数据可视化在缺失数据识别中的作用
发布时间: 2024-11-20 04:30:36 阅读量: 89 订阅数: 38 

基于Python实现地震数据可视化.zip
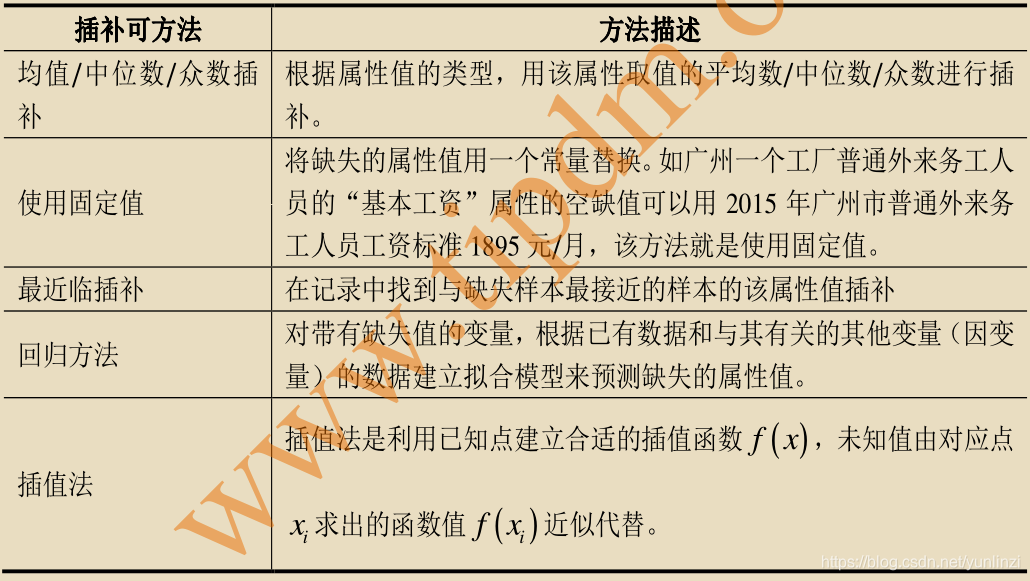
# 1. 数据可视化基础与重要性
在数据科学的世界里,数据可视化是将数据转化为图形和图表的实践过程,使得复杂的数据集可以通过直观的视觉形式来传达信息。它不仅提升了数据理解的深度,还大大增强了决策制定的能力。良好的数据可视化可以揭示模式、趋势和异常点,这些可能是纯数字分析难以捕获的。因此,数据可视化不仅是数据报告的一个重要组成部分,更是现代数据分析不可或缺的一环。
# 2. 缺失数据识别的理论基础
## 2.1 缺失数据的概念与分类
### 2.1.1 缺失数据的定义和类型
缺失数据是指在数据集中,某些观测值未能被记录或丢失的情况。根据缺失数据的性质,可以将其分为三种类型:完全随机缺失(Missing Completely At Random, MCAR)、随机缺失(Missing At Random, MAR)和非随机缺失(Missing Not At Random, MNAR)。
- **完全随机缺失(MCAR)**:数据缺失完全不依赖于任何观测到的或未观测到的数据。例如,问卷调查时可能由于打印机故障导致一些问卷的部分内容无法打印,从而导致数据缺失。
- **随机缺失(MAR)**:数据缺失依赖于观测数据,但不依赖于未观测数据。这种情况下,缺失的模式可以通过其他变量来解释。例如,年龄较高的受调查者可能更不愿意透露其收入信息。
- **非随机缺失(MNAR)**:数据缺失依赖于未观测到的数据或缺失值本身。这种情况下,缺失的数据不能通过已有的观测数据来解释。例如,低收入个体可能倾向于不报告其收入信息。
### 2.1.2 缺失数据产生的原因
缺失数据可能由多种原因引起,包括但不限于以下几点:
- **数据收集过程中的错误**:调查问卷填写不完整、数据录入错误或设备故障等。
- **隐私或敏感性问题**:参与者可能拒绝提供敏感或私密的信息。
- **设备限制**:某些测量设备可能无法记录极端值或特定范围内的数据。
- **时间因素**:随时间变化的数据可能因为错过记录时间点而缺失。
- **不可抗力因素**:如自然灾害、战争等不可预测事件导致数据丢失。
## 2.2 缺失数据的影响分析
### 2.2.1 对数据分析的影响
缺失数据对数据分析有着显著的影响。最直观的影响是,缺失数据会减少可用的数据量,从而降低统计分析的精度和可靠性。在某些情况下,即使是少量的缺失数据也可能严重扭曲分析结果。此外,缺失数据的存在可能导致分析者采用不恰当的数据处理方法,进而影响结果的解释。
### 2.2.2 对数据模型的影响
在构建数据模型时,缺失数据可以导致模型参数估计的偏差。例如,在使用线性回归模型时,如果关键解释变量存在缺失值,那么模型的预测能力和准确性都会受到影响。此外,缺失数据还可能影响模型的选择和验证过程。
## 2.3 缺失数据的识别方法概述
### 2.3.1 统计测试方法
统计测试方法通常用于检测数据的缺失是否随机。可以使用卡方检验、t检验等统计方法来评估数据缺失的模式。此外,还可以通过模型拟合优度检验来判断数据是否符合MCAR假设。
### 2.3.2 基于机器学习的方法
基于机器学习的方法可以从数据中学习缺失模式,并预测缺失值。这些方法包括聚类分析、决策树、随机森林等。通过训练模型,我们可以对缺失数据进行估计,从而进行填充或删除。
### 2.3.3 可视化方法
可视化是识别和理解缺失数据模式的一个重要手段。散点图、热图、箱型图等可以直观展示数据的缺失情况,帮助分析者找到缺失数据的分布规律,例如是否存在数据缺失的空间或时间聚集性。
接下来的章节将详细介绍缺失数据可视化的具体应用和实践案例。
# 3. 数据可视化的工具与技术
数据可视化是一个将复杂的数据集转换成可视化图形的过程,它帮助人们更直观地理解数据背后的信息。随着信息技术的发展,各种数据可视化工具和技术不断涌现,为不同的需求提供了多样的解决方案。本章将重点介绍当前主流的数据可视化工具,以及在缺失数据识别中的应用技术。
## 3.1 数据可视化工具的选择
数据可视化工具的种类繁多,从简单的静态图表工具到复杂的交互式数据可视化平台,不同的工具有着不同的特点和适用场景。在这一部分,我们将着重介绍两种主流的静态图表工具(Matplotlib与Seaborn)和两种交互式工具(Plotly与Dash)。
### 3.1.1 静态图表工具:Matplotlib与Seaborn
Matplotlib是一个Python库,广泛应用于数据可视化,它允许用户生成二维图表,如折线图、柱状图、散点图、直方图等。Matplotlib的灵活性高,几乎可以实现任何类型的静态图表。
```python
import matplotlib.pyplot as plt
# 示例:使用Matplotlib绘制一个简单的折线图
plt.figure(figsize=(10, 5))
plt.plot([1, 2, 3, 4, 5], [1, 4, 9, 16, 25])
plt.title('Simple Line Plot')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.grid(True)
plt.show()
```
Seaborn是基于Matplotlib的数据可视化库,提供更为高级的接口,更适用于统计数据,可快速生成复杂的统计图形。
```python
import seaborn as sns
import matplotlib.pyplot as plt
# 示例:使用Seaborn绘制一个散点图
tips = sns.load_dataset('tips')
sns.scatterplot(x='total_bill', y='tip', data=tips)
plt.title('Scatterplot of Total Bill vs Tip')
plt.xlabel('Total Bill')
plt.ylabel('Tip')
plt.show()
```
### 3.1.2 动态交互式工具:Plotly与Dash
Plotly是一个可以用来创建交互式图表的库,它支持在线分享和导出。Plotly生成的图表不仅美观,而且支持缩放、拖动等多种交互方式。
```python
import plotly.express as px
# 示例:使用Plotly绘制一个气泡图
df = px.data.gapminder().query("year == 2007")
fig = px.scatter(df, x="gdpPercap", y="lifeExp", size="pop", color="continent",
hover_name="country", log_x=True, size_max=60)
fig.show()
```
Dash是Plotly开发的一个用于构建交互式Web应用的框架,非常适合用于创建数据仪表板。
```python
import dash
import dash_core_components as dcc
import dash_html_components as html
# 示例:创建一个简单的Dash应用
app = dash.Dash(__name__)
app.layout = html.Div([
dcc.Graph(
id='example-graph',
figure={
'data': [
{'x': [1, 2, 3], 'y': [4, 1, 2], 'type': 'bar', 'name': 'SF'},
{'x': [1, 2, 3], 'y': [2, 4, 5], 'type': 'bar', 'name': u'Montréal'},
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《缺失值处理》专栏深入探讨了缺失值处理在数据科学中的重要性。它提供了全面的指南,从识别缺失值到采用高级技术进行处理。专栏涵盖了各种编程语言和工具,包括 Python 和 R,并提供了实用的策略和最佳实践,以优化机器学习和预测模型。它还强调了自动化脚本、数据可视化和探索性数据分析在缺失值处理中的作用。此外,专栏探讨了大数据挑战、时间序列数据处理和统计陷阱,为数据科学家提供了全面的资源,以提高数据完整性和准确性。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机数字时钟案例分析】:深入理解中断管理与时间更新机制
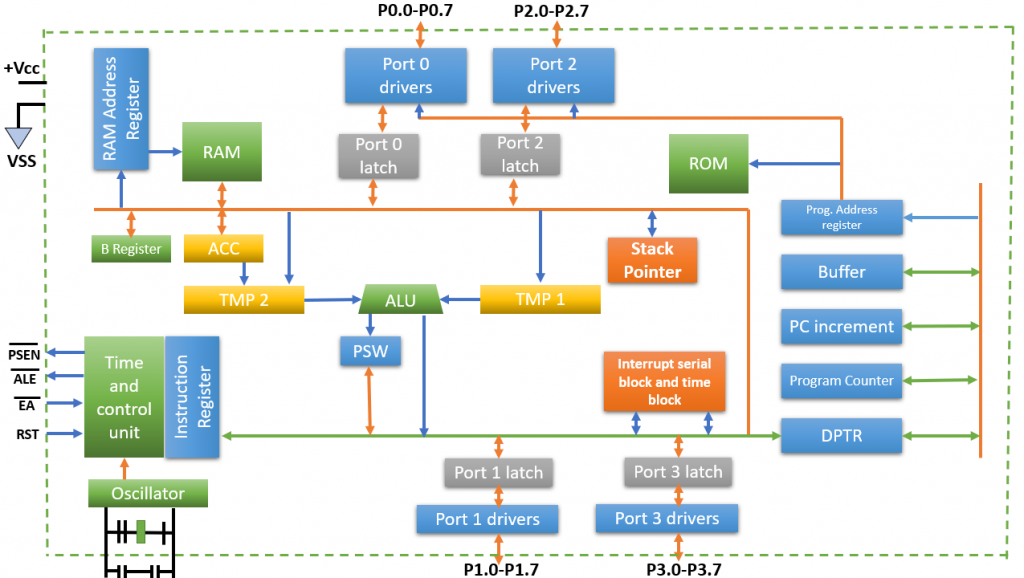
# 摘要
本文详细探讨了基于51单片机的数字时钟设计与实现。首先介绍了数字时钟的基本概念、功能以及51单片机的技术背景和应用领域。接着,深入分析了中断管理机制,包括中断系统原理、51单片机中断系统详解以及中断管理在实际应用中的实践。本文还探讨了时间更新机制的实现,阐述了基础概念、在51单片机下的具体策略以及优化实践。在数字时钟编程与调试章节中,讨论了软件设计、关键功能实现以及调试
【版本升级无忧】:宝元LNC软件平滑升级关键步骤大公开!

# 摘要
宝元LNC软件的平滑升级是确保服务连续性与高效性的关键过程,涉及对升级需求的全面分析、环境与依赖的严格检查,以及升级风险的仔细评估。本文对宝元LNC软件的升级实践进行了系统性概述,并深入探讨了软件升级的理论基础,包括升级策略
【异步处理在微信小程序支付回调中的应用】:C#技术深度剖析

# 摘要
本文首先概述了异步处理与微信小程序支付回调的基本概念,随后深入探讨了C#中异步编程的基础知识,包括其概念、关键技术以及错误处理方法。文章接着详细分析了微信小程序支付回调的机制,阐述了其安全性和数据交互细节,并讨论了异步处理在提升支付系统性能方面的必要性。重点介绍了如何在C#中实现微信支付的异步回调,包括服务构建、性能优化、异常处理和日志记录的最佳实践。最后,通过案例研究,本文分析了构建异步支付回调系统的架构设计、优化策略和未来挑战,为开
内存泄漏不再怕:手把手教你从新手到专家的内存管理技巧

# 摘要
内存泄漏是影响程序性能和稳定性的关键因素,本文旨在深入探讨内存泄漏的原理及影响,并提供检测、诊断和防御策略。首先介绍内存泄漏的基本概念、类型及其对程序性能和稳定性的影响。随后,文章详细探讨了检测内存泄漏的工具和方法,并通过案例展示了诊断过程。在防御策略方面,本文强调编写内存安全的代码,使用智能指针和内存池等技术,以及探讨了优化内存管理策略,包括内存分配和释放的优化以及内存压缩技术的应用。本文不
反激开关电源的挑战与解决方案:RCD吸收电路的重要性
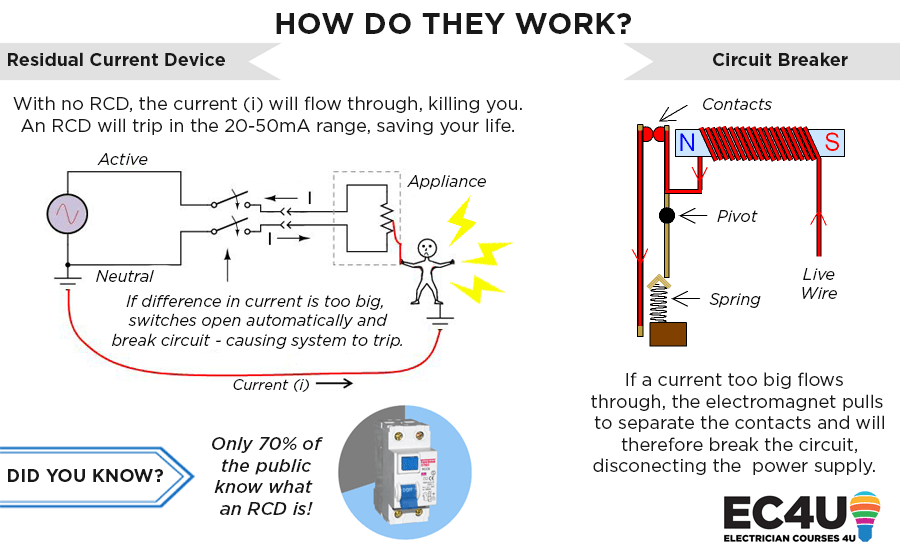
# 摘要
本文系统探讨了反激开关电源的工作原理及RCD吸收电路的重要作用和优势。通过分析RCD吸收电路的理论基础、设计要点和性能测试,深入理解其在电压尖峰抑制、效率优化以及电磁兼容性提升方面的作用。文中还对RCD吸收电路的优化策略和创新设计进行了详细讨论,并通过案例研究展示其在不同应用中的有效性和成效。最后,文章展望了RCD吸收电路在新材料应用
【Android设备标识指南】:掌握IMEI码的正确获取与隐私合规性

# 摘要
IMEI码作为Android设备的唯一标识符,不仅保证了设备的唯一性,还与设备的安全性和隐私保护密切相关。本文首先对IMEI码的概念及其重要性进行了概述,然后详细介绍了获取IMEI码的理论基础和技术原理,包括在不同Android版本下的实践指南和高级处理技巧。文中还讨论了IMEI码的隐私合规性考量和滥用防范策略,并通过案例分析展示了IMEI码在实际应用中的场景。最后,本文探讨了隐私保护技术的发展趋势以及对开发者在合规性
E5071C射频故障诊断大剖析:案例分析与排查流程(故障不再难)
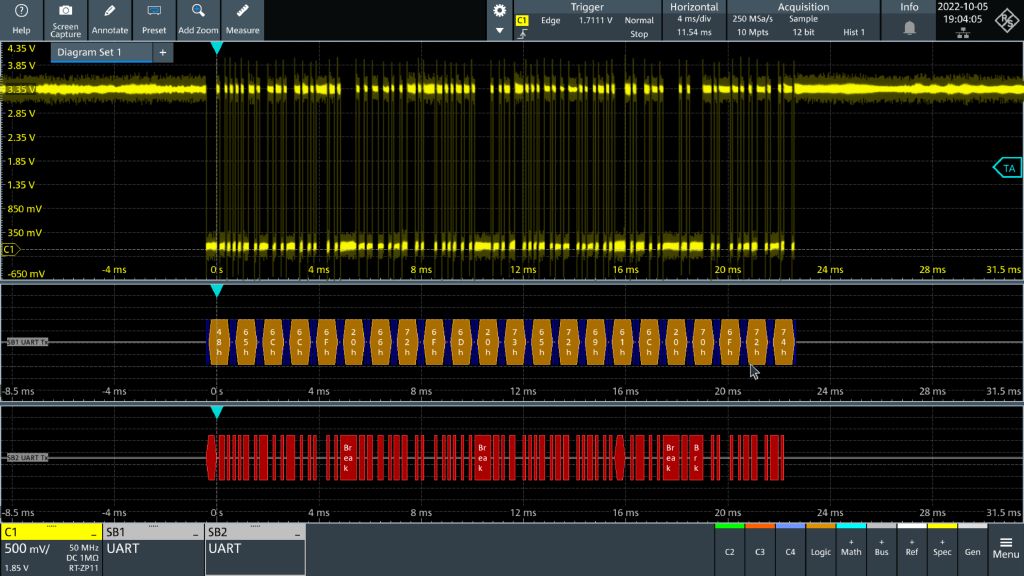
# 摘要
本文对E5071C射频故障诊断进行了全面的概述和深入的分析。首先介绍了射频技术的基础理论和故
【APK网络优化】:减少数据消耗,提升网络效率的专业建议

# 摘要
随着移动应用的普及,APK网络优化已成为提升用户体验的关键。本文综述了APK网络优化的基本概念,探讨了影响网络数据消耗的理论基础,包括数据传输机制、网络请求效率和数据压缩技术。通过实践技巧的讨论,如减少和合并网络请求、服务器端数据优化以及图片资源管理,进一步深入到高级优化策略,如数据同步、差异更新、延迟加载和智能路由选择。最后,通过案例分析展示了优化策略的实际效果,并对5G技
DirectExcel数据校验与清洗:最佳实践快速入门
# 摘要
本文旨在介绍DirectExcel在数据校验与清洗中的应用,以及如何高效地进行数据质量管理。文章首先概述了数据校验与清洗的重要性,并分析了其在数据处理中的作用。随后,文章详细阐述了数据校验和清洗的理论基础、核心概念和方法,包括校验规则设计原则、数据校验技术与工具的选择与应用。在实践操作章节中,本文展示了DirectExcel的界面布局、功能模块以及如何创建
【模糊控制规则优化算法】:提升实时性能的关键技术
# 摘要
模糊控制规则优化算法是提升控制系统性能的重要研究方向,涵盖了理论基础、性能指标、优化方法、实时性能分析及提升策略和挑战与展望。本文首先对模糊控制及其理论基础进行了概述,随后详细介绍了基于不同算法对模糊控制规则进行优化的技术,包括自动优化方法和实时性能的改进策略。进一步,文章分析了优化对实时性能的影响,并探索了算法面临的挑战与未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )