、勒索软件攻击和拒绝服务攻击等安全威胁。
- **监管合规:**企业需要遵守不断变化的数据保护和隐私法规。
**机遇:**
- **云计算的普及:**云计算的增长为链式存储解决方案提供了巨大的市场机会。
- **大数据和分析:**链式存储系统可以支持大数据和分析工作负载,为企业提供宝贵的见解。
- **物联网(IoT):**IoT 设备产生的海量数据需要高效且可扩展的存储解决方案。
通过应对这些挑战和把握机遇,链式存储领域有望继续蓬勃发展,为企业提供满足不断变化的存储需求的创新解决方案。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“链式存储的基本概念与应用实战”专栏深入探讨了链式存储技术在各个领域的广泛应用。它揭示了链式存储在文件系统、数据库、虚拟化、数据保护、容量管理、故障排除、云计算、人工智能和医疗保健等领域的秘密武器,阐述了如何利用链式存储优化存储和查询效率、提升性能和灵活性、保障数据安全和业务连续性、优化存储空间和成本、快速诊断和解决常见问题、实现弹性、可扩展和高可用、加速数据处理和模型训练,以及优化患者数据管理和提高医疗质量。该专栏为读者提供了全面且实用的见解,帮助他们了解和应用链式存储技术以实现其存储和数据管理目标。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【TI杯赛题排错秘笈】:逻辑错误定位与解决终极指南

参考资源链接:[2020年TI杯模拟专题邀请赛赛题-A题单次周期信号再现装置](https://wenku.csdn.net/doc/6459dc3efcc539136824a4c0?spm=1055.2635.3001.10343)
# 1. 逻辑错误的本质与危害
## 1.1 逻辑错误的定义和分类
逻辑错误是指程序运行时没有触发任何异常,但结果却与预期不
系统稳定性与内存安全:确保高可用性系统的内存管理策略

参考资源链接:[Net 内存溢出(System.OutOfMemoryException)的常见情况和处理方式总结](https://wenku.csdn.net/doc/6412b784be7fbd1778d4a95f?spm=1055.2635.3001.10343)
# 1. 内存管理基础与系统稳定性概述
内存管理是操作系统中的一个核心功能,它涉及到内存的分配、使用和回收等多个方面。良好的内存管
【迈普交换机全能手册】:精通基础操作到高级配置的8大必备技能
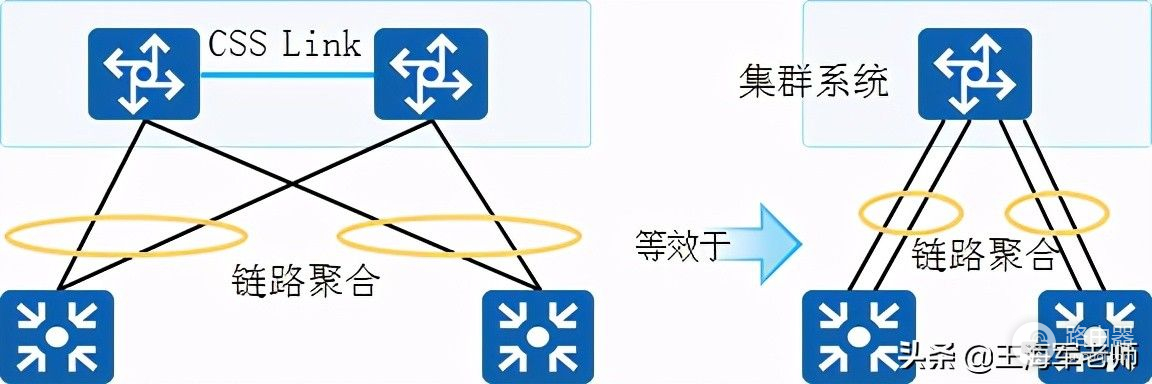
参考资源链接:[迈普交换机命令指南:模式切换与维护操作](https://wenku.csdn.net/doc/6412b79abe7fbd1778d4ae1b?spm=1055.2635.3001.10343)
# 1. 迈普交换机的基础认识与界面概览
迈普交换机作为网络领域的重要设备,是构建稳定网络环境的基石。本章将介绍迈普交换机的基础知识以及用户界面概览,带领读者走进交换机的世界。
## 1.1 交换机的作用与重要性
交换机负责网络
MATLAB Simulink实战应用:如何快速构建第一个仿真项目
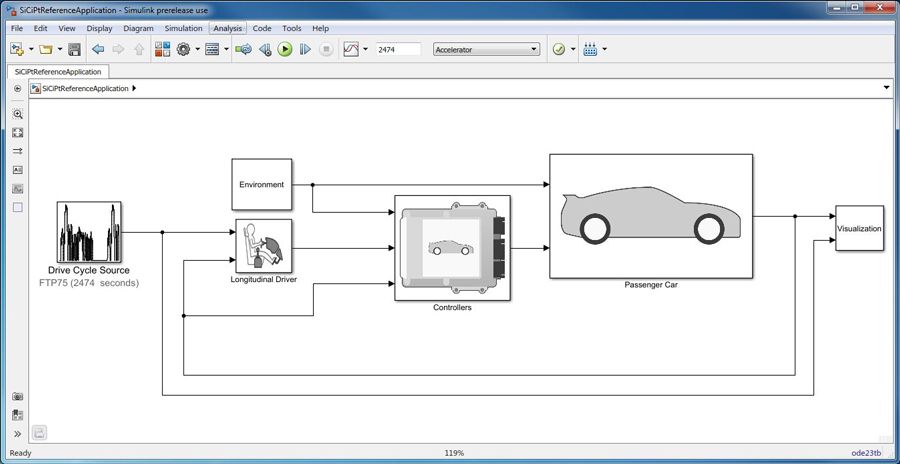
参考资源链接:[Matlab Simulink电力线路模块详解:参数、应用与模型](https://wen
【生物信息学基因数据处理】:Kronecker积的应用探索
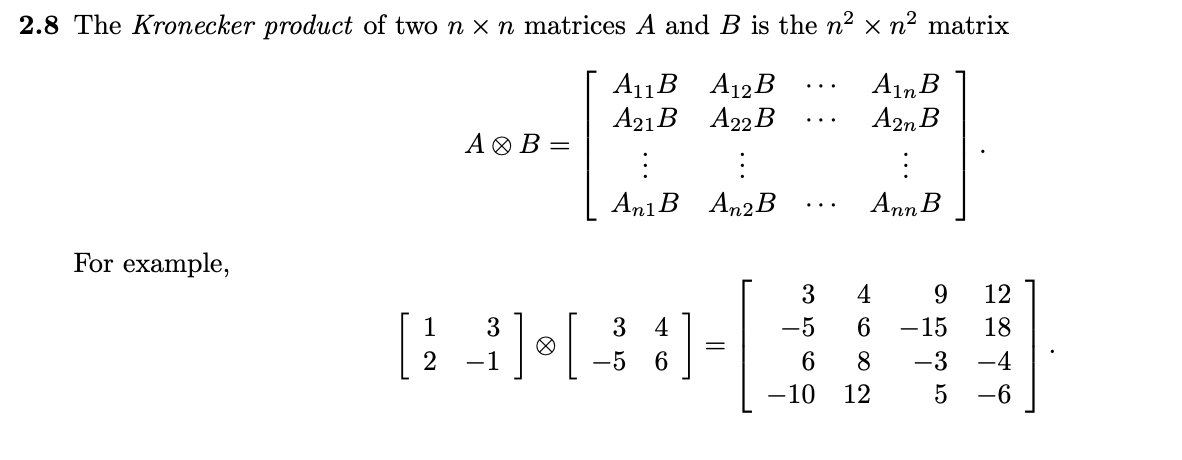
参考资源链接:[矩阵运算:Kronecker积的概念、性质与应用](https://wenku.csdn.net/doc/gja3cts6ed?spm=1055.2635.3001.10343)
# 1. 生物信息学中的Kronecker积概念介绍
## 1.1 Kronecker积的定义
在生物信息学中,Kronecker积(也称为直积)是一种矩阵
【跨平台协作技巧】:在不同EDA工具间实现D触发器设计的有效协作
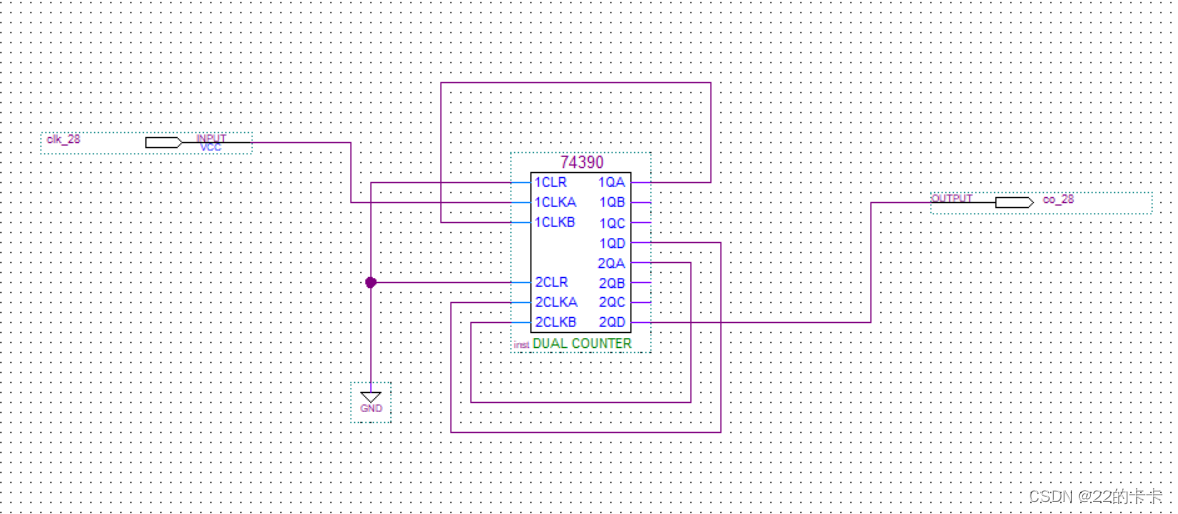
参考资源链接:[Multisim数电仿真:D触发器的功能与应用解析](https://wenku.csdn.net/doc/5wh647dd6h?spm=1055.2635.3001.10343)
# 1. 跨平台EDA工具协作概述
随着集成电路设计复杂性的增加,跨平台电子设计自动化(EDA)工具的协作变得日益重要。本章将概述EDA工具协作的基本概念,以及在现代设计环境中它们如何共同工作。我们将探讨跨平台
【HLW8110物联网桥梁】:构建万物互联的HLW8110应用案例

参考资源链接:[hlw8110.pdf](https://wenku.csdn.net/doc/645d8bd295996c03ac43432a?spm=1055.2635.3001.10343)
# 1. HLW8110物联网桥梁概述
## 1.1 物联网桥梁简介
HL
开发者必看!Codesys功能块加密:应对最大挑战的策略

参考资源链接:[Codesys平台之功能块加密与权限设置](https://wenku.csdn.net/doc/644b7c16ea0840391e559736?spm=1055.2635.3001.10343)
# 1. 功能块加密的基础知识
在现代IT和工业自动化领域,功能块加密已经成为保护知识产权和防止非法复制的重要手段。功能块(Fun
Paraview数据处理与分析流程:中文版完全指南

参考资源链接:[ParaView中文使用手册:从入门到进阶](https://wenku.csdn.net/doc/7okceubkfw?spm=1055.2635.3001.10343)
# 1. Paraview简介与安装配置
## 1.1 Paraview的基本概念
Paraview是一个开源的、跨平台的数据分析和可视化应用程序,广泛应用于科学研究和工程领域。它能够处理各种类型的数据,包括标量、向量、张量等
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )