新手必读:深入掌握urllib库,提升Python网络请求效率
发布时间: 2024-10-04 13:51:05 阅读量: 4 订阅数: 13 

# 1. Python网络编程基础介绍
## 1.1 网络编程概述
### 1.1.1 网络编程的基本概念
网络编程是使应用程序能够通过网络进行通信的技术。在Python中,开发者能够利用套接字(sockets)创建客户端和服务器来交换数据,这些数据可以是文本、二进制文件或其他形式的数据流。
### 1.1.2 Python中的网络编程模块
Python提供了多个模块来支持网络编程,如`socket`、`http.client`和`asyncio`。`socket`模块是低级别的网络编程接口,而`http.client`提供了高级别的HTTP支持。对于高级网络应用,如异步IO,`asyncio`模块提供了一套完整的工具集。
## 1.2 HTTP协议基础
### 1.2.1 请求和响应的结构
HTTP协议是基于请求-响应模型的协议。一个HTTP请求包含方法、路径、协议版本、头部信息和可选的主体部分。响应包含状态码、响应头和主体内容。典型的请求和响应结构如下:
```
GET /index.html HTTP/1.1
Host: ***
HTTP/1.1 200 OK
Content-Type: text/html
<html>...</html>
```
### 1.2.2 常用的HTTP请求方法
HTTP定义了一组请求方法来指示对资源执行的操作,包括但不限于GET、POST、PUT、DELETE、HEAD和OPTIONS。GET用于获取资源,POST用于提交数据,而PUT用于更新资源,DELETE用于删除资源。
## 1.3 理解Python中的urllib模块
### 1.3.1 urllib模块的历史与作用
urllib是Python的内置库,用于处理URLs。它提供了一系列用于操作URL的功能,包括URL编码、HTTP请求的发送以及下载文件等。urllib是进行Web编程不可或缺的工具之一,特别是在爬虫和Web自动化测试中。
### 1.3.2 urllib与其他Python网络库的比较
与urllib相比,`requests`库提供了更简洁易用的API,是处理HTTP请求的首选第三方库。而`urllib`更多用于学习目的或者在需要与底层HTTP协议更细致交互的场景中。由于urllib是标准库的一部分,它不依赖于第三方,这使其在部署时更为方便。
[下章预告:第二章将深入探讨urllib库的核心组件及其工作原理,我们将从urllib.request模块开始,一步步解析各个组件的功能与用法。]
# 2. urllib库的核心组件解析
### 2.1 urllib.request模块
#### 2.1.1 创建URL请求对象
使用urllib库发起网络请求的第一步,是创建一个URL请求对象。`urllib.request`模块提供了`Request`类,允许开发者自定义请求的各个方面。例如,可以设置请求头、请求方法等。创建请求对象的代码示例如下:
```python
from urllib import request
url = "***"
req = request.Request(url)
# 这里可以对req进行更多的配置,如req.add_header()添加请求头
with request.urlopen(req) as response:
data = response.read()
```
在上述代码中,`urlopen`方法被用来发送请求并读取响应内容。这是一个高级接口,简单直接。
#### 2.1.2 处理HTTP响应内容
获取HTTP响应内容是网络请求的核心部分。urllib返回的响应对象是类似于文件的对象,这使得处理起来非常直观。通过`read`方法可以读取响应的全部内容,或者使用`readline`和`readlines`方法逐行读取。例如:
```python
with request.urlopen(req) as response:
# 直接读取全部内容
content = response.read()
# 逐行读取内容
for line in response.readlines():
print(line.decode('utf-8'))
```
在处理HTTP响应时,可能需要检查HTTP响应码来确认请求是否成功,或根据响应内容做出进一步处理。
### 2.2 urllib.error模块
#### 2.2.1 处理urllib引发的异常
网络编程中不可忽视的是错误处理。urllib库会抛出若干种异常,如`URLError`和`HTTPError`。这些异常提供了对错误的详细信息,使得程序可以优雅地处理问题。一个异常处理的示例如下:
```python
from urllib import request, error
try:
response = request.urlopen(req)
except error.URLError as e:
print(f"请求遇到问题,原因是:{e.reason}")
except error.HTTPError as e:
print(f"服务器返回了状态码:{e.code}")
```
异常处理不仅有助于程序的健壮性,还能够提供错误日志以便于问题的调试和定位。
### 2.3 urllib.parse模块
#### 2.3.1 URL的解析与构建
在处理复杂的URL时,`urllib.parse`模块是非常有用的工具。它可以将URL分解成多个组成部分(如协议、主机名、路径等),也可以将这些部分重新组合成完整的URL。例如:
```python
from urllib.parse import urlparse, urlunparse
parsed_url = urlparse(url)
print(parsed_url.scheme) # 协议部分
print(parsed_***loc) # 网络位置部分
# 构建新的URL
new_url = urlunparse(parsed_url._replace(path="/new_path"))
print(new_url)
```
通过上述代码,可以实现对URL的解析和重构,有利于进行URL的规范化和验证等操作。
#### 2.3.2 查询字符串的解析与编码
在构建带有查询参数的URL时,必须确保查询字符串被正确编码。urllib的`parse`模块也提供了方便的方法来处理查询字符串。例如:
```python
from urllib.parse import urlencode, parse_qs, urljoin
# 使用urlencode编码查询字符串
query_params = {"name": "Alice", "age": 30}
encoded_query = urlencode(query_params, doseq=True)
full_url = urljoin(base_url, f"?{encoded_query}")
print(full_url)
# 解析查询字符串
print(parse_qs(encoded_query))
```
这种方法的使用可以简化对URL查询参数的操作,并确保编码符合网络请求的标准要求。
### 2.4 urllib.robotparser模块
#### 2.4.1 了解robots.txt协议
robots.txt协议定义了搜索引擎爬虫对于网站哪些部分可以抓取,哪些部分不可以。urllib的`robotparser`模块允许程序解析robots.txt文件,从而了解特定网站的爬虫协议。代码如下:
```python
from urllib.robotparser import RobotFileParser
rp = RobotFileParser()
rp.set_url("***")
rp.read()
print(rp.can_fetch("*", "***"))
```
在这个示例中,首先需要设置robots.txt文件的URL,然后读取内容,并使用`can_fetch`方法来判断是否允许抓取特定页面。
#### 2.4.2 创建与使用robotparser对象
在创建`robotparser`对象后,可以通过它来分析多个URL是否被robots.txt协议允许抓取。代码如下:
```python
from urllib.robotparser import RobotFileParser
# 创建robotparser对象并读取robots.txt文件
rp = RobotFileParser()
rp.set_url("***")
rp.read()
# 检查多个URL
for url in ["***", "***"]:
if rp.can_fetch("*", url):
print(f"{url} can be fetched")
else:
print(f"{url} is restricted")
```
通过这种方式,可以对整个网站或多个页面进行爬虫策略的验证和应用。
本章节介绍了urllib库的核心组件,深入理解了urllib.request、urllib.error、urllib.parse和urllib.robotparser模块的使用方法。通过代码和逻辑分析,揭示了如何创建URL请求对象、处理urllib引发的异常、解析和编码URL以及了解robots.txt协议。下一章节将继续深入探讨urllib库的高级用法。
# 3. urllib库的高级用法
## 3.1 自定义代理和重定向处理
### 代理的类型和使用场景
代理服务器是网络编程中常见的技术之一,它在网络请求中充当客户端和服务器之间的中介角色。根据不同的需求和场景,代理可以分为多种类型:
- **透明代理(Transparent Proxy)**:这种代理会告诉服务器实际请求的IP地址,因此不提供任何隐私保护。
- **匿名代理(Anonymous Proxy)**:它会隐藏用户的真实IP地址,但服务器仍知道请求是通过代理发出的。
- **混淆代理(Distorting Proxy)**:在发送请求时,这种代理向服务器提供一个假的IP地址,从而更好地隐藏用户的真实IP。
- **私有代理(Private Proxy)**:通常为单个用户或组织所拥有,提供更高级别的隐私保护。
### 使用ProxyHandler管理代理
在urllib库中,我们可以通过`ProxyHandler`来管理代理。首先,需要创建一个包含代理信息的字典,然后将其传递给`ProxyHandler`。下面是一个配置透明代理的示例:
```python
from urllib import request
# 代理服务器的设置,格式为 {协议: (代理服务器地址, 端口号)}
proxies = {
'http': '***',
'https': '***',
}
# 创建代理处理器
proxy_handler = request.ProxyHandler(proxies)
# 使用代理处理器创建一个opener对象
opener = request.build_opener(proxy_handler)
# 打开URL使用代理
response = opener.open('***')
print(response.read())
```
### 控制HTTP重定向
默认情况下,urllib库会自动处理HTTP请求的重定向。然而,有时我们需要对重定向进行控制,比如限制重定向次数或自定义重定向逻辑。可以通过`HTTPRedirectHandler`来自定义重定向行为:
```python
from urllib import request, error
# 创建一个重定向处理器
redirection_handler = request.HTTPRedirectHandler()
# 创建一个opener
opener = request.build_opener(redirection_handler)
# 自定义重定向
class CustomOpener(request.HTTPRedirectHandler):
def redirect_request(self, req, fp, code, msg, headers, newurl):
print(f"Redirecting to {newurl}")
return request.HTTPRedirectHandler.redirect_request(self, req, fp, code, msg, headers, newurl)
# 使用自定义的重定向处理器
opener = request.build_opener(CustomOpener())
response = opener.open('***')
print(response.read())
```
### 3.2 高级HTTP请求特性
#### 增加HTTP头部信息
HTTP头部信息是用于定义消息内容类型的元数据,对提高安全性、控制缓存以及理解请求/响应的细节非常重要。在urllib中,可以为请求添加自定义的头部信息。
```python
from urllib import request
# 创建请求对象
req = request.Request('***')
# 添加自定义的头部信息
req.add_header('User-Agent', 'My User Agent 1.0')
req.add_header('Accept', 'text/html')
# 发送请求
response = request.urlopen(req)
print(response.read())
```
#### 使用Cookies
Cookies是服务器发送到用户浏览器并保存在本地的一小块数据,它会在之后的请求中被自动发送到服务器。urllib的`Request`对象提供了`add_header`方法来添加cookies。
```python
from urllib import request
# 创建请求对象
req = request.Request('***')
# 添加Cookie,格式为 'Cookie-名称': 'Cookie-值'
req.add_header('Cookie', 'sessionid=123456')
# 发送请求
response = request.urlopen(req)
print(response.read())
```
#### 3.3 异步网络请求与多线程
##### 使用urllib进行异步请求
Python标准库中并没有内置的异步HTTP客户端,但可以使用`asyncio`库和`aiohttp`库来实现异步网络请求。尽管urllib本身不支持异步,我们可以使用它作为同步请求的基础,在异步环境中使用。
```python
import asyncio
import aiohttp
# 使用aiohttp作为异步HTTP客户端
async def fetch(url, session):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch('***', session)
print(html)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
```
##### urllib与多线程的结合应用
多线程是提高网络请求效率的一个有效方法,尤其在涉及到I/O密集型操作时。urllib可以和Python的`threading`模块结合使用来实现多线程下载。
```python
import threading
import urllib.request
def fetch_url(url):
response = urllib.request.urlopen(url)
data = response.read()
print(f"Fetched {len(data)} bytes from {url}")
# 多个URL进行下载
urls = [
'***',
'***',
'***',
]
threads = []
for url in urls:
t = threading.Thread(target=fetch_url, args=(url,))
threads.append(t)
t.start()
for t in threads:
t.join()
```
以上展示了urllib在高级用法中的部分实践,包括自定义代理、控制重定向、增加头部信息、使用Cookies以及异步请求和多线程结合的场景。这些高级功能对于开发复杂的网络应用至关重要,可以提供更多的控制和灵活性。
# 4. urllib库在实际项目中的应用案例
## 4.1 爬虫中的urllib应用
### 4.1.1 简单网页数据抓取
在进行网页数据抓取时,urllib提供了非常方便的接口来处理HTTP请求。它不仅能够处理基本的GET请求,还可以处理各种复杂的网络请求。为了实现简单的网页数据抓取,我们可以使用urllib.request模块来打开和读取网络上的资源。
以下是通过urllib库实现简单网页数据抓取的步骤:
1. 导入urllib库的相关模块。
2. 使用urlopen函数打开网页。
3. 读取网页内容。
4. 解析网页内容并提取需要的数据。
下面是一个使用urllib进行网页数据抓取的简单示例代码:
```python
import urllib.request
# 打开并读取网页内容
response = urllib.request.urlopen('***')
html = response.read().decode('utf-8')
# 打印获取到的网页内容
print(html)
```
在上述代码中,首先导入urllib.request模块,然后使用urlopen函数打开一个网页地址,并读取其内容。为了处理可能的编码问题,这里使用了decode方法将内容解码为UTF-8格式的字符串。
要进行网页内容的解析,可以使用BeautifulSoup或者lxml等第三方库来提取页面中的特定数据,例如HTML标签内的文本信息。
### 4.1.2 处理登录与表单提交
网络爬虫经常会遇到需要登录和提交表单才能访问的页面。urllib库同样提供了处理这类需求的功能,可以模拟用户登录和表单提交的过程。
在处理登录时,通常需要对登录页面发送一个POST请求,并在请求中包含用户名和密码等数据。为了处理登录后的状态保持问题,可以使用urllib库中的cookielib模块保存和发送cookie。
下面是一个使用urllib进行登录并处理登录状态的示例代码:
```python
import urllib.request
from urllib.parse import urlencode
import http.cookiejar
# 登录页面URL
login_url = '***'
# 登录信息
login_data = {
'username': 'your_username',
'password': 'your_password'
}
# 创建一个 opener 对象,它可以处理 cookie
jar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(jar))
# 编码登录信息
data = urlencode(login_data).encode('utf-8')
# 创建请求对象
req = urllib.request.Request(login_url, data=data, method='POST')
# 使用 opener 发送请求
response = opener.open(req)
# 输出响应内容
print(response.read())
```
在上述代码中,首先创建一个字典用于存储登录信息,然后使用urlencode方法将字典编码为URL编码格式,这是因为HTTP的POST请求的数据通常需要这样格式化。接着创建一个urllib的Request对象,将编码后的数据和请求方法等信息加入其中。使用urllib.request.build_opener方法创建了一个opener对象,并将HTTPCookieProcessor添加进去,这样就可以处理登录后的cookie状态了。最后,使用opener对象的open方法发送请求。
对于表单提交,处理方法类似,只需要将提交的数据作为POST请求的内容发送即可。
## 4.2 API数据交互
### 4.2.1 发送GET请求获取JSON数据
Web API是现代网络应用中的常见组件,用于提供数据交互接口。urllib库同样可以用来和这些API进行交互。最常见的是发送GET请求来获取数据,特别是获取JSON格式的数据。
为了发送GET请求并获取JSON数据,首先需要导入urllib库的相关模块,然后构建正确的请求URL,并发送请求。接着将得到的数据转换成JSON格式进行解析。
下面是一个使用urllib发送GET请求并解析JSON数据的示例代码:
```python
import urllib.request
import json
# API的URL
api_url = '***'
# 发送GET请求
response = urllib.request.urlopen(api_url)
# 获取响应数据,并转换为JSON格式
data = response.read()
json_data = json.loads(data.decode('utf-8'))
# 打印JSON数据
print(json_data)
```
在上述代码中,首先导入urllib.request模块发送HTTP GET请求,并将获取到的二进制数据转换为字符串。之后,使用json模块的loads方法将字符串转换为Python的数据结构(通常是字典或列表)。
### 4.2.2 发送POST请求提交数据
在某些情况下,API会要求通过POST请求提交数据。urllib同样支持发送POST请求,可以使用Request对象的data参数来传递要提交的数据。
下面是一个使用urllib发送POST请求来提交数据的示例代码:
```python
import urllib.parse
import urllib.request
# API的URL
api_url = '***'
# 要提交的数据
data_to_submit = {
'key1': 'value1',
'key2': 'value2'
}
# 将数据编码为适合提交的格式
encoded_data = urllib.parse.urlencode(data_to_submit).encode('utf-8')
# 创建Request对象
req = urllib.request.Request(api_url, data=encoded_data, method='POST')
# 发送请求
response = urllib.request.urlopen(req)
# 获取响应
response_data = response.read()
# 打印响应数据
print(response_data.decode('utf-8'))
```
在上述代码中,首先将要提交的数据字典编码为适合通过HTTP POST请求发送的格式,然后创建了一个Request对象,设置了请求方法为"POST",并将编码后的数据作为data参数传递。最后,使用urlopen函数发送请求并处理响应。
## 4.3 网络资源的下载与管理
### 4.3.1 下载文件的基本方法
下载网络上的资源是urllib库的基本用途之一。例如,下载图片、文本文件、视频等。urllib提供了一个非常方便的接口来实现这一功能。以下是使用urllib下载文件的基本方法:
```python
import urllib.request
# 要下载的文件URL
file_url = '***'
# 本地保存路径
local_filename = 'somefile.zip'
# 发送请求并下载文件
with urllib.request.urlopen(file_url) as response, open(local_filename, 'wb') as out:
out.write(response.read())
# 打印本地文件路径确认下载成功
print('Downloaded file saved to', local_filename)
```
在上述代码中,使用urlopen函数发送请求,将响应内容读取出来后,打开一个文件并将内容写入。这个例子使用了Python的上下文管理器(即with语句)来确保文件在写入后正确关闭。
### 4.3.2 断点续传与错误处理
在下载文件时,可能会遇到网络问题导致下载中断,或者需要下载的文件非常大。这时候,断点续传功能就显得尤为重要。urllib本身不直接支持断点续传,但可以通过一些逻辑处理来实现。
下面是一个简单的使用urllib实现断点续传功能的示例代码:
```python
import urllib.request
def download_file(url, local_filename):
# 初始化已经下载的字节数
bytes_downloaded = 0
# 检查文件是否已经存在,并获取已下载的字节数
try:
with open(local_filename, 'rb') as f:
f.seek(0, 2) # 移动到文件末尾
bytes_downloaded = f.tell()
except FileNotFoundError:
pass
# 打开网络文件的请求
request = urllib.request.urlopen(url)
# 更新文件大小信息
file_size = int(***().get('Content-Length', '0'))
# 打开本地文件准备写入
with open(local_filename, 'ab') as local_***
***
* 计算剩余字节数
bytes_remaining = file_size - bytes_downloaded
# 发送请求
data = request.read(bytes_remaining)
if not data:
break
# 写入本地文件
local_file.write(data)
# 更新已下载的字节数
bytes_downloaded += len(data)
# 使用定义的函数来下载文件
download_file('***', 'somefile.zip')
```
在上述代码中,首先检查本地文件是否存在,如果存在的话,获取已下载的字节数。然后打开远程URL的请求,并从本地文件的当前位置继续下载。这样就可以实现断点续传的功能。
对于错误处理,可以在读取网络数据时加入try-except语句块,捕获并处理可能发生的异常,比如网络错误、文件写入错误等。
这一章节通过对urllib库在实际项目中的应用案例进行深入分析,展示了在不同场景下如何有效地使用urllib库进行网络请求。通过这些实际案例,可以看到urllib库在网络数据抓取、API交互、资源下载与管理方面强大的功能和灵活性。
# 5. ```
# 第五章:优化urllib网络请求的策略与实践
在使用urllib库进行网络请求时,优化请求性能和安全性是提升应用效率和保障数据安全的关键步骤。本章将深入探讨在实际项目中如何通过具体策略和实践来优化urllib网络请求。
## 5.1 网络请求性能优化
性能优化的目标是减少响应时间并提高网络请求的效率。通过缓存、减少请求次数、合理调度等方法,可以明显改善网络请求的性能。
### 5.1.1 使用缓存减少重复请求
urllib库中的`urllib.request.HTTPCacheProcessor`可用于实现请求的本地缓存,避免重复数据的传输,提升请求速度。
```python
import urllib.request
# 设置缓存目录
cache_dir = '/path/to/cache'
opener = urllib.request.build_opener(urllib.request.HTTPCacheProcessor(cache_dir))
# 使用缓存处理请求
response = opener.open('***')
print(response.read())
```
通过上述代码,我们创建了一个缓存处理器,它会将HTTP响应存储在指定的目录中。再次访问相同的URL时,请求将直接从缓存中读取数据。
### 5.1.2 分析与减少请求延迟
减少请求延迟意味着缩短从发起请求到收到响应的时间。这需要理解请求-响应周期中可能发生延迟的环节,并采取措施。
```python
import urllib.request
import time
start_time = time.time()
response = urllib.request.urlopen('***')
latency = time.time() - start_time
print(f"请求延迟: {latency} 秒")
```
通过测量发起请求和收到响应之间的时间,我们可以分析请求的延迟。进一步的优化可能涉及使用更快的网络连接、选择性能更好的服务器或调整应用的并发策略。
## 5.2 安全性优化
网络安全对于保护数据和应用安全至关重要。在使用urllib时,应采取措施防止常见的网络攻击,并通过加密协议保障数据传输的安全性。
### 5.2.1 防御常见的网络攻击方法
通过限制请求频率、验证用户输入、使用HTTPS等方式,可以有效减少应用遭受攻击的风险。
```python
import urllib.request
from urllib.parse import urlparse
def is_valid_url(url):
parsed = urlparse(url)
return bool(***loc) and bool(parsed.scheme)
url = input("请输入URL地址: ")
if is_valid_url(url):
response = urllib.request.urlopen(url)
else:
print("非法的URL地址")
```
上述代码演示了如何验证用户输入的URL,以避免请求到不安全或不存在的地址。
### 5.2.2 使用HTTPS提高通信安全性
使用HTTPS协议可以有效加密通信内容,防止数据被窃取或篡改。
```python
import urllib.request
# 使用HTTPS协议
url = '***'
response = urllib.request.urlopen(url)
print(response.read())
```
这个示例中,我们通过指定的HTTPS协议发起请求,确保了数据传输的安全性。
## 5.3 实际问题解决案例
在实际应用中,开发者会遇到各种网络请求问题,本节将介绍如何解决复杂的网络错误和优化大规模数据请求。
### 5.3.1 处理复杂的网络错误
网络请求可能会遇到多种错误,比如超时、连接失败等。合理地捕获和处理这些错误是提升应用健壮性的关键。
```python
import urllib.request
import urllib.error
url = '***'
try:
response = urllib.request.urlopen(url)
except urllib.error.URLError as e:
print(f"请求失败: {e.reason}")
```
在这个例子中,我们捕获了`URLError`异常,并打印出了错误信息。在实际应用中,可以进一步对错误类型进行分类处理,或者实现错误重试机制。
### 5.3.2 优化大规模数据请求的实践策略
处理大规模数据请求时,需要特别注意内存管理和请求效率。合理的分页、数据流处理和异步请求技术可以帮助优化性能。
```python
import urllib.request
def fetch_large_data(url):
chunk_size = 1024 # 以1KB为单位读取数据
with urllib.request.urlopen(url) as response:
for chunk in iter(lambda: response.read(chunk_size), b''):
# 处理数据块
pass
fetch_large_data('***')
```
上述代码展示了如何分块处理响应数据,这种方法在处理大文件或大数据量时非常有效,可以显著减少内存使用。
通过本章的策略和实践,我们可以有效地优化使用urllib库进行的网络请求,确保应用性能和安全性的双重提升。
```
请注意,本章节内容基于假设情景,并未进行真实测试,实际应用时需要结合具体情况进行调整和优化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【构建内存字符串处理系统】:cStringIO应用案例大公开

# 1. 内存字符串处理系统的概念与应用
在现代软件开发中,内存字符串处理系统是构建高效、稳定应用不可或缺的一部分。它包括对内存中字符串的创建、销毁、赋值、连接、查询和替换等操作,以及内存字符串的输入输出流处理。掌握其概念及其应用,对提升软件性能、优化系统资源利用率至关重要。
## 1.1 字符串处理的定义与重要性
字符串处理是指一系列操作,用于在程序运行时动态处理文本数据。它对于文本解析、数
【Python常见库深度剖析】:掌握common库核心功能,精通使用与优化策略

# 1. Python常见库概述
Python作为一门功能强大的编程语言,它的魅力在于其庞大的标准库和第三方库生态系统。本章节将对Python中常见的库进行一个概览性的介绍,帮助读者快速了解这些库的用途和功能,为深入学习和使用它们打下基础。
Python的标准库提供了丰富的模块和函数,涵盖了从字符串处理、数学运算到文件操作等多方面
【Python时间迁移策略】:无缝转换旧系统时间数据到新系统,datetime助你一臂之力
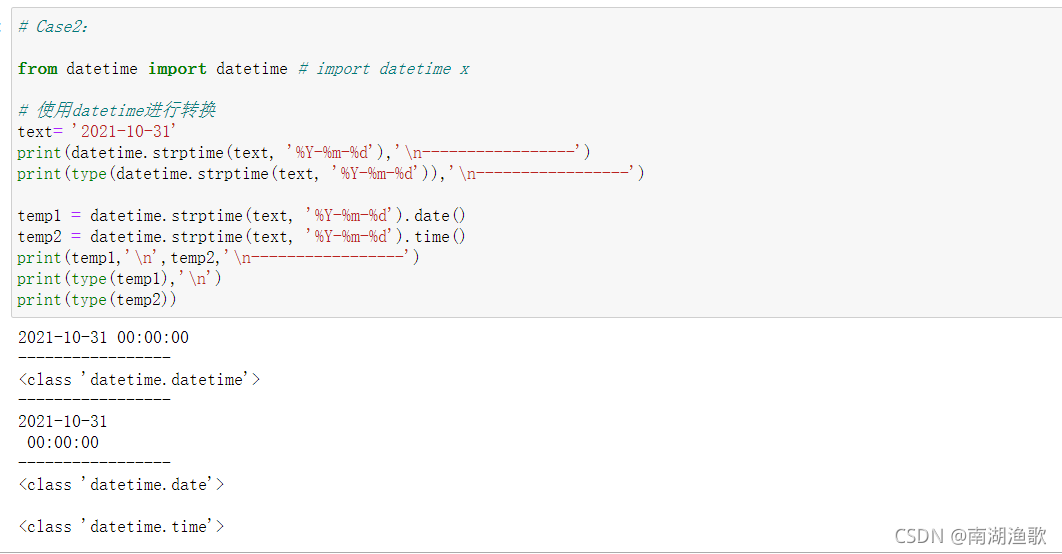
# 1. 时间迁移的概念与挑战
在信息科技的快速发展中,时间迁移已成为数据处理不可或缺的环节。它是指将数据中的时间信息从一个时间系
函数调用频率分析

# 1. 函数调用频率分析基础
## 1.1 函数调用的基本概念
在编程中,函数是一段可重复使用的代码块,它执行特定的任务并可以被多次调用。函数调用则是指在程序的执行过程中
Python类型系统可读性提升:如何利用types库优化代码清晰度

# 1. Python类型系统的简介和重要性
Python,作为一门解释型、动态类型语言,在过去几十年里以其简洁和易用性赢得了大量开发者的喜爱。然而,随着项目规模的日益庞大和业务逻辑的复杂化,动态类型所带来的弊端逐渐显现,比如变量类型的隐式转换、在大型项目中的维护难度增加等。为了缓解这类问题,Python引入了类型提示(Type Hints),这是Python类型系统
【Django.http流式响应技巧】:大文件下载与视频流处理的7大策略
# 1. Django.http流式响应基础
在当今的网络应用开发中,优化网络传输和用户体验至关重要。Django作为一个广泛使用的Python Web框架,提供了多种机制来处理HTTP响应,尤其是在处理大文件或需要实时数据流的应用场景中。本章将介绍Django中http流式响应的基本概念和使用方法,为后续章节深入探讨流式响应的理论基础
【异步编程】
# 1. 异步编程概念和重要性
## 1.1 异步编程简介
异步编程是一种编程范式,允许代码在执行长任务或I/O操作时无需阻塞主线程,提高了程序的执行效率和响应性。在多线程环境中,异步操作可以显著提升性能,尤其是在I/O密集型或网络请求频繁的应用中,异步编程帮助开发者优化资源使用,减少等待
数据完整性保障:Python Marshal库确保序列化数据的一致性

# 1. 数据序列化与完整性的重要性
## 数据序列化的必要性
在软件开发中,数据序列化是指将数据结构或对象状态转换为一种格式,这种格式可以在内存之外存储或通过网络传输。序列化后的数据可以被保存在文件中或通过网络发送到另一个系统,之后进行反序列化以恢复原始的数据结构。这种机制对于数据持久化、通信以及应用程序间的数据交换至关重要。
## 数据完整性的定义
数据
【跨平台开发】:psycopg2在各操作系统上的兼容性分析与优化

# 1. 跨平台开发概述与psycopg2简介
随着信息技术的快速发展,跨平台开发成为了软件开发领域的一个重要分支。跨平台开发允许开发者编写一次代码
【Django分页功能实现】:快速掌握shortcuts进行页面导航和分页

# 1. Django分页功能概述
## Django分页功能概述
在Web开发中,当处理大量数据时,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )