【Jetson Xavier NX编程快速入门】:初学者必备的上手秘籍,轻松驾驭AI边缘设备
发布时间: 2024-12-14 16:40:07 阅读量: 14 订阅数: 8 
参考资源链接:[NVIDIA Jetson Xavier NX 载板设计与原理图](https://wenku.csdn.net/doc/4nxgpqb4rh?spm=1055.2635.3001.10343)
# 1. Jetson Xavier NX概述与安装
本章将带领读者进入NVIDIA Jetson Xavier NX的世界,揭开其神秘的面纱。首先,我们会简要介绍Jetson Xavier NX这一产品的设计理念及其在边缘计算领域的应用潜力。接着,我们将详细说明如何快速上手安装Jetson Xavier NX,涵盖硬件准备、安装操作系统以及驱动设置。通过本章,读者将能够为后续深入探索打下坚实的基础。
## 1.1 设计理念与应用领域
Jetson Xavier NX是NVIDIA推出的边缘计算产品,专为嵌入式应用设计,支持高性能AI计算。其小巧的尺寸、高效的功耗和强大的计算能力使其成为物联网、机器人技术和智能监控等领域的理想选择。相比其他同类型产品,Jetson Xavier NX在保持低功耗的同时提供了出色的AI推理性能。
## 1.2 系统安装准备
在安装Jetson Xavier NX系统之前,需要准备以下物品:
- Jetson Xavier NX开发板
- Micro-SD卡(至少16GB,推荐使用Class 10或以上)
- 读卡器
- Windows、macOS或Linux系统的计算机
- USB键盘和鼠标
安装步骤简述如下:
1. 下载NVIDIA官方提供的Jetson Xavier NX镜像文件。
2. 使用读卡器将SD卡格式化,并将下载好的镜像文件写入SD卡。
3. 将已写入的SD卡插入Jetson Xavier NX开发板。
4. 连接电源、键盘、鼠标及显示器,启动开发板。
5. 按照屏幕上的引导完成系统的初次配置,包括设置网络、语言、时区等。
## 1.3 安装注意事项
安装过程中需要注意以下几点:
- 确保SD卡写入过程完整,没有发生任何错误。
- 在安装过程中,始终保持开发板供电稳定。
- 如果遇到问题,可以参考NVIDIA官方文档或社区论坛获取支持。
至此,我们已经完成了Jetson Xavier NX的安装工作,为接下来的深入学习和开发奠定了基础。在下一章,我们将探讨Jetson Xavier NX的系统架构,揭示其硬件和软件的秘密。
# 2. Jetson Xavier NX系统架构
### 2.1 NVIDIA Jetson Xavier NX硬件解析
#### 2.1.1 CPU与GPU性能概览
Jetson Xavier NX融合了NVIDIA Volta GPU架构,包含8个SM单元(流式多处理器)和1个Volta GPU核心,提供多达128个Tensor核心,这些核心专为深度学习计算而优化。其CPU采用64位ARMv8架构,包含8个核心,每个核心频率可达1.9GHz。这样的设计使得Xavier NX能够提供高达21 TOPS(Tera Operations Per Second)的计算能力,而功耗仅为10W到15W。
在深度学习计算上,Xavier NX的Volta GPU架构可以有效地处理矩阵运算和并行数据处理任务,非常适合于执行高效的神经网络推理。而其CPU部分,则能够处理操作系统任务和一些传统的编程工作负载,实现系统的高效率和平衡处理能力。
为了充分利用Xavier NX的计算性能,开发者需要理解每个核心单元的功能,以及它们如何协作以提升整体系统的性能。下表展示了Xavier NX的硬件规格摘要:
| 规格 | 描述 |
| --- | --- |
| 处理器 | NVIDIA Carmel ARMv8.2 CPU (64-bit) |
| GPU | NVIDIA Volta GPU with 384 CUDA cores and 48 Tensor cores |
| 内存 | 8 GB 128-bit LPDDR4x @ 59.7 GB/s |
| 存储 | 16 GB eMMC 5.1 |
| 视频编码器 | 2x 4Kp30 |
| 视频解码器 | 1x 4Kp60, 2x 4Kp30 |
| 网络 | 10/100/1000 BASE-T Ethernet |
这一硬件配置为边缘计算和AI推理提供了坚实的基础。
#### 2.1.2 内存与存储特性
Jetson Xavier NX的内存架构设计为内存带宽高效,拥有128-bit LPDDR4x接口,支持高达59.7 GB/s的内存带宽,为大规模数据处理提供了强力支持。它搭配了8 GB的内存,能够处理复杂的神经网络模型和高分辨率的数据输入。对于存储,Jetson Xavier NX配备了16 GB的板载eMMC 5.1闪存,提供足够的存储空间以支持操作系统和应用程序,并且它的速度足以应对实时数据访问。
在处理视频流或图像数据时,内存和存储的性能尤为重要。高速的内存带宽确保图像数据可以快速的从存储设备读取,经过GPU处理后迅速输出。这样不仅能够满足实时处理的需要,而且能够支持在有限的功耗下实现高吞吐量的数据处理。
通过合理利用Jetson Xavier NX的内存和存储资源,开发者可以在边缘设备上部署更为复杂和功能丰富的应用。
### 2.2 系统软件环境搭建
#### 2.2.1 安装NVIDIA JetPack SDK
NVIDIA JetPack是一个全面的软件开发包(SDK),包含了运行在Jetson平台上的操作系统镜像、Linux驱动程序、CUDA、cuDNN和TensorRT等NVIDIA深度学习和计算机视觉库,以及示例代码和文档。安装JetPack是搭建Jetson Xavier NX软件环境的第一步。
为了安装JetPack,需要准备一个兼容的Linux主机,一个microSD卡,并确保下载了正确的JetPack版本和驱动程序。以下是安装步骤的概览:
1. 从NVIDIA官方网站下载最新版本的JetPack。
2. 准备microSD卡,至少需要16GB的容量。
3. 使用Balena Etcher等工具将JetPack镜像烧录到microSD卡。
4. 在microSD卡上创建一个空文件夹,命名为"storage",这将被用于扩展存储空间。
5. 将烧录好的microSD卡插入到Jetson Xavier NX,并连接电源。
6. 执行初始配置过程,包括设置用户名、密码,以及安装必要的软件包。
安装完成后,需要登录系统并更新到最新版的SDK Manager工具,然后可以根据需要选择安装额外的组件,比如TensorRT、cuDNN等深度学习库。
#### 2.2.2 配置CUDA、cuDNN和TensorRT
CUDA(Compute Unified Device Architecture)是NVIDIA推出的通用并行计算架构,允许开发者利用GPU进行计算密集型任务。cuDNN(CUDA Deep Neural Network library)是NVIDIA提供的深度神经网络加速库。TensorRT是NVIDIA的深度学习推理优化器和运行时引擎,用于优化深度学习模型并提升推理性能。
在安装了JetPack后,CUDA、cuDNN和TensorRT通常会预装在系统上。但是,开发者可能需要手动配置这些库以确保最佳性能。配置CUDA和cuDNN涉及到更新环境变量以及确保链接库的正确路径。TensorRT需要一个独立的安装步骤,包括安装运行时和编译时组件。
配置工作通常在终端中执行,例如,设置CUDA的路径:
```bash
export PATH=/usr/local/cuda-10.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH
```
而cuDNN的配置需要将其库文件的路径添加到LD_LIBRARY_PATH环境变量中:
```bash
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
```
TensorRT的安装则涉及到解压下载的压缩文件,以及运行提供的安装脚本:
```bash
tar -xzvf TensorRT-7.0.0.11.Ubuntu-18.04.x86_64-gnu.cuda-10.2.cudnn8.0.tar.gz
cd TensorRT-7.0.0.11/python
sudo pip3 install tensorrt‑7.0.0‑cp36‑none‑linux_x86_64.whl
```
经过这些步骤后,系统就配置好了CUDA、cuDNN和TensorRT,为后续深度学习模型的开发和优化奠定了基础。在实际开发过程中,开发者应当检查所安装的版本是否与支持的框架版本相兼容,确保系统的稳定性和性能。
# 3. Jetson Xavier NX编程基础
## 3.1 NVIDIA提供的开发工具和库
### 3.1.1 CUDA编程模型简介
CUDA(Compute Unified Device Architecture)是一种由NVIDIA推出的并行计算平台和编程模型。它允许开发者利用NVIDIA的GPU进行通用计算,这种计算方式相较于传统的CPU计算拥有显著的速度优势。在Jetson Xavier NX上,CUDA不仅加速了计算性能,而且促进了深度学习和高性能计算领域的革命。
CUDA编程模型基于一个简单的理念:将任务分割为更小的子任务,然后并行地在GPU上执行这些子任务。它采用SIMD(单指令多数据)架构,这意味着GPU的每一个核心在同一时间执行相同的操作,但处理不同的数据。
为了能够使用CUDA,开发者需要安装CUDA Toolkit。安装完成后,可以使用CUDA C/C++编写程序,这些程序在编译时会包含GPU指令集,并生成能够在GPU上运行的二进制代码。
下面是一个简单的CUDA示例代码,展示了如何定义一个内核函数并启动它:
```c
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void helloFromGPU() {
printf("Hello, World from GPU!\n");
}
int main() {
helloFromGPU<<<1, 1>>>(); // 启动一个线程块,其中包含一个线程
cudaDeviceSynchronize(); // 同步线程,等待所有线程完成
return 0;
}
```
此代码段将输出“Hello, World from GPU!”到控制台。`<<<1, 1>>>`指定了执行配置,这里是指定线程块数量为1,每个线程块中的线程数为1。CUDA的编程模型具有其特定的内存架构,包括全局内存、共享内存、常量内存和纹理内存等,开发者可以根据数据访问模式和计算需求,选择合适的内存类型以获得最佳性能。
### 3.1.2 cuDNN和TensorRT的性能优化
cuDNN(CUDA Deep Neural Network library)是由NVIDIA推出的深度神经网络库,它为深度学习框架提供了高度优化的实现,包括卷积、循环神经网络(RNNs)、归一化和激活函数等。在Jetson Xavier NX上使用cuDNN,可以显著提高深度学习模型的训练和推理速度。
cuDNN提供了不同精度的数据类型,比如FP32(32位浮点数)、FP16(16位浮点数)和INT8(8位整数)。FP16和INT8提供了更快的计算速度和较低的内存使用,但牺牲了一定的计算精度。在深度学习应用中,通常可以接受这种精度的折衷以获得更好的性能。
TensorRT是NVIDIA的另一个深度学习推理加速器,它优化了模型的运行速度和效率。TensorRT通过以下几种优化技术来实现性能的提升:
- 混合精度推理:将模型中的权重和激活函数数据类型从FP32转换到FP16,同时保持足够的精度。
- 内核自动调优:自动搜索最佳的卷积算法,减少计算时间和内存使用。
- 动态和静态张量内存管理:优化内存分配,避免不必要的内存复制。
以下是如何在Jetson Xavier NX上安装TensorRT的步骤:
1. 更新系统软件包列表:
```bash
sudo apt-get update
```
2. 安装TensorRT的依赖项:
```bash
sudo apt-get install libnvinfer6 libnvinfer-dev libnvinfer-plugin-dev
```
3. 确认TensorRT已成功安装:
```bash
dpkg -l | grep TensorRT
```
TensorRT支持导入多种深度学习框架训练好的模型,并对其进行优化,以适应NVIDIA硬件的特定性能特点。
## 3.2 实用编程示例
### 3.2.1 GPU加速的科学计算
利用CUDA进行GPU加速的科学计算可以极大提升计算效率。以下是一个使用CUDA实现的矩阵乘法示例,这是一个科学计算中的基本且耗时的操作。
```c
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#define BLOCK_SIZE 16
__global__ void matrixMulCUDA(float *C, const float *A, const float *B, int numARows, int numAColumns, int numBColumns) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
for (int e = 0; e < numAColumns; ++e) {
sum += A[row * numAColumns + e] * B[e * numBColumns + col];
}
C[row * numBColumns + col] = sum;
}
int main() {
// 这里省略了矩阵分配、初始化和内存拷贝的代码...
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid((numBColumns + BLOCK_SIZE - 1) / BLOCK_SIZE, (numARows + BLOCK_SIZE - 1) / BLOCK_SIZE);
matrixMulCUDA<<<dimGrid, dimBlock>>>(d_C, d_A, d_B, numARows, numAColumns, numBColumns);
// 这里省略了矩阵结果校验的代码...
return 0;
}
```
这个示例中,每个CUDA线程负责计算输出矩阵C的一个元素。`dimBlock`定义了每个线程块的大小,而`dimGrid`定义了网格的大小。这个程序的核心在于`matrixMulCUDA`内核函数,它并行计算了矩阵的每一个元素。CUDA编程允许开发者充分利用GPU的并行计算能力,加速科学计算。
### 3.2.2 AI模型部署与推理
深度学习模型部署到Jetson Xavier NX上涉及到模型的优化、转换和推理过程。以下是如何使用TensorRT进行模型部署和推理的步骤:
1. 将训练好的模型转换为TensorRT引擎格式:
```python
from tensorrt import TRTbettor
import pycuda.driver as cuda
import pycuda.autoinit
trt_logger = trt.Logger(trt.Logger.WARNING)
trtbettor = TRTbettor(trt.Logger(trt.Logger.WARNING), max_workspace_size=1 << 20)
engine = trtbettor.create_engine(onnx_file_path, build_flag=trt.BuilderFlag.FP16)
```
2. 将转换后的模型序列化并保存到磁盘:
```python
with open(engine_file, "wb") as f:
f.write(engine.serialize())
```
3. 加载序列化的TensorRT模型,并进行推理:
```python
import tensorrt as trt
runtime = trt.Runtime(trt_logger)
with open(engine_file, "rb") as f, runtime.create_execution_context() as context:
inputs, outputs, bindings = [], [], []
for binding in context:
size = trt.volume(context.get_binding_shape(binding)) * context.max_batch_size
dtype = trt.nptype(context.get_binding_dtype(binding))
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
bindings.append(int(device_mem))
if context.binding_is_input(binding):
inputs.append((device_mem, host_mem))
else:
outputs.append((device_mem, host_mem))
# 这里省略了输入数据准备和推理执行的代码...
```
在此示例中,首先将训练好的模型转换为TensorRT引擎,然后将其序列化并保存。推理时,加载序列化的引擎,准备输入输出数据,并执行推理操作。通过TensorRT优化,模型推理效率可以得到显著提升,特别适合运行在边缘计算设备上。
# 4. Jetson Xavier NX深度学习实战
## 4.1 TensorFlow与PyTorch框架部署
### 4.1.1 安装与配置TensorFlow for Jetson
NVIDIA Jetson Xavier NX的深度学习能力极为强大,而要在该平台上部署TensorFlow需要遵循一系列详细的步骤,以确保性能最优化。TensorFlow for Jetson是专为NVIDIA Jetson平台优化过的TensorFlow版本,它利用了Jetson Xavier NX上的GPU以及TensorRT优化器,可以显著提高深度学习模型的运行效率。
```bash
# 更新系统软件包列表
sudo apt-get update
# 安装依赖包
sudo apt-get install -y python3-pip libhdf5-serial-dev hdf5-tools libhdf5-dev
# 设置环境变量
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64
# 安装TensorFlow for Jetson
pip3 install --extra-index-url https://nvidia.github.io/l4t-tensorflow/tensorflow libtensorflow-1.15.0+nv19.3 tensorflow-1.15.0+nv19.3 torchaudio-0.1.15+nv19.3
# 验证安装
python3 -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
```
在安装命令中,我们首先更新了系统的软件包列表,然后安装了所有必需的依赖项,包括Python的pip包管理器,以及HDF5的开发和运行时库。接着,我们设置了环境变量`LD_LIBRARY_PATH`,该变量包含CUDA库的路径,这对于TensorFlow能够正确地利用GPU至关重要。最后,我们通过pip安装了TensorFlow for Jetson的软件包。
执行验证命令`python3 -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"`来检查TensorFlow是否正确安装并能正常运行。如果看到输出,就说明TensorFlow已经成功安装在Jetson Xavier NX上,并且能够正常运行。
### 4.1.2 安装与配置PyTorch for Jetson
与TensorFlow类似,PyTorch也是深度学习领域广泛使用的框架,它提供了强大的计算图功能和易于使用的接口。对于Jetson Xavier NX用户来说,安装PyTorch for Jetson同样重要,可以利用此平台进行高效的模型训练和部署。
```bash
# 更新系统软件包列表
sudo apt-get update
# 安装依赖包
sudo apt-get install -y python3-pip libopenblas-base libopenmpi-dev
# 安装PyTorch for Jetson
pip3 install torch torchvision torchaudio
# 验证安装
python3 -c "import torch; print(torch.__version__)"
```
在安装PyTorch之前,我们也更新了软件包列表,并安装了相关的依赖项。PyTorch的安装相对简单,通过pip安装命令`pip3 install torch torchvision torchaudio`即可完成安装。执行验证命令`python3 -c "import torch; print(torch.__version__)"`来确保安装成功。如果输出了安装的版本号,则说明PyTorch已经成功安装在Jetson Xavier NX上。
## 4.2 模型训练与优化
### 4.2.1 在Jetson上训练深度学习模型
在Jetson Xavier NX上训练深度学习模型是构建边缘AI应用的关键步骤。Jetson平台为开发者提供了强大的计算能力,但与此同时,模型训练是一个资源密集型任务,因此需要对训练流程进行优化以适应Jetson Xavier NX的性能特点。
首先,选择合适的数据集和预处理方法至关重要。在Jetson Xavier NX上,应优先考虑数据的压缩与批处理,以减少内存的使用并提高处理效率。接下来,在模型设计时,应当尽量减少模型的复杂度,但同时需要保证模型的准确率不受太大影响。例如,使用深度可分离卷积(Depthwise Separable Convolution)来替代传统的卷积层,可以在不显著降低准确率的前提下,大幅减少模型参数。
```python
import torch
import torchvision
import torchvision.transforms as transforms
# 数据集准备与预处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
# 定义模型结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 添加网络层的定义
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
```
上面的Python代码展示了如何为CIFAR-10数据集准备数据并定义一个简单的卷积神经网络(CNN)。这里使用了PyTorch框架,它非常适合于在Jetson Xavier NX上开发和训练深度学习模型。
### 4.2.2 使用TensorRT进行模型优化
TensorRT是NVIDIA推出的深度学习推理加速器,它可以显著提升深度学习模型在NVIDIA硬件上的运行效率。Jetson Xavier NX搭载了TensorRT,使得开发者能够轻松地将训练好的模型优化并部署到边缘设备上。
TensorRT优化模型的步骤包括模型解析、推理图优化、层融合、内核自动调优和执行计划生成。这些步骤可以在保持模型精度的同时,最大化利用Jetson Xavier NX上的GPU资源。
```python
import tensorrt as trt
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt_runtime = trt.Runtime(TRT_LOGGER)
def build_engine(onnx_file_path):
with trt.Builder(TRT_LOGGER) as builder, \
builder.create_network(common.EXPLICIT_BATCH) as network, \
trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 30 # 设置最大工作空间
builder.max_batch_size = 128 # 设置最大批量大小
with open(onnx_file_path, 'rb') as model:
if not parser.parse(model.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
return builder.build_cuda_engine(network)
# 将ONNX模型转换为TensorRT引擎
engine = build_engine('model.onnx')
# 将模型序列化到文件
with open('model.trt', 'wb') as f:
f.write(engine.serialize())
```
上面的代码片段展示了如何将一个ONNX格式的模型文件转换成TensorRT引擎,并将其序列化到文件中以供后续使用。该过程包括创建一个TensorRT运行时环境,解析ONNX模型文件,并构建一个TensorRT引擎。转换后的模型可以大大减少推理时间,这对于实时应用尤其重要。
在转换过程中,我们设置了最大工作空间和最大批量大小,这些参数根据具体的应用场景和硬件资源进行调整。构建引擎后,可以将优化后的模型保存为二进制格式,方便后续的加载和运行。
# 5. Jetson Xavier NX I/O与传感器集成
随着物联网和边缘计算的发展,设备与传感器的集成成为了智能系统的关键。Jetson Xavier NX作为一款边缘设备,提供多种I/O接口,能够方便地与各类传感器集成,用于收集和处理数据。本章节将详细介绍如何利用Jetson Xavier NX的I/O接口与各种传感器类型集成,以及如何进行实时数据处理与流媒体应用。
## 5.1 常用I/O接口与传感器类型
### 5.1.1 GPIO、I2C和SPI接口使用
Jetson Xavier NX提供了丰富的通用I/O接口,包括GPIO、I2C和SPI等,它们各自具有不同的特性和应用场景。
#### GPIO接口
GPIO(General-Purpose Input/Output)即通用输入输出端口,可以用来控制和接收来自外部设备的信号。Jetson Xavier NX提供了多达50个GPIO引脚,支持硬件PWM功能,能够满足多样化的控制需求。
```python
import Jetson.GPIO as GPIO
import time
# 设置GPIO模式为GPIO.BCM
GPIO.setmode(GPIO.BCM)
# 设置GPIO引脚编号
LED_PIN = 18
# 设置为输出模式
GPIO.setup(LED_PIN, GPIO.OUT)
# 循环闪烁LED灯
while True:
GPIO.output(LED_PIN, GPIO.HIGH) # LED ON
time.sleep(1)
GPIO.output(LED_PIN, GPIO.LOW) # LED OFF
time.sleep(1)
```
在上述Python代码中,我们首先导入了`Jetson.GPIO`模块,然后设置GPIO模式,并定义了LED灯连接的GPIO引脚。之后我们通过`GPIO.setup()`将引脚设置为输出模式,并在循环中控制LED灯的状态,实现闪烁效果。
#### I2C接口
I2C(Inter-Integrated Circuit)是一种串行通信总线,它允许多个“从”设备共享相同的两个线(数据线SDA和时钟线SCL)与一个或多个“主”设备进行通信。Jetson Xavier NX提供了I2C接口,可用于连接各种I2C设备,如温度传感器、加速度计等。
```python
import smbus
# 设置I2C总线号
bus = smbus.SMBus(1)
# I2C设备地址
device_address = 0x50
# 读取设备数据
data = bus.read_i2c_block_data(device_address, 0x00, 1)
# 解析数据
temperature = data[0] * 0.01
print("Temperature: " + str(temperature) + "C")
```
本代码使用了`smbus`库来访问I2C总线。首先创建了一个SMBus对象,然后通过`read_i2c_block_data()`函数从指定I2C地址的设备中读取数据。最后,将数据解析为实际的温度值并打印出来。
#### SPI接口
SPI(Serial Peripheral Interface)是一种高速的、全双工的、同步的通信总线,常用于连接微控制器和各种外围设备,如ADC(模拟数字转换器)、SD卡等。Jetson Xavier NX同样支持SPI接口。
```python
import spidev
import time
spi = spidev.SpiDev()
spi.open(0, 0)
# SPI通信配置
spi.max_speed_hz = 1000000
# 读写SPI设备数据
spi.xfer2([0xD4, 0x05, 0x00])
# 等待数据处理
time.sleep(0.1)
# 读取返回数据
read_data = spi.xfer2([0x00])
# 关闭SPI设备
spi.close()
```
在该段代码中,我们首先导入`spidev`模块,然后打开SPI设备。接下来设置SPI通信的最大速度,并通过`xfer2()`函数发送数据到SPI设备,同时读取返回的数据。最后关闭SPI设备。
### 5.1.2 视觉与距离传感器集成
视觉和距离传感器是智能设备获取外部信息的重要工具。Jetson Xavier NX能够与多种传感器集成,包括摄像头、激光测距仪等,实现图像识别、物体检测和环境感知等功能。
#### 摄像头集成
Jetson Xavier NX支持多种类型的摄像头,包括标准的CSI摄像头模块和USB摄像头。为实现CSI摄像头模块的集成,通常需要通过NVIDIA提供的驱动程序进行配置。
```bash
sudo nvpmodel -m 0 # 设置为最大性能模式
sudo jetson_clocks # 启用最大频率
sudo modprobe ov5693 # 加载摄像头驱动
```
首先通过`nvpmodel`命令将设备性能设置为最大模式,接着使用`jetson_clocks`启用最大频率,以保证摄像头的最高性能。之后加载摄像头驱动程序`ov5693`,此处以某个型号为例。
#### 激光测距仪集成
对于距离测量,激光测距仪是一种常见的选择。通过I2C或SPI接口与Jetson Xavier NX集成的激光测距仪,可以准确测量物体与设备之间的距离。
```python
# 假设使用的是VL53L0X激光测距仪,通过I2C接口连接
import VL53L0X
# 初始化激光测距仪
tof = VL53L0X.VL53L0X(i2c_bus=1, i2c_address=0x29)
# 开始测距
tof.start_ranging()
# 读取距离值
distance = tof.get_distance()
# 停止测距
tof.stop_ranging()
print("Distance: " + str(distance) + "mm")
```
本代码展示了如何通过Python代码使用`VL53L0X`库来控制VL53L0X激光测距仪进行距离测量。首先导入`VL53L0X`库,然后初始化激光测距仪,并开始测距。通过调用`get_distance()`函数读取当前距离值,并最终停止测距。
## 5.2 实时数据处理与流媒体
### 5.2.1 视频流的捕获与处理
视频流处理是边缘计算中的一大应用领域。Jetson Xavier NX可以同时捕获和处理多个视频流,这对于机器人视觉、监控系统等应用至关重要。
```python
import cv2
import numpy as np
import jetson.inference
import jetson.utils
# 初始化视频源(例如从CSI摄像头)
input = jetson.utils.videoSource("/dev/video0", argv=['--input-width=1920', '--input-height=1080'])
# 初始化视频输出
output = jetson.utils.videoOutput("display://0", argv=[':display=' + str(jetson.utils.getDisplayWidth()) + 'x' + str(jetson.utils.getDisplayHeight())])
# 加载检测模型
net = jetson.inference.detectNet("ssd-mobilenet-v2", threshold=0.5)
while True:
# 捕获视频流
img = input.Capture()
# 检测图像中的对象
detections = net.Detect(img)
# 处理检测结果
for detection in detections:
l = detection.Left()
t = detection.Top()
r = detection.Right()
b = detection.Bottom()
# 绘制检测框
img = jetson.utils.drawRect(img, l, t, r-l, b-t, color = (255,0,0), thickness=4, layer=1)
# 显示处理后的图像
output.Render(img)
output.Update()
```
在上述代码中,我们使用了`jetson.inference`和`jetson.utils`库来实现视频流的捕获和处理。首先,初始化视频源和视频输出,然后加载对象检测模型。在主循环中,我们不断捕获视频流图像,并使用加载的检测模型对图像进行处理,识别出图像中的物体。最后,绘制检测框,并通过视频输出显示处理后的图像。
### 5.2.2 机器人视觉系统的应用实例
机器人视觉系统通过集成摄像头、激光雷达等传感器,让机器人能够感知和理解周围环境,从而实现自主导航、物体识别、路径规划等功能。
```mermaid
graph LR
A[摄像头] -->|图像数据| B[Jetson Xavier NX]
B -->|处理结果| C[机器人控制系统]
C -->|导航指令| D[驱动单元]
D -->|执行动作| E[机器人行动]
```
在上述mermaid流程图中,我们展示了机器人视觉系统的工作流程。摄像头捕获图像数据,并发送到Jetson Xavier NX进行实时处理。处理后的结果通过机器人控制系统转化为导航指令,再由驱动单元执行,从而驱动机器人进行相应的行动。
例如,通过摄像头捕获的图像数据可以用于实时物体检测,Jetson Xavier NX中的深度学习模型可以对图像中的物体进行识别,并输出相应的类别和位置信息。机器人控制系统将这些信息转化为导航指令,如“避开前方障碍物”或者“跟踪指定目标”。驱动单元根据这些指令执行相应的动作,如转向、加速等,以实现自主导航和物体跟踪。
### 结语
本章通过介绍Jetson Xavier NX的I/O接口使用和传感器集成,展现了其在数据采集和实时处理方面的强大能力。从基础的GPIO、I2C、SPI接口到高级的视觉和距离传感器集成,以及视频流的处理,每一步都为构建复杂的机器人视觉系统和智能感知应用提供了支持。这些技术的应用使得Jetson Xavier NX成为边缘AI和物联网领域中的理想选择。
# 6. Jetson Xavier NX项目案例分析
## 6.1 边缘AI应用构建流程
### 6.1.1 从需求到部署的完整步骤
在这一部分,我们将探讨如何从识别特定项目需求到将边缘AI解决方案部署到Jetson Xavier NX硬件的完整流程。
#### 需求分析
首先,明确项目需求是构建任何解决方案的基础。对于边缘AI应用,需求可能包括但不限于:
- 实时性要求
- 精确度和准确度标准
- 硬件资源限制(如功耗、内存、存储)
- 环境因素(如温度、湿度)
在需求分析阶段,我们还需考虑应用的规模和可扩展性需求。
#### 技术选型
需求分析完成后,选择合适的技术栈至关重要。例如,NVIDIA的Jetson Xavier NX可提供强大的计算能力来运行复杂的深度学习模型,同时保持低功耗。还需要决定是否使用TensorFlow、PyTorch等流行的深度学习框架,以及决定是否使用CUDA和cuDNN等高性能计算库。
#### 系统设计
系统设计阶段涉及到软硬件的架构设计。在软件方面,确定软件模块划分、工作流程设计和数据流管理。在硬件方面,需要根据应用需求来设计电路、选择传感器和外围设备。
#### 开发与集成
接下来是编码和硬件集成阶段。利用NVIDIA提供的JetPack SDK进行系统软件开发,同时通过Jetson平台进行模型的训练、推理和优化。
#### 测试与优化
开发完成后,系统进入测试阶段。测试应包括单元测试、集成测试和性能测试。性能测试尤为重要,因为它可以揭示系统在实际工作环境下的性能表现。对系统进行调优,以确保满足预定的性能标准。
#### 部署
一旦测试和优化完成,最终部署阶段就到了。这个阶段涉及到将整个系统安装到目标设备中,并确保它在实际环境中运行稳定。
### 6.1.2 调试与性能评估
调试和性能评估是确保边缘AI应用质量的关键步骤。
#### 调试
调试过程通常涉及对系统各部分单独检查和错误修正。为了方便调试,开发者可能需要在Jetson Xavier NX上实现日志记录、状态监控和异常处理机制。
代码示例:
```python
import logging
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)
# 示例:记录调试信息
logger.debug("This is a debug message")
```
#### 性能评估
性能评估需要使用一些基准测试工具来测量CPU、GPU以及整体系统的性能。例如,可以使用NVIDIA提供的Nsight工具进行性能分析。性能评估结果将指导我们进行进一步的优化工作。
## 6.2 创新项目案例展示
### 6.2.1 智能视频监控系统
在智能视频监控系统案例中,我们利用Jetson Xavier NX平台实现高效视频数据的实时处理。系统能够识别和跟踪对象,以及根据预设规则进行异常事件的自动报警。
#### 功能实现
该系统具备以下几个关键功能:
- 实时视频流捕获与处理
- 对象检测和识别
- 运动跟踪和行为分析
#### 技术亮点
- 使用TensorRT进行模型优化,显著提高推理速度
- 结合深度学习模型,如YOLO、SSD等,用于高效的对象检测
- 利用NVIDIA的Jetson平台进行端到端部署
### 6.2.2 自主导航机器人
自主导航机器人项目展示了如何在Jetson Xavier NX上实现复杂的自主导航和决策系统。
#### 功能实现
- 使用多种传感器进行环境感知
- 利用AI算法实现路径规划和避障
- 实现机器人与环境的交互
#### 技术亮点
- 集成多种传感器数据,如视觉、激光雷达(LIDAR)和超声波传感器
- 使用深度学习进行环境建模和地图创建
- 实时决策算法让机器人在复杂环境中自主移动
通过上述案例的分析,我们可以看到Jetson Xavier NX在边缘AI应用中的巨大潜力。从智能视频监控到自主导航机器人,NVIDIA Jetson平台为我们提供了一个强大而灵活的硬件基础,搭配相应的软件和算法,能够在多样化的项目中发挥重要作用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏围绕 Jetson Xavier NX 展开,提供全面的技术指南。从操作系统部署到编程入门,再到机器视觉应用、性能优化、电源管理和散热解决方案,专栏涵盖了开发人员和工程师在使用 Jetson Xavier NX 时所需了解的一切。通过深入浅出的讲解和实用的教程,本专栏旨在帮助读者快速掌握 Jetson Xavier NX 的使用,从而充分发挥其在边缘 AI 应用中的强大潜力。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PHPWord:自动化交叉引用与目录】:一键生成文档结构

# 摘要
本文详细介绍了PHPWord库在处理Word文档时的基础和高级功能,覆盖了从基础文档结构的概念到自动化文档功能的实现。文章首先阐述了PHPWord的基本使用,包括文档元素的创建与管理,如标题、段落、图片、表格、列表和脚注。随后,深入讨论了自动化交叉引用与目录生成的方法,以及如何在实际项目中运用P
伺服电机调试艺术:三菱MR-JE-A调整技巧全攻略

# 摘要
伺服电机在现代自动化和机器人技术中发挥着核心作用,其性能和稳定性对于整个系统的运行至关重要。本文从伺服电机的基础知识和调试概述开始,详细介绍了三菱MR-JE-A伺服驱动器的安装步骤、
深入STM32 PWM控制:5大策略教你高效实现波形调整
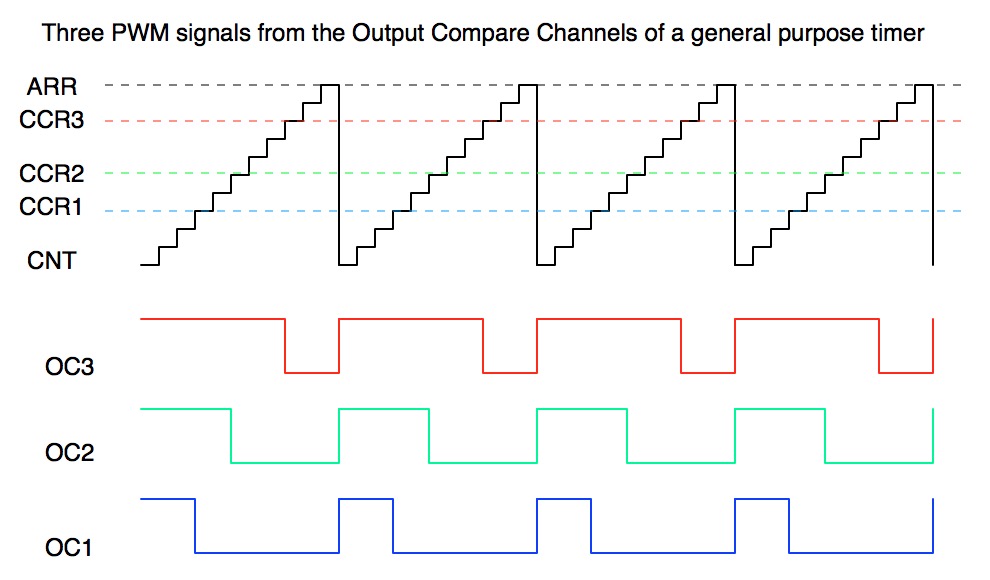
# 摘要
PWM(脉冲宽度调制)控制技术是微控制器应用中一种重要的信号处理方法,尤其在STM32微控制器上得到了广泛应用。本文首先概述了PWM控制的基本概念,介绍了PWM的工作原理、关键参数以及与微控制器的交互方式。接着,本文深入探讨了PWM波形调整的实践技巧,包括硬件定时器配置、软件算法应用,以及调试与优化的策略。文章进一步阐述了PWM控制在进阶应用中的表现,如多通道同步输出
版本控制基础深度解析:项目文档管理演进全攻略
# 摘要
版本控制作为软件开发过程中的核心组成部分,确保了代码的有序管理与团队协作的高效性。本文首先概述了版本控制的重要性,并对其理论基础进行了详细解析,包括核心概念的定义、基本术语、分类选择以及工作流程。随后,文章提供了针对Git、SVN和Mercurial等不同版本控制系统的基础操作指南,进一步深入到高级技巧与应用,如分支管理策
【Flac3D命令进阶技巧】:工作效率提升的7大秘诀,专家级工作流
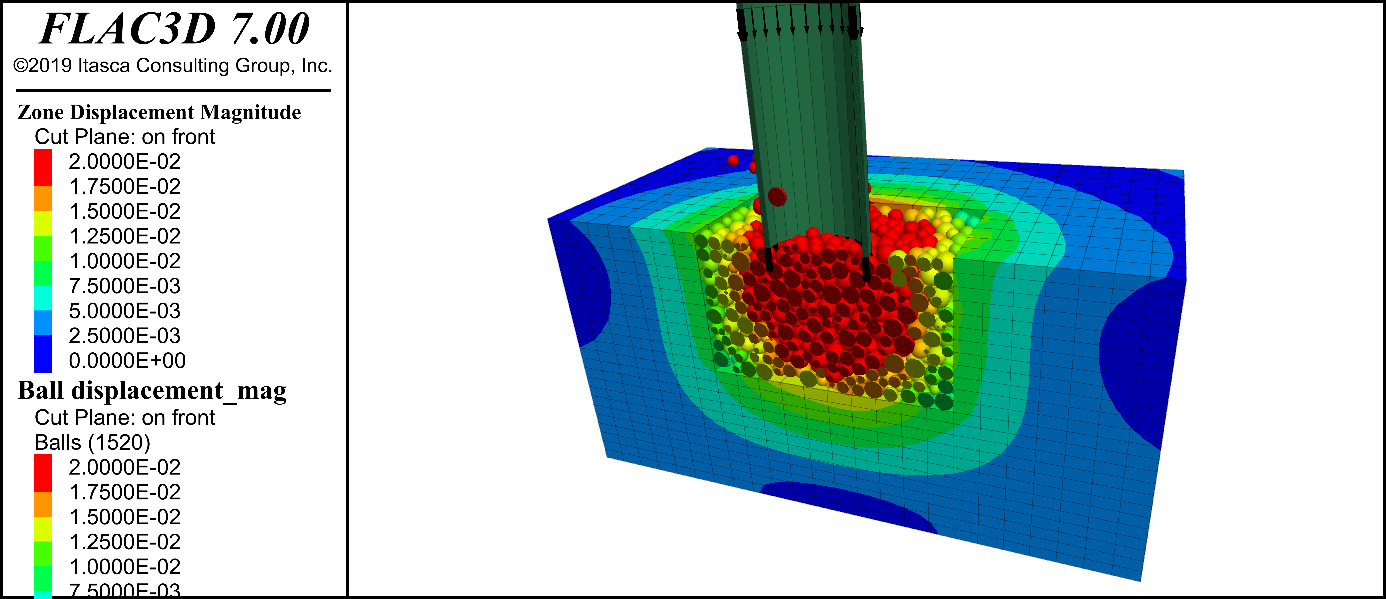
# 摘要
本文详细探讨了Flac3D命令的高级功能及其在工程建模与分析中的应用。首先,文章介绍了Flac3D命令的基本与高级参数设置,强调了参数定义、使用和效果,以及调试和性能优化的重要性。其次,文章阐述了通过Flac3D命令建立和分析模型的过程,包括模型的建立、修改、分析和优化方法,特别是对于复杂模型的应用。第三部分深入探讨了Flac3D命令的脚本编程、自定义功能和集成应用,以及这些高级应用如何提高工作效率和分析准确性。最后,文章研究了Flac3D命令
【WPS与Office转换PDF实战】:全面提升转换效率及解决常见问题

# 摘要
本文综述了PDF转换技术及其应用实践,涵盖从WPS和Office软件内直接转换到使用第三方工具和自动化脚本的多种方法。文章不仅介绍了基本的转换原理和操作流程,还探讨了批量转换和高级功能的实现,同时关注转换
犯罪地图分析:ArcGIS核密度分析的进阶教程与实践案例

# 摘要
犯罪地图分析是利用地理信息系统(GIS)技术对犯罪数据进行空间分析和可视化的重要方法,它有助于执法机构更有效地理解犯罪模式和分布。本文首先介绍了犯罪地图分析的理论基础及其重要性,然后深入探讨了ArcGIS中的核密度分析技术,包括核密度估计的理论框架、工具操作以及高级设置。随后,文章通过实践应用,展现了如何准备数据、进行核密度分析并应用于实际案例研究中。在此基础上,进一
【Tetgen实用技巧】:提升你的网格生成效率,精通复杂模型处理

# 摘要
Tetgen是一款功能强大的网格生成软件,广泛应用于各类工程和科研领域。本文首先介绍了Tetgen的基本概念、安装配置方法,进而解析了其核心概念,包括网格生成的基础理论、输入输出格式、主要功能模块等。随后,文章提供了提升Tetgen网格生成效率的实用技巧,以及处理复杂模型的策略和高级功能应用。此外,本文还探讨了Tetgen在有限元分析、计算
【MOSFET开关特性】:Fairchild技术如何通过节点分布律优化性能
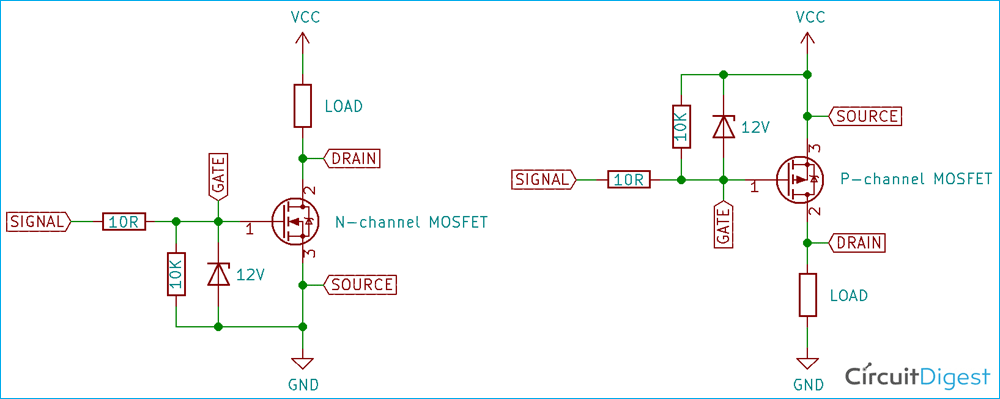
# 摘要
本文深入探讨了MOSFET开关特性的基础理论及其在Fairchild技术中的应用,重点分析了节点分布律在优化MOSFET性能中的作用,包括理论基础和实现方法。通过对比Fairchild技术下的性能数据和实际应用案例研究,本文揭示了节点分布律如何有效提升MOSFET的开关速度与降低功耗。最后,本文展望了MOS
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )