Navicat Connection to MySQL Database: Best Practices Guide for Enhancing Database Connection Efficiency
发布时间: 2024-09-14 18:34:59 阅读量: 30 订阅数: 27 
# 1. Best Practices for Connecting to MySQL Database with Navicat
Navicat is a powerful database management tool that enables you to connect to and manage MySQL databases. To ensure the best connection experience, it's crucial to follow some best practices.
First, optimize connection parameters, including connection timeout settings and connection pool configurations. By adjusting these parameters, you can enhance connection efficiency and reduce latency. Moreover, selecting the appropriate server location and using CDN or proxies can further minimize network latency, thereby increasing connection speed.
# 2. Tips for Improving Database Connection Efficiency
Database connection efficiency is vital for the performance of your application. Slow connection speeds can lead to longer response times, poor user experience, and even affect business operations. This chapter will explore tips for improving database connection efficiency to help you optimize your application's performance.
### 2.1 Optimizing Connection Parameters
#### 2.1.1 Connection Timeout Settings
Connection timeout settings specify how long the database waits before attempting a connection. Excessively long connection timeouts waste time, while too short timeouts may cause applications to fail due to timeout errors.
**Parameter Explanation:**
- `connect_timeout`: Connection timeout duration, measured in seconds.
**Code Example:**
```python
import mysql.connector
# Set the connection timeout to 5 seconds
connection = mysql.connector.connect(
host="localhost",
user="root",
password="password",
connect_timeout=5
)
```
**Logical Analysis:**
This code sets the connection timeout to 5 seconds. If the database cannot establish a connection within 5 seconds, a `mysql.connector.errors.OperationalError` exception will be raised.
#### 2.1.2 Connection Pool Configuration
A connection pool is a pre-established collection of database connections that applications can draw from and release. Using a connection pool can reduce the overhead of establishing and closing connections, thus improving connection efficiency.
**Parameter Explanation:**
- `pool_size`: The size of the connection pool, indicating the maximum number of connections that can exist simultaneously in the pool.
- `max_overflow`: The maximum number of extra connections allowed when exceeding the connection pool size.
**Code Example:**
```python
import mysql.connector
# Create a connection pool with a maximum of 10 connections
connection_pool = mysql.connector.pooling.MySQLConnectionPool(
pool_size=10,
max_overflow=2
)
# Get a connection from the connection pool
connection = connection_pool.get_connection()
```
**Logical Analysis:**
This code creates a connection pool with a maximum of 10 connections, allowing for up to 2 additional connections beyond the pool

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
火灾图像识别的硬件选择:为性能定制计算平台的策略

# 1. 火灾图像识别的基本概念与技术背景
## 1.1 火灾图像识别定义
火灾图像识别是利用计算机视觉技术对火灾现场图像进行自动检测、分析并作出响应的过程。它的核心是通过图像处理和模式识别技术,实现对火灾场景的实时监测和快速反应,从而提升火灾预警和处理的效率。
## 1.2 技术背景
随着深度学习技术的迅猛发展,图像识别领域也取得了巨大进步。卷积神经网络(CNN)等深度学习模型在图像识别中表现出色,为火灾图像的准
自助点餐系统的云服务迁移:平滑过渡到云计算平台的解决方案

# 1. 自助点餐系统与云服务迁移概述
## 1.1 云服务在餐饮业的应用背景
随着技术的发展,自助点餐系统已成为餐饮行业的重要组成部分。这一系统通过提供用户友好的界面和高效的订单处理,优化顾客体验,并减少服务员的工作量。然而,随着业务的增长,许多自助点餐系统面临着需要提高可扩展性、减少维护成本和提升数据安全性等挑战。
## 1.2 为什么要迁移至云服务
传统的自助点餐系统
STM32 IIC通信DMA传输高效指南:减轻CPU负担与提高数据处理速度
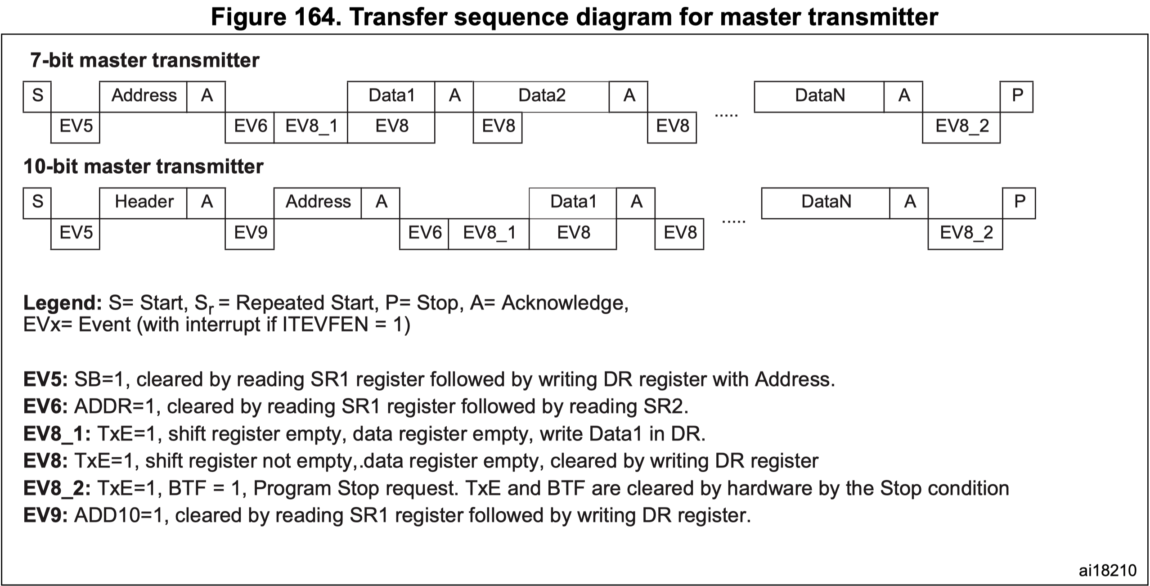
# 1. STM32 IIC通信基础与DMA原理
## 1.1 IIC通信简介
IIC(Inter-Integrated Circuit),即内部集成电路总线,是一种广泛应用于微控制器和各种外围设备间的串行通信协议。STM32微控制器作为行业内的主流选择之一,它支持IIC通信协议,为实现主从设备间
【并发链表重排】:应对多线程挑战的同步机制应用
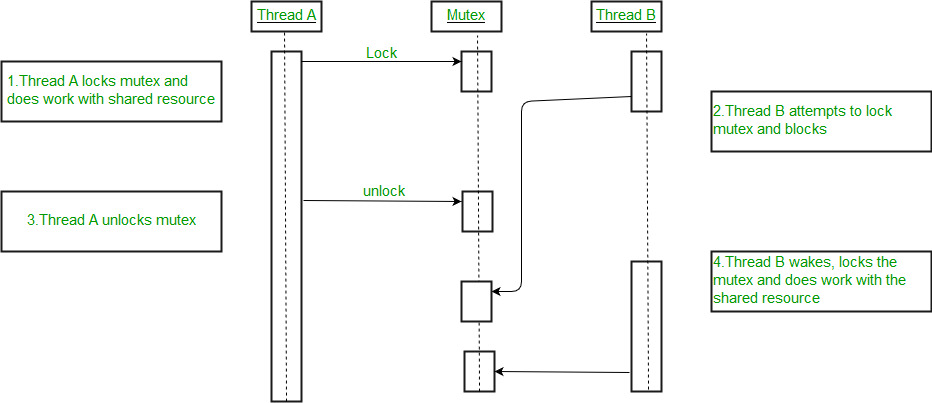
# 1. 并发链表重排的理论基础
## 1.1 并发编程概述
并发编程是计算机科学中的一个复杂领域,它涉及到同时执行多个计算任务以提高效率和响应速度。并发程序允许多个操作同时进行,但它也引入了多种挑战,比如资源共享、竞态条件、死锁和线程同步问题。理解并发编程的基本概念对于设计高效、可靠的系统至关重要。
## 1.2 并发与并行的区别
在深入探讨并发链表重排之前,我们需要明确并发(Con
【Chirp信号抗干扰能力深入分析】:4大策略在复杂信道中保持信号稳定性
# 1. Chirp信号的基本概念
## 1.1 什么是Chirp信号
Chirp信号是一种频率随时间变化的信号,其特点是载波频率从一个频率值线性增加(或减少)到另一个频率值。在信号处理中,Chirp信号的这种特性被广泛应用于雷达、声纳、通信等领域。
## 1.2 Chirp信号的特点
Chirp信号的主要特点是其频率的变化速率是恒定的。这意味着其瞬时频率与时间
社交网络轻松集成:P2P聊天中的好友关系与社交功能实操
# 1. P2P聊天与社交网络的基本概念
## 1.1 P2P聊天简介
P2P(Peer-to-Peer)聊天是指在没有中心服务器的情况下,聊天者之间直接交换信息的通信方式。P2P聊天因其分布式的特性,在社交网络中提供了高度的隐私保护和低延迟通信。这种聊天方式的主要特点是用户既是客户端也是服务器,任何用户都可以直接与其
【实时性能的提升之道】:LMS算法的并行化处理技术揭秘

# 1. LMS算法与实时性能概述
在现代信号处理领域中,最小均方(Least Mean Squares,简称LMS)算法是自适应滤波技术中应用最为广泛的一种。LMS算法不仅能够自动调整其参数以适
【操作系统安全监控策略】:实时监控,预防安全事件的终极指南
# 1. 操作系统安全监控的理论基础
在当今数字化时代,操作系统作为计算机硬件和软件资源管理的核心,其安全性对于整个信息系统的安全至关重要。操作系统安全监控是保障系统安全的一项关键措施,它涉及一系列理论知识与实践技术。本章旨在为读者提供操作系统安全监控的理论基础,包括安全监控的基本概念、主要目标以及监控体系结构的基本组成。
首先,我们将探讨安全监控
【项目管理】:如何在项目中成功应用FBP模型进行代码重构
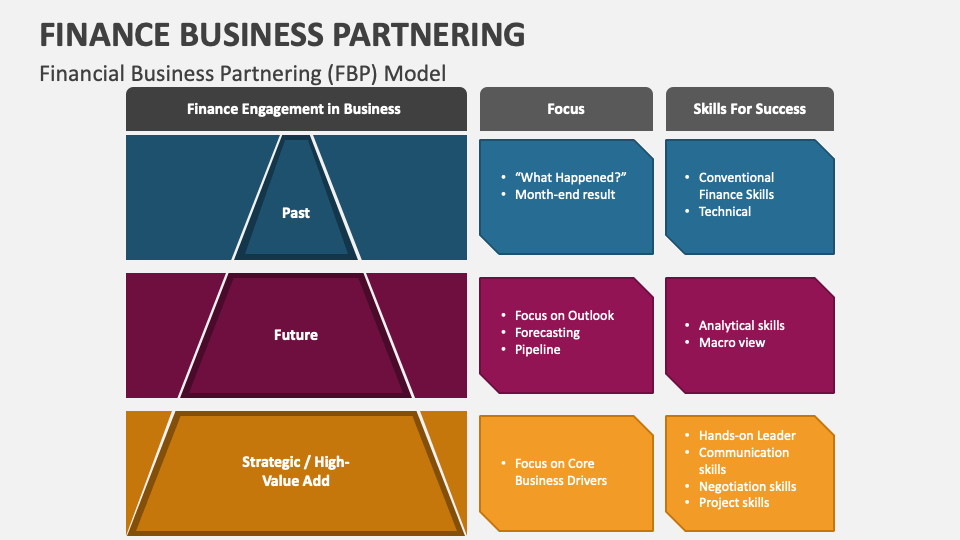
# 1. FBP模型在项目管理中的重要性
在当今IT行业中,项目管理的效率和质量直接关系到企业的成功与否。而FBP模型(Flow-Based Programming Model)作为一种先进的项目管理方法,为处理复杂
【低功耗设计达人】:静态MOS门电路低功耗设计技巧,打造环保高效电路
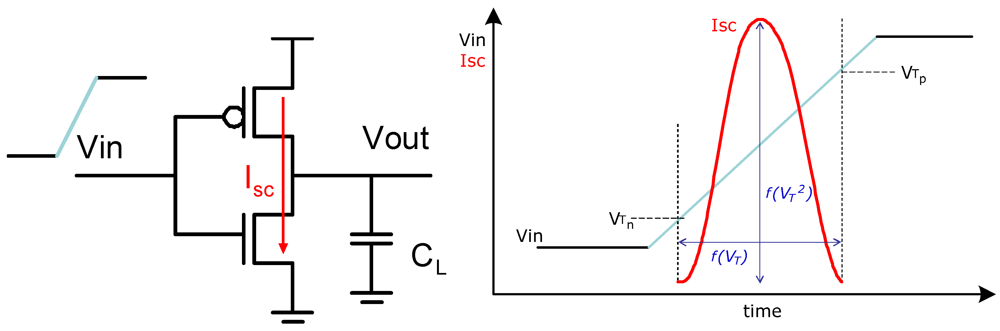
# 1. 静态MOS门电路的基本原理
静态MOS门电路是数字电路设计中的基础,理解其基本原理对于设计高性能、低功耗的集成电路至关重要。本章旨在介绍静态MOS门电路的工作方式,以及它们如何通过N沟道MOSFET(NMOS)和P沟道MOSFET(PMOS)的组合来实现逻辑功能。
## 1.1 MOSFET的基本概念
MOSFET,全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )