性能提速不二法门:8051指令效率终极分析与优化技巧
发布时间: 2024-12-15 14:19:02 阅读量: 4 订阅数: 9 

UI设计提速秘笈:PhotoshopCC使用技巧
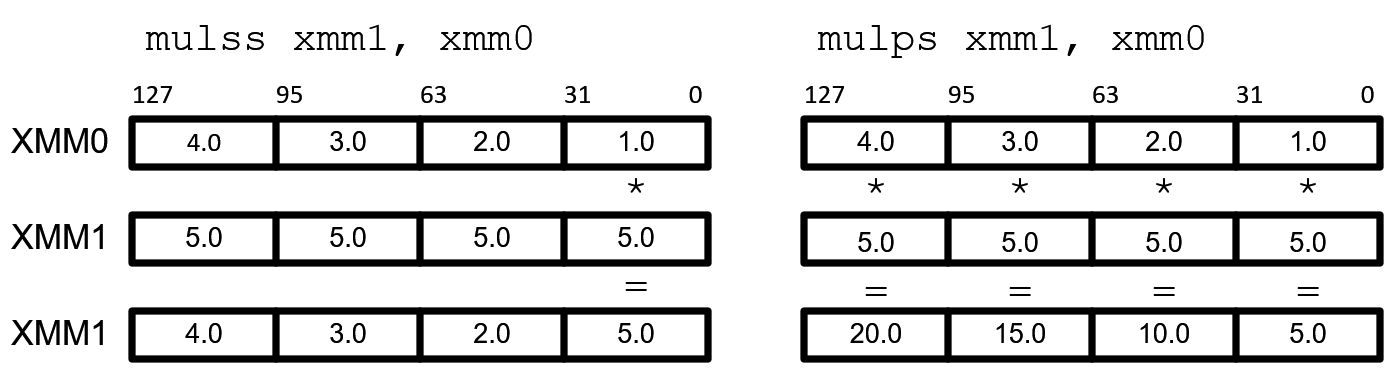
参考资源链接:[8051指令详解:111个分类与详细格式](https://wenku.csdn.net/doc/1oxebjsphj?spm=1055.2635.3001.10343)
# 1. 8051微控制器概述
## 1.1 8051微控制器简介
8051是一款经典的单片机,由Intel公司在1980年代初期推出,标志着微控制器(MCU)时代的开始。它具备8位CPU核心,拥有一个相对简单的指令集,并能够直接控制外设。8051微控制器因其设计简单、稳定性高和成本低廉等特点,在工业控制、家用电器和嵌入式系统等领域得到了广泛的应用。
## 1.2 架构特点
8051微控制器的核心是一个8位的处理器,内置RAM和ROM/OTP/Flash存储器,提供了丰富的接口如I/O端口、定时器/计数器、串行通信接口等。它通常采用哈佛架构,这意味着程序存储器和数据存储器是分开的。这种分离的设计允许同时读取指令和操作数据,从而提高性能。
## 1.3 应用场景
由于8051架构的灵活性和可靠性,它被广泛应用于多种场景。从简单的家电控制器到复杂的工业自动化系统,8051微控制器都能够胜任。此外,它的低功耗特点使得它非常适合于电池供电的便携式设备。随着技术的演进,8051的许多变种已经发展出来,以满足特定应用的需求。
```mermaid
graph TD
A[8051微控制器] --> B[家用电器]
A --> C[工业控制系统]
A --> D[数据采集与处理]
A --> E[教育和培训]
```
在接下来的章节中,我们将深入探讨8051的指令集基础、程序设计效率提升以及硬件加速技巧,以期读者能够更加全面地掌握8051微控制器的应用。
# 2. 8051指令集基础
## 2.1 指令集架构与分类
### 2.1.1 数据传输指令
数据传输指令是8051指令集中最常用也是最基础的指令之一,用于在寄存器、内存和I/O端口之间移动数据。了解这些指令对于编写高效的8051程序至关重要。
在数据传输指令中,有一条非常重要的指令是`MOV`,它有多种形式用于不同的操作。例如,从寄存器到寄存器、寄存器到内存、立即数到寄存器等。
```assembly
; 将寄存器R0的值移动到寄存器R1
MOV R1, R0
; 将立即数0x30移动到累加器A
MOV A, #30H
; 将累加器A的值存储到外部数据内存地址0x2000
MOVX @DPTR, A
```
### 2.1.2 算术运算指令
算术运算指令用于执行各种算术计算,包括加法、减法、乘法、除法以及递增、递减等操作。这些操作对数据处理和逻辑判断有直接影响。
以`ADD`和`SUBB`指令为例,它们分别用于加法和带借位的减法操作:
```assembly
; 将寄存器R0的值加到累加器A中
ADD A, R0
; 从累加器A中减去寄存器R1的值,并考虑之前的借位
SUBB A, R1
```
## 2.2 指令周期与时序分析
### 2.2.1 指令周期概念
指令周期是指执行一条指令所需要的完整时间,它包括取指令、解码指令和执行指令这三个阶段。了解指令周期对于理解程序的执行效率至关重要。
在8051微控制器中,不同的指令可能会有不同的执行周期。例如,一条简单的数据传输指令可能只需一个机器周期,而复杂的乘除法指令可能需要多个机器周期。
### 2.2.2 各类指令的时序特点
每种指令的时序特点是由微控制器的设计决定的。在8051中,时序表是一个重要的参考,它详细记录了每条指令的周期数。
例如,`MOV`指令通常执行需要1个机器周期,而`MUL AB`(无符号乘法)指令则需要4个机器周期。
```markdown
| 指令 | 机器周期数 |
|----------|------------|
| MOV A, R0| 1 |
| MUL AB | 4 |
```
## 2.3 寻址模式解析
### 2.3.1 寻址模式概述
寻址模式定义了数据被取到CPU的方式。8051指令集支持多种寻址模式,它们包括立即寻址、直接寻址、间接寻址、寄存器寻址和相对寻址等。
每种寻址模式都有其特定的用途和效率考量。例如,寄存器寻址通常比直接寻址更快,因为寄存器位于CPU内部。
### 2.3.2 常见寻址模式的效率分析
让我们分析一下几种常见的寻址模式:
- **立即寻址**:操作数直接包含在指令中,效率较高,因为它不需要访问内存。
- **直接寻址**:通过指定内存地址直接访问数据,效率较直接寻址低,但比间接寻址快,因为它不需要额外的内存访问。
- **间接寻址**:使用寄存器的值作为地址来访问内存中的数据,通常是最慢的寻址方式,因为它涉及到两次内存访问。
```assembly
; 立即寻址:立即数0x55直接加到累加器A
MOV A, #55H
; 直接寻址:将地址为0x30的内存内容加载到累加器A
MOV A, 30H
; 间接寻址:寄存器R0包含一个内存地址,使用该地址来访问内存
MOV A, @R0
```
在编写8051程序时,合理选择和使用寻址模式可以显著提高代码的执行效率和性能。
# 3. 8051程序设计效率提升
## 3.1 程序结构优化
### 3.1.1 函数/子程序的设计与优化
函数或子程序是程序模块化设计的核心,合理的设计不仅可以提高代码的可读性,还能在某些情况下提升程序的执行效率。在8051程序设计中,函数设计应注意以下几点:
- **函数参数传递:** 函数参数应当尽量少,尤其是在内存有限的嵌入式系统中,避免不必要的参数传递可以减少数据的移动次数。
- **局部变量的使用:** 局部变量存储在栈中,访问速度相对快于全局变量。合理利用局部变量,可以减少对全局变量的访问,提升执行效率。
- **函数内联:** 对于很小的函数,可以考虑使用内联的方式来避免函数调用的开销。编译器通常会提供内联函数的选项,允许开发者对特定函数指定内联。
### 3.1.2 循环结构的优化技巧
循环是程序中频繁使用的结构之一,其性能直接影响到整个程序的效率。以下是一些循环优化的技巧:
- **循环展开:** 通过减少循环的迭代次数来减少循环控制开销。例如,将一个每次迭代处理两个数据项的循环,修改为每次迭代处理四个数据项,以减少循环次数。
- **条件判断优化:** 将循环中的条件判断尽可能地移到循环外部。比如,预先检查循环迭代的条件,从而避免在循环内部进行不必要的计算。
- **循环展开与尾调用:** 优化循环结构,结合尾调用优化(tail call optimization),在循环的最后直接跳转到函数的开始处,避免额外的函数调用开销。
## 3.2 数据操作优化
### 3.2.1 内存访问的优化策略
在8051中,内存操作往往比寄存器操作更耗时,因此优化内存访问是提升效率的关键:
- **缓冲区操作:** 对于需要连续访问的内存数据,可以使用缓冲区来减少访问次数,例如一次性读取或写入一定长度的数据到缓冲区,再进行处理。
- **数据对齐:** 确保数据访问是对齐的,避免因数据不对齐造成的额外处理周期。在8051中,由于硬件特性,某些对齐方式可提升访问效率。
- **局部性原理:** 利用程序的局部性原理,将常用数据或频繁访问的数据尽量存储在易于快速访问的地方,如内部RAM。
### 3.2.2 变量与寄存器的有效管理
寄存器是8051中最快速的存储资源,高效利用寄存器对于性能至关重要:
- **寄存器分配:** 在编译时,尽可能将频繁使用的变量分配到寄存器中,减少对内存的访问。
- **寄存器变量:** 在函数中可以使用关键字`register`声明局部变量,建议编译器尽可能地将这些变量放在寄存器中。
- **寄存器溢出处理:** 明智地选择哪些变量应该放在寄存器中,并在必要时使用寄存器溢出策略,例如通过寄存器窗口技术减少保存和恢复寄存器的次数。
## 3.3 编译器优化选项
### 3.3.1 编译器优化级别与效果
不同的编译器提供不同的优化选项,合理的使用这些选项可以有效提升程序的执行效率:
- **基础优化:** 对于较慢的编译器优化设置,它通常包括去除冗余代码、优化简单的循环等基础操作。
- **高级优化:** 高级优化选项可能涉及更复杂的优化技术,比如循环展开、内联函数优化等。
- **优化开销与性能权衡:** 某些高级优化可能会带来较大的编译开销,并可能增加程序的体积。因此,需要权衡优化带来的性能提升和资源消耗。
### 3.3.2 高级编译器优化技术
一些高级编译器优化技术可以显著提升8051程序的执行效率,包括:
- **数据流分析:** 编译器通过数据流分析来优化寄存器的使用,识别出哪些变量是活跃的,以及它们的生命周期,避免寄存器的浪费。
- **公共子表达式消除:** 对于在代码块中多次出现的相同计算,编译器可以将其保存在一个变量中,避免重复计算。
- **死代码消除:** 移除那些永远不会被执行到的代码,比如一些在特定条件下才会执行的代码块,如果这些条件永远不会满足。
通过上述讨论,我们了解了优化8051程序设计的多种方法,从程序结构到数据操作,再到编译器选项的深度应用。这些策略不仅能够帮助设计出更加优雅和高效的代码,还能确保在有限的硬件资源下最大限度地发挥8051微控制器的潜力。
# 4. 8051硬件加速技巧
## 4.1 外部硬件接口优化
### 4.1.1 I/O口的高效利用
在8051微控制器中,I/O口是与外部世界交互的主要通道。优化I/O口的使用能够显著提升硬件接口的响应速度与数据吞吐量。对于I/O口的操作,应当遵循以下几点策略:
- **最小化延迟**:减少在数据交换时的等待时间,对于一些快速设备,延迟可能成为瓶颈。
- **批处理操作**:当需要进行多个I/O操作时,尽量采用批处理,以减少对I/O口的频繁访问。
- **I/O口配置**:合理配置I/O口的模式,如推挽或开漏输出,输入或输出,这取决于外部设备的要求。
接下来,我们通过一个具体的代码示例来看如何高效利用I/O口。
```c
#include <reg51.h> // 包含8051寄存器定义的头文件
void IOLowLatency() {
// 假设P1为外设连接端口,P2为控制端口
P1 = 0xFF; // 将P1端口全部置高
P2 &= 0xFE; // 通过P2端口控制某外设使能
// ... 进行I/O操作
P2 |= 0x01; // 关闭外设使能
P1 = 0x00; // 将P1端口全部置低
}
```
### 4.1.2 外部中断的响应优化
外部中断提供了一种快速响应外部事件的机制。优化外部中断响应不仅包括中断服务例程的编写,还包括中断优先级的合理设置。以下是一些关键点:
- **快速中断服务例程**:编写尽量短小的中断服务例程,以减少中断响应时间。
- **中断屏蔽与优先级**:合理设置中断优先级和屏蔽,确保高优先级中断得到快速处理。
```c
void External0_ISR(void) interrupt 0 { // 外部中断0的中断服务例程
// 处理中断相关操作
// ...
// 必要时可以重新配置中断优先级
// ...
}
```
## 4.2 定时器/计数器使用技巧
### 4.2.1 定时器/计数器模式选择与应用
8051微控制器提供了定时器/计数器模块,用于生成定时事件或对事件进行计数。选择合适的模式对于实现硬件加速至关重要:
- **定时模式**:用于生成定时中断,可以用于时间基准或周期性任务的触发。
- **计数模式**:用于对外部事件进行计数,如脉冲宽度测量或频率计数。
```c
void Timer0_Init() {
TMOD = 0x01; // 设置定时器0为模式1 (16位定时器)
TH0 = (65536 - 50000) / 256; // 设置定时器高位值
TL0 = (65536 - 50000) % 256; // 设置定时器低位值
ET0 = 1; // 使能定时器0中断
TR0 = 1; // 启动定时器0
}
```
### 4.2.2 高效的定时事件触发
要实现高效的定时事件触发,需要做好定时器的初始化配置。关键在于选择正确的预分频值和设置适当的计数值,以适应应用需求。
```c
void Timer1_Init() {
TMOD |= 0x10; // 设置定时器1为模式1 (16位定时器) 并且为自动重装载模式
TH1 = 0xFF; // 设置定时器高位值
TL1 = 0xFF; // 设置定时器低位值
ET1 = 1; // 使能定时器1中断
TR1 = 1; // 启动定时器1
}
```
## 4.3 存储器管理策略
### 4.3.1 Flash和RAM的存储管理
合理管理内部Flash和RAM存储器对于提升微控制器性能至关重要。以下是一些优化技巧:
- **避免频繁擦写Flash**:因为Flash的写入次数是有限的,应尽量减少对Flash的直接写操作,使用RAM作为缓存。
- **RAM访问优化**:确保对RAM的访问是高效的,包括数据结构的设计,以及避免碎片化。
```c
// 示例:使用RAM作为临时存储来减少Flash的擦写次数
#define BUFFER_SIZE 32
unsigned char buffer[BUFFER_SIZE];
void ProcessData() {
unsigned char i;
// 处理数据,并存储到RAM缓冲区
for (i = 0; i < BUFFER_SIZE; ++i) {
buffer[i] = ...; // 数据处理过程
}
// 在适当的时候,将数据批量写入Flash
// ...
}
```
### 4.3.2 EEPROM高效编程技术
对于EEPROM,由于它通常用于存储非易失性配置数据或小量日志信息,提高写入效率显得尤为重要。
```c
void EEPROM_Write(unsigned char address, unsigned char data) {
// 配置EEPROM地址
// ...
// 写入数据到EEPROM
// ...
// 等待EEPROM写入完成(通常需要一定的延时)
// ...
}
```
EEPROM的写入通常包含发送特定的命令序列,以及在写入完成前进行延时等待。合理设计EEPROM写入协议,可以提高数据处理效率。
请注意,以上示例代码仅为说明使用技巧,并未包含所有优化细节,实际应用时还需根据具体情况进行调整。
# 5. 8051性能测试与调优实战
## 5.1 性能测试方法论
性能测试对于理解微控制器的运行效率至关重要。在进行性能测试时,我们需要有一个清晰的方法论来指导我们的操作。
### 5.1.1 基准测试与性能指标
基准测试是衡量系统性能的一种手段,通过一系列标准化的测试程序来获得性能数据。对于8051微控制器,常见的性能指标包括:
- 指令执行速度:通常以每秒执行的指令数(MIPS)为单位。
- 中断响应时间:从中断发生到中断服务程序开始执行的时间。
- 内存访问时间:CPU访问内部或外部存储器所花费的时间。
### 5.1.2 性能瓶颈的识别与分析
性能瓶颈是阻碍系统运行效率的主要障碍。在8051微控制器中,性能瓶颈可能出现在以下几个方面:
- I/O操作:频繁的外部设备访问可能导致CPU资源空闲等待。
- 内存管理:不当的内存使用策略会增加内存访问时间。
- 电源管理:电源管理不当会导致微控制器性能不稳定。
## 5.2 实际案例分析
通过实际案例分析,我们可以更好地理解性能测试和调优的过程。
### 5.2.1 典型应用的性能分析案例
考虑一个基于8051微控制器的温度监测系统。在这个系统中,CPU需要定时读取温度传感器的数据,并将其存储或通过串口输出。
- **性能指标评估**:在这个案例中,我们可能会发现数据处理时间是主要的性能瓶颈,因为CPU需要对读取的数据进行解析和转换。
- **瓶颈识别**:通过对系统运行的跟踪分析,我们可能确定数据解析过程中的某些算法可以优化。
### 5.2.2 性能优化实施步骤与效果评估
性能优化的实施步骤可能包括:
1. **代码剖析**:使用性能分析工具来找出CPU消耗最大的部分。
2. **算法优化**:选择更高效的算法来替换当前的实现。
3. **硬件调整**:如果软件优化已经达到瓶颈,可以考虑升级硬件或调整硬件设置。
**效果评估**:优化后,我们可以通过相同的基准测试来评估效果。优化的目标是减少数据处理时间,并提高系统的实时响应能力。
## 5.3 高级调试技巧
调试是性能测试和优化过程中的重要环节。掌握高级调试技巧可以帮助我们更有效地监控性能和诊断问题。
### 5.3.1 使用调试工具进行性能监控
调试工具通常提供各种性能监控的功能,例如:
- **时序分析**:可视化CPU和外设的时序关系。
- **资源使用率**:显示CPU和存储资源的使用率。
- **中断跟踪**:监控中断的发生和处理情况。
### 5.3.2 调试过程中的性能问题诊断
在调试过程中,性能问题的诊断需要对系统的运行状态有深入的理解。具体操作包括:
- **设置断点和监视点**:在关键代码行或数据上设置断点和监视点。
- **使用逻辑分析仪**:对微控制器的信号进行实时捕捉和分析。
- **运行时数据采集**:在运行时收集各种性能相关数据,如执行时间、中断响应时间等。
通过这些高级调试技巧,我们可以有效地识别并解决性能问题,进而对系统进行针对性的调优。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【编程更亲切】:GoLand设置中文全攻略
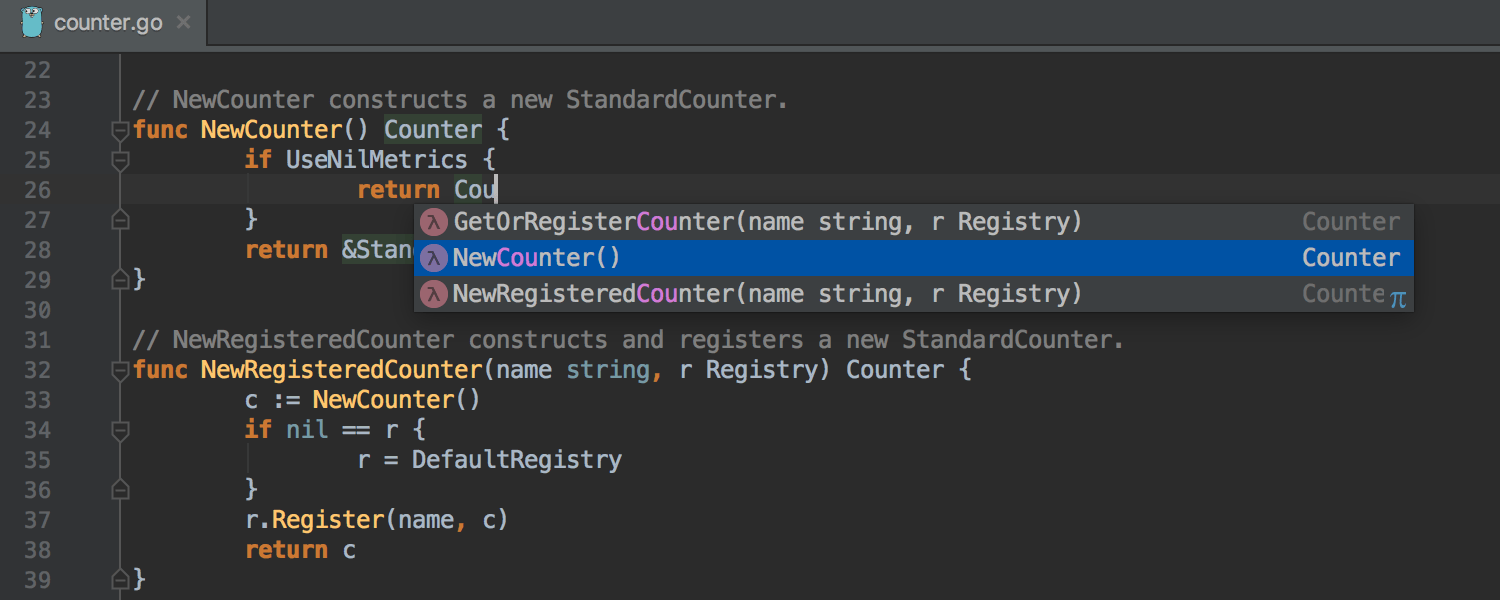
参考资源链接:[GoLand中文设置教程:在线与离线安装步骤](https://wenku.csdn.net/doc/645105aefcc5391368ff158e?spm=1055.2635.3001.10343)
# 1. Goland介绍与安装
## 1.1 Goland概述
GoLand是由JetBrains公司开发的专为Go语言编写的集成开发环境(IDE)。它提供了智能代码补全、代码分析
【电力系统故障模拟】:PowerWorld Simulator中电网故障与恢复的实战案例
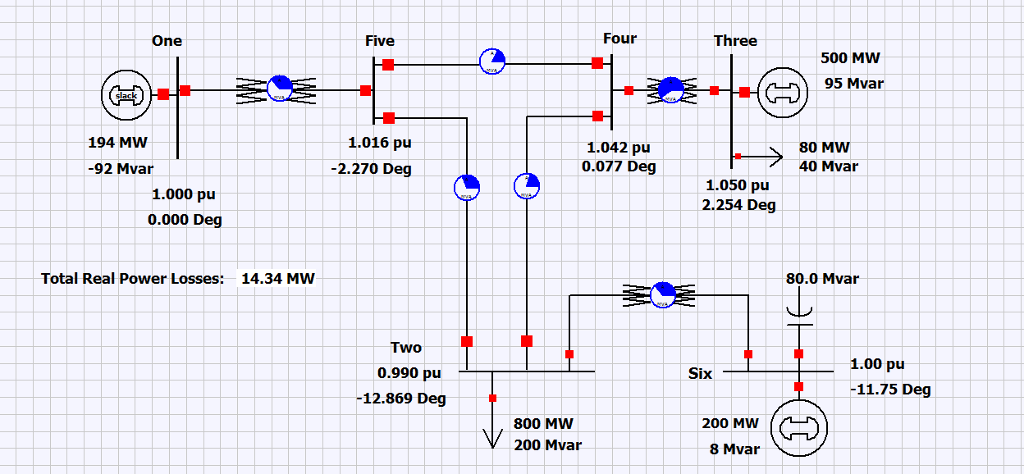
参考资源链接:[PowerWorld Simulator中文手册:电力系统建模与分析教程](https://wenku.csdn.net/doc/6401abe7cce7214c316e9ec1?spm=1055.2635.3001.10343)
# 1. 电力系统故障模拟概述
电力系统故障模拟是电力工程领域一项重要的技术,它能够帮
【立即掌握】:12个实用技巧,精通ISO 22900-2-2017与D-PDU-API的完美融合

参考资源链接:[ISO 22900-2 D-PDU API详解:MVCI协议与车辆诊断数据传输](https://wenku.csdn.net/doc/4svgegqzsz?spm=1055.2635.3001.10343)
# 1. ISO 22900-2-2017
技术革新者速成:掌握Ambarella H22芯片的编程与功耗控制秘诀

参考资源链接:[Ambarella H22芯片规格与特性:低功耗4K视频处理与无人机应用](https://wenku.csdn.net/doc/6401abf8cce7214c316ea27b?spm=1055.2635.3001.10343)
# 1. Ambarella H22芯片概述及架构解析
## 1.1
【ADS差分滤波器原理与实践】:实现理论到实际的无缝转换
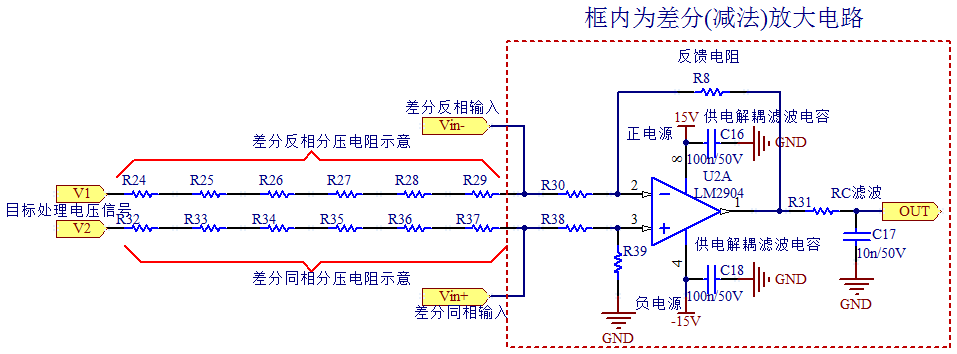
参考资源链接:[ads 差分滤波器设计及阻抗匹配](https://wenku.csdn.net/doc/6412b59abe7fbd1778d43bd8?spm=1055.2635.3001.10343)
# 1. ADS差分滤波器的基础理论
在通信系统中,差分滤波器扮演着至关重要的角色。差分滤波器能够有效地处理差分信号,保证信号在传输过程中的稳定性和抗干扰能力。本章将重点介绍ADS差分滤波器的基础理论,为后续的设计、
【CDO进阶应用】:CDO高级命令解析与实战演练

参考资源链接:[CDO气候数据操作命令详解:文件信息、合并、裁剪与插值](https://wenku.csdn.net/doc/1dcuhj0aue?spm=1055.2635.3001.10343)
# 1. CDO的基本概念和功能介绍
CDO(Climate Data Operators)是一个集合了多种命令行工具的集合,这些工具被设计用于处理气候数据。虽然它最初是为
【高性能计算中的GPGPU应用】:实战案例深度解析

参考资源链接:[GPGPU编程模型与架构解析:CUDA、OpenCL及应用](https://wenku.csdn.net/doc/5pe6wpvw55?spm=1055.2635.3001.10343)
# 1. GPGPU技术概述
## 1.1 GPGPU的定义和重要性
GPGPU,即通用计算图形处理器,是一种利用图形处理单
从LibreOffice 6到7.1.8升级全解析:技术细节与实用指南
参考资源链接:[ARM架构下libreoffice 7.1.8预编译安装包](https://wenku.csdn.net/doc/2fg8nrvwtt?spm=1055.2635.3001.10343)
# 1. LibreOffice升级概览
LibreOffice作为一款流行的开源办公套件,持续不断地进行版本迭代以提升用户体验和性能。在本章节,我们将概述LibreOffice的升级流程,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )