线性搜索算法在人工智能中的应用:机器学习与数据挖掘的利器
发布时间: 2024-08-25 12:37:25 阅读量: 8 订阅数: 18 
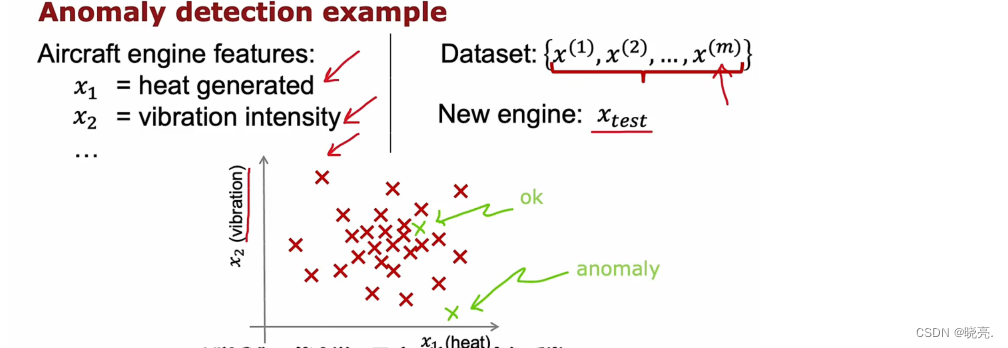
# 1. 线性搜索算法概述
线性搜索算法是一种简单且易于实现的搜索算法,它通过逐个比较元素来查找目标元素。它在无序数据中表现良好,并且在数据量较小时效率较高。
线性搜索算法的时间复杂度为 O(n),其中 n 是数据集合的大小。这意味着随着数据集合的增大,搜索时间也会线性增长。因此,对于大规模数据集,线性搜索算法的效率较低。
# 2. 线性搜索算法在机器学习中的应用
### 2.1 线性搜索算法在分类中的应用
#### 2.1.1 K近邻算法
K近邻算法(KNN)是一种非参数分类算法,它通过计算数据点到其他所有数据点的距离,并选择距离最近的K个数据点(称为K个近邻)来预测新数据点的类别。
在KNN中,线性搜索算法用于查找新数据点到训练集中所有其他数据点的距离。以下是KNN算法的伪代码:
```python
def knn(new_data_point, training_data, k):
# 计算新数据点到训练集中所有其他数据点的距离
distances = []
for training_data_point in training_data:
distance = calculate_distance(new_data_point, training_data_point)
distances.append((training_data_point, distance))
# 对距离进行排序
distances.sort(key=lambda x: x[1])
# 选择距离最近的K个数据点
k_nearest_neighbors = distances[:k]
# 预测新数据点的类别
predicted_class = get_majority_class(k_nearest_neighbors)
return predicted_class
```
#### 2.1.2 支持向量机
支持向量机(SVM)是一种二元分类算法,它通过在数据点之间找到一个超平面来将数据点分隔成不同的类别。
在SVM中,线性搜索算法用于查找支持向量,即位于超平面两侧最近的数据点。以下是SVM算法的伪代码:
```python
def svm(training_data, C):
# 找到支持向量
support_vectors = []
for training_data_point in training_data:
if is_support_vector(training_data_point, training_data, C):
support_vectors.append(training_data_point)
# 训练SVM模型
model = train_svm(support_vectors)
return model
```
### 2.2 线性搜索算法在聚类中的应用
#### 2.2.1 K均值算法
K均值算法是一种聚类算法,它通过将数据点分配到K个簇中来对数据进行分组。
在K均值算法中,线性搜索算法用于查找每个数据点到所有簇中心的距离,并将其分配到距离最近的簇中心。以下是K均值算法的伪代码:
```python
def kmeans(data, k):
# 初始化簇中心
centroids = initialize_centroids(data, k)
# 迭代直到簇中心不再变化
while True:
# 将每个数据点分配到距离最近的簇中心
for data_point in data:
closest_centroid = get_closest_centroid(data_point, centroids)
data_point.cluster = closest_centroid
# 更新簇中心
for centroid in centroids:
centroid = get_centroid(centroid.cluster)
# 检查簇中心是否已收敛
if centroids_have_converged(centroids):
break
```
#### 2.2.2 层次聚类算法
层次聚类算法是一种聚类算法,它通过创建数据点的层次结构来对数据进行分组。
在层次聚类算法中,线性搜索算法用于查找数据点之间的距离,并根据这些距离构建层次结构。以下是层次聚类算法的伪代码:
```python
def hierarchical_clustering(data):
# 初始化层次结构
dendrogram = []
# 计算数据点之间的距离
distances = calculate_distances(data)
# 迭代直到只有一个簇
while len(data) > 1:
# 找到距离最近的两个簇
closest_clusters = get_closest_clusters(distances)
# 合并两个簇
new_cluster = merge_clusters(closest_clus
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《线性搜索的实现与应用实战》专栏深入探讨了线性搜索算法的原理、应用和优化技巧。从基础概念到实战指南,专栏全面介绍了线性搜索在数据结构、数据查找和各种领域的应用。
专栏涵盖了线性搜索算法的复杂度分析、实战案例、变种探索、局限性理解、扩展应用、性能优化、并行化和分布式实现。它还探讨了线性搜索在人工智能、图像处理、生物信息学和金融科技等领域的应用。
通过深入浅出的讲解和丰富的案例,专栏旨在帮助读者掌握线性搜索算法,提升搜索效率,并解锁其在各种实际场景中的应用潜力。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Navicat Connection to MySQL Database: Best Practices Guide for Enhancing Database Connection Efficiency
# 1. Best Practices for Connecting to MySQL Database with Navicat
Navicat is a powerful database management tool that enables you to connect to and manage MySQL databases. To ensure the best connection experience, it's crucial to follow some best practices.
First, optimize connection parameters, i
JavaScript敏感数据安全删除指南:保护用户隐私的实践策略

# 1. JavaScript中的数据安全基础
在当今数字化世界,数据安全已成为保护企业资产和用户隐私的关键。JavaScript作为前端开发的主要语言,其数据安全处理的策略和实践尤为重要。本章将探讨数据安全的基本概念,包括数据保护的重要性、潜在威胁以及如何在JavaScript中采取基础的安全措施。
## 1.1 数据安全的概念
数据安全涉及保护数据免受非授权访问、泄露、篡改或破坏,以及确保数据的完整性和
C Language Image Pixel Data Loading and Analysis [File Format Support] Supports multiple file formats including JPEG, BMP, etc.
# 1. Introduction
The Importance of Image Processing in Computer Vision and Image Analysis
This article focuses on how to read and analyze image pixel data using C language.
# ***
***mon formats include JPEG, BMP, etc. Each has unique features and storage structures. A brief overview is provided
Custom Menus and Macro Scripting in SecureCRT
# 1. Introduction to SecureCRT
SecureCRT is a powerful terminal emulation software developed by VanDyke Software that is primarily used for remote access, control, and management of network devices. It is widely utilized by network engineers and system administrators, offering a wealth of features
Zotero Data Recovery Guide: Rescuing Lost Literature Data, Avoiding the Hassle of Lost References
# Zotero Data Recovery Guide: Rescuing Lost Literature Data, Avoiding the Hassle of Lost References
## 1. Causes and Preventive Measures for Zotero Data Loss
Zotero is a popular literature management tool, yet data loss can still occur. Causes of data loss in Zotero include:
- **Hardware Failure:
【Practical Sensitivity Analysis】: The Practice and Significance of Sensitivity Analysis in Linear Regression Models
# Practical Sensitivity Analysis: Sensitivity Analysis in Linear Regression Models and Its Significance
## 1. Overview of Linear Regression Models
A linear regression model is a common regression analysis method that establishes a linear relationship between independent variables and dependent var
Applications of MATLAB Optimization Algorithms in Machine Learning: Case Studies and Practical Guide
# 1. Introduction to Machine Learning and Optimization Algorithms
Machine learning is a branch of artificial intelligence that endows machines with the ability to learn from data, thus enabling them to predict, make decisions, and recognize patterns. Optimization algorithms play a crucial role in m
Avoid Common Pitfalls in MATLAB Gaussian Fitting: Avoiding Mistakes and Ensuring Fitting Accuracy
# 1. The Theoretical Basis of Gaussian Fitting
Gaussian fitting is a statistical modeling technique used to fit data that follows a normal distribution. It has widespread applications in science, engineering, and business.
**Gaussian Distribution**
The Gaussian distribution, also known as the nor
EasyExcel Dynamic Columns [Performance Optimization] - Saving Memory and Preventing Memory Overflow Issues
# 1. Understanding the Background of EasyExcel Dynamic Columns
- 1.1 Introduction to EasyExcel
- 1.2 Concept and Application Scenarios of Dynamic Columns
- 1.3 Performance and Memory Challenges Brought by Dynamic Columns
# 2. Fundamental Principles of Performance Optimization
When dealing with la
PyCharm Python Code Review: Enhancing Code Quality and Building a Robust Codebase
# 1. Overview of PyCharm Python Code Review
PyCharm is a powerful Python IDE that offers comprehensive code review tools and features to assist developers in enhancing code quality and facilitating team collaboration. Code review is a critical step in the software development process that involves
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )