特征工程工具箱:掌握20大特征工程常用工具和库
发布时间: 2024-09-03 21:11:31 阅读量: 172 订阅数: 59 

# 1. 特征工程概述与重要性
## 1.1 特征工程定义
特征工程是机器学习中的核心过程,涉及从原始数据中设计和构造特征来提高模型的性能。这一过程不仅包括提取数据的有用信息,还包括转换和选择特征,以便算法能够更有效地从数据中学习。
## 1.2 特征工程的重要性
良好的特征工程可以显著提升模型的准确度和效率。它通过减少噪声、删除不相关的特征、创造新特征以及提取重要特征来优化模型性能。有效的特征工程可以使得模型训练更快,泛化能力更强。
## 1.3 特征工程的应用领域
特征工程广泛应用于数据挖掘、图像处理、自然语言处理等多个领域。无论是在金融行业的信用评分模型,还是在互联网公司进行广告点击率预估,特征工程都在其中扮演着至关重要的角色。
# 2. 特征工程基础工具
特征工程是机器学习中一项基础而核心的任务,它涉及到从原始数据中选择、构造和转换特征,以提高模型的性能。本章节将重点介绍特征工程的基础工具,包括数据预处理、特征提取、特征选择等关键步骤。
## 2.1 数据预处理工具
数据预处理是特征工程的第一步,也是至关重要的一步。它能够清洗原始数据,为后续的分析和建模提供干净、一致的数据集。
### 2.1.1 缺失值处理方法
在处理数据集时,我们经常会遇到缺失值的问题。缺失值是指在数据集中缺少某一个或几个数据项的情况。处理缺失值的方法有很多,常见的有:
- 删除:如果数据集中的缺失值不多,可以选择删除包含缺失值的行或列。这种方法简单直接,但可能会导致数据信息的丢失。
- 填充:使用某个特定值来填充缺失值,这个值可以是平均值、中位数、众数或者根据模型预测的结果。填充方法可以保持数据集的完整性。
- 插值:使用插值方法根据周围值估计缺失值。例如,线性插值、多项式插值等。
下面是一个使用Python中pandas库处理缺失值的示例代码块:
```python
import pandas as pd
# 创建一个含有缺失值的数据框DataFrame
data = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [5, None, None, 8],
'C': [9, 10, 11, 12]
})
# 查看数据框
print(data)
# 使用均值填充缺失值
data_filled = data.fillna(data.mean())
print("\nFill with mean:")
print(data_filled)
# 使用中位数填充缺失值
data_filled_median = data.fillna(data.median())
print("\nFill with median:")
print(data_filled_median)
# 删除含有缺失值的行
data_dropped = data.dropna()
print("\nDrop rows with missing values:")
print(data_dropped)
```
在处理缺失值时,选择哪种方法取决于数据的特性以及缺失值的比例。理解缺失值产生的背景对于采取正确的处理方法至关重要。
### 2.1.2 数据标准化与归一化技术
数据标准化和归一化是数据预处理的常用技术。标准化是将数据按比例缩放,使之落入一个小的特定区间,如-1到1或0到1。而归一化是将数据缩放到一个标准范围,通常是0到1,或者将数据转换为均值为0,方差为1的分布。
常见的标准化方法有Z-score标准化,其通过减去均值并除以标准差来实现。归一化则可以通过最小-最大规范化来完成,公式为`(x - min) / (max - min)`。
这里是一个使用Python中scikit-learn库进行标准化和归一化的代码示例:
```python
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 假设有一个数据集
data = [[100, 2], [80, 1], [0, -1], [50, 0]]
# 初始化标准化器和归一化器
scaler = StandardScaler()
normalizer = MinMaxScaler()
# 标准化数据
data_scaled = scaler.fit_transform(data)
print("Standardized data:")
print(data_scaled)
# 归一化数据
data_normalized = normalizer.fit_transform(data)
print("\nNormalized data:")
print(data_normalized)
```
标准化和归一化对于很多算法来说非常重要,比如K-最近邻和神经网络,它们对数据的尺度很敏感。这些预处理步骤能提高算法的收敛速度和性能。
## 2.2 特征提取技术
特征提取是指从原始数据中提取信息来构建新的特征的过程,这些新的特征能够更好地表示问题的本质。
### 2.2.1 主成分分析(PCA)
PCA是一种常用的特征提取方法,其目的是减少数据的维度,同时尽可能保留数据的特征。PCA通过线性变换将数据投影到较低维度的空间,以达到去相关和降维的目的。
在PCA中,新特征(主成分)是原始特征的线性组合,且这些主成分能够最大程度地反映数据的变异性。在很多情况下,前几个主成分就能包含原始数据的大部分信息。
在Python中,可以使用scikit-learn库中的PCA类轻松实现PCA:
```python
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 创建一个简单的数据集
data = [[1, 2], [3, 4], [5, 6], [7, 8]]
# 数据标准化
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# 初始化PCA,设定要降维到的主成分数量为1
pca = PCA(n_components=1)
# 执行PCA
data_pca = pca.fit_transform(data_scaled)
print("PCA-reduced data:")
print(data_pca)
```
通过PCA降维,可以减少数据集的复杂度,提高算法效率,同时也有可能提高模型的准确性。
### 2.2.2 线性判别分析(LDA)
LDA是一种监督学习的特征提取技术,与PCA不同的是,LDA会考虑类别信息,旨在找到最佳的投影方向,使得同类数据在新的特征空间中的距离尽可能近,而不同类别的数据距离尽可能远。
LDA用于分类问题时可以增强类间的可分性,通常在数据集较小,类别较多的情况下效果很好。
下面是一个使用scikit-learn库的LDA降维的代码示例:
```python
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 假设有标签的数据集
data = [[1, 2], [3, 4], [5, 6], [7, 8]]
labels = [0, 0, 1, 1]
# 初始化LDA
lda = LinearDiscriminantAnalysis(n_components=1)
# 应用LDA降维
data_lda = lda.fit_transform(data, labels)
print("LDA-reduced data:")
print(data_lda)
```
LDA不仅能够降维,还能够帮助提高分类器的性能,特别是对于类别重叠较大的数据集。
## 2.3 特征选择方法
特征选择是选择一部分有用的特征,去掉对预测任务无用或冗余的特征的过程。有效的特征选择可以提高模型的预测能力、减少训练时间和防止过拟合。
### 2.3.1 过滤法(Filter Methods)
过滤法根据数据的统计特性独立于模型进行特征选择。这些方法通常会计算特征与标签之间的相关性指标,如卡方检验、相关系数和互信息等。
一个常用的过滤法的例子是使用相关系数来选择特征:
```python
import pandas as pd
from sklearn.datasets import load_iris
# 加载Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
df = pd.DataFrame(X, columns=iris.feature_names)
# 计算每个特征与目标标签的相关系数
correlation_matrix = df.corr().abs()
# 选择与目标标签高度相关的特征
correlation_matrix['target'] = y
top_features = correlation_matrix.nlargest(5, 'target')['target']
print("Top correlated features with target:")
print(top_features)
```
过滤法简单易行,适用于初步筛选特征,但可能会忽略特征之间的关联性。
### 2.3.2 包裹法(Wrapper Methods)
包裹法利用特定的模型来评估特征子集的好坏。它通过循环添加和移除特征,基于模型的表现来决定保留哪些特征。常见的包裹法有递归特征消除(RFE)。
下面是使用RFE进行特征选择的代码示例:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
# 加载Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 初始化逻辑回归模型
model = LogisticRegression()
# 使用RFE选择特征
rfe = RFE(estimator=model, n_features_to_select=3)
fit = rfe.fit(X, y)
print("RFE Selected Features:")
print(fit.support_)
```
包裹法考虑到了模型的影响,因此通常能得到更好的性能,但计算成本较高,因为需要多次训练模型。
### 2.3.3 嵌入法(Embedded Methods)
嵌入法结合了过滤法和包裹法的特点,它通过优化一个带有正则化项的模型来进行特征选择,例如在正则化中常见的L1和L2惩罚项。
L1正则化(Lasso回归)可以产生稀疏模型,有助于特征选择:
```python
from sklearn.linear_model import LassoCV
# 加载Iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 使用Lasso进行特征选择
lasso = LassoCV(cv=5).fit(X, y)
print("Lasso Selected Features:")
print((lasso.coef_ != 0))
```
由于嵌入法在模型训练过程中同时进行特征选择,因此它能够有效地控制模型复杂度,并且找到对模型性能影响最大的特征。
本章节通过介绍特征工程中重要的基础工具,包括数据预处理、特征提取和特征选择等技术,帮助读者构建起特征工程的核心知识框架。通过应用上述工具,数据科学家可以更有效地准备数据,提取有价值的特征,最终构建出强大的机器学习模型。随着对每个技术细节的理解加深,下一章将深入探讨高级特征工程库的使用,为读者在实际应用中提供更高级的工具和技巧。
# 3. 高级特征工程库详解
## 3.1 Scikit-learn特征工具箱
### 3.1.1 特征转换类与函数
在机器学习流程中,特征转换是一个关键步骤,它包括缩放、中心化和变换数据等操作,目的是为了提高模型的预测性能。Scikit-learn库提供了多种特征转换类与函数,使我们能够轻松地对数据进行这类操作。
#### 缩放和中心化
以 `StandardScaler` 和 `MinMaxScaler` 为例,它们分别用于标准化和归一化数据。标准化通常使特征拥有零均值和单位方差,而归一化则是将特征缩放到一个范围,例如0到1。
```python
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 假设 X_train 是训练数据集
sca
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
特征工程在机器学习中至关重要,它通过将原始数据转换为机器学习模型可用的特征,提升模型性能。本专栏深入探讨了特征工程的各个方面,提供了实用的指南和技巧。从特征选择和缩放,到异常值处理和自然语言处理的预处理,再到时间序列的特征提取,该专栏涵盖了特征工程的方方面面。此外,它还介绍了自动化特征工程工具和框架,以及特征重要性评分和业务影响等高级主题。通过掌握这些原则和技术,数据科学家和机器学习工程师可以构建更有效、更准确的机器学习模型。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
三菱NZ81GP21-SX型接口板安装与配置:CC-Link IE技术基础完全攻略

# 摘要
CC-Link IE技术作为一种工业以太网解决方案,已被广泛应用于自动化控制领域。本文首先概述了CC-Link IE技术的基本概念及其重要性。随后,重点介绍了三菱NZ81GP21-SX型接口板的硬件结构及功能,并详细阐述了其安装步骤,包括物理安装和固件更新。接着,本文深入探讨了CC-Link I
【Pinpoint性能监控深度解析】:架构原理、数据存储及故障诊断全攻略
# 摘要
Pinpoint性能监控系统作为一款分布式服务追踪工具,通过其独特的架构设计与数据流处理机制,在性能监控领域展现出了卓越的性能。本文首先概述了Pinpoint的基本概念及其性能监控的应用场景。随后深入探讨了Pinpoint的架构原理,包括各组件的工作机制、数据收集与传输流程以及分布式追踪系统的内部原理。第三章分析了Pinpoint在数据存储与管理方面的技术选型、存储模型优化及数据保留策略。在第四章中,本文详细描述了Pinpoint的故障诊断技术,包括故障分类、实时故障检测及诊断实例。第五章探讨了Pinpoint的高级应用与优化策略,以及其未来发展趋势。最后一章通过多个实践案例,分享了
软件工程中的FMEA实战:从理论到实践的完整攻略
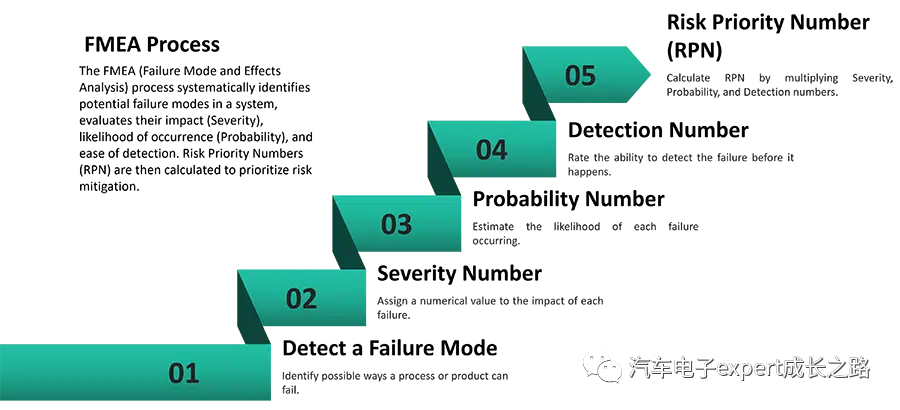
# 摘要
FMEA(故障模式与影响分析)是软件工程中用于提高产品可靠性和安全性的重要质量工具。本文详细解析了FMEA的基本概念、理论基础和方法论,并探讨了其在软件工程中的分类与应用。文章进一步阐述了FMEA实践应用的流程,包括准备工作、执行分析和报告编写等关键步骤。同时,本文还提供了FMEA在敏捷开发环境中的应用技巧,并通过案例研究分享了成功的行
CITICs_KC接口数据处理:从JSON到XML的高效转换策略
![CITICs_KC股票交易接口[1]](https://bytwork.com/sites/default/files/styles/webp_dummy/public/2021-07/%D0%A7%D1%82%D0%BE%20%D1%82%D0%B0%D0%BA%D0%BE%D0%B5%20%D0%9B%D0%B8%D0%BC%D0%B8%D1%82%D0%BD%D1%8B%D0%B9%20%D0%BE%D1%80%D0%B4%D0%B5%D1%80.jpg?itok=nu0IUp1C)
# 摘要
随着信息技术的发展,CITICs_KC接口在数据处理中的重要性日益凸显。本文首先概述了C
光学信号处理揭秘:Goodman版理论与实践,光学成像系统深入探讨

# 摘要
本文系统地介绍了光学信号处理的基础理论、Goodman理论及其深入解析,并探讨了光学成像系统的实践应用。从光学信号处理的基本概念到成像系统设计原理,再到光学信号处理技术的最新进展和未来方向,本文对光学技术领域的核心内容进行了全面的梳理和分析。特别是对Goodman理论在光学成像中的应用、数字信号处理技术、光学计算成像技术进行了深入探讨。同时,本文展望了量子光学信号处理、人工智能在光
队列的C语言实现:从基础到循环队列的进阶应用
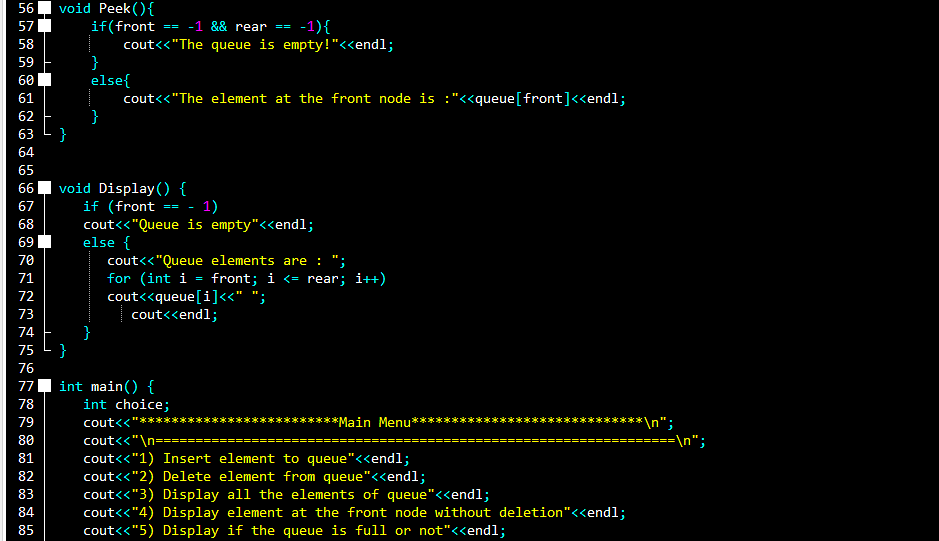
# 摘要
本论文旨在系统地介绍队列这一基础数据结构,并通过C语言具体实现线性队列和循环队列。首先,本文详细解释了队列的概念、特点及其在数据结构中的地位。随后,深入探讨了线性队列和循环队列的实现细节,包括顺序存储结构设计、入队与出队操作,以及针对常见问题的解决方案。进一步,本文探讨了队列在
【CAXA图层管理:设计组织的艺术】:图层管理的10大技巧让你的设计井井有条
# 摘要
图层管理是确保设计组织中信息清晰、高效协同的关键技术。本文首先介绍了图层管理的基本概念及其在设计组织中的重要性,随后详细探讨了图层的创建、命名、属性设置以及管理的理论基础。文章进一步深入到实践技巧,包括图层结构的组织、视觉管理和修改优化,以及CAXA环境中图层与视图的交互和自动化管理。此外,还分析了图层管理中常见的疑难问题及其解决策略,并对图层管理技术的未来发展趋势进行了展望,提出了一系列面向未来的管理策略。
# 关键字
图层管理;CAXA;属性设置;实践技巧;自动化;协同工作;未来趋势
参考资源链接:[CAXA电子图板2009教程:绘制箭头详解](https://wenku.c
NET.VB_TCPIP协议栈深度解析:从入门到精通的10大必学技巧

# 摘要
本文全面探讨了TCP/IP协议栈的基础理论、实战技巧以及高级应用,旨在为网络工程师和技术人员提供深入理解和高效应用TCP/IP协议的指南。文章首先介绍了TCP/IP协议栈的基本概念和网络通信的基础理论,包括数据包的封装与解封装、传输层协议TCP和UDP的原理,以及网络层和网络接口层的关键功能。接着,通过实战技巧章节,探讨了在特定编程环境下如VB进行
MCP41010数字电位计初始化与配置:从零到英雄
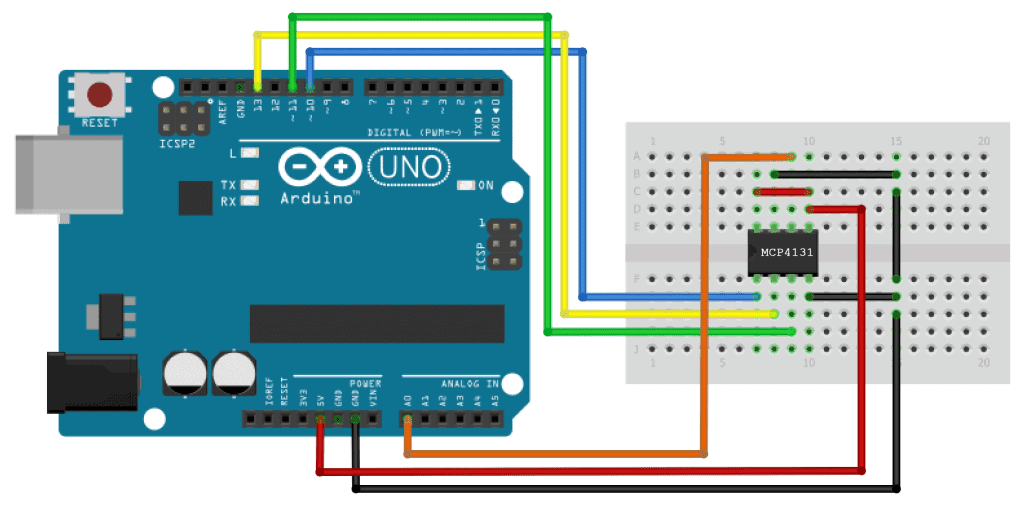
# 摘要
本文全面介绍MCP41010数字电位计的功能、初始化、配置以及高级编程技巧。通过深入探讨其工作原理、硬件接口、性能优化以及故障诊断方法,本文为读者提供了一个实用的技术指导。案例研究详细分析了MCP41010在电路调节、用户交互和系统控制中的应用,以
【Intouch界面初探】:5分钟掌握Intouch建模模块入门精髓

# 摘要
本文系统性地介绍了Intouch界面的基本操作、建模模块的核心概念、实践应用,以及高级建模技术。首先,文章概述了Intouch界面的简介与基础设置,为读者提供了界面操作的起点。随后,深入分析了建模模块的关键组成,包括数据驱动、对象管理、界面布局和图形对象操作。在实践应用部分,文章详细讨论了数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )