K均值聚类算法在数据挖掘中的秘密武器:挖掘数据价值,洞察商业奥秘
发布时间: 2024-08-20 19:09:56 阅读量: 15 订阅数: 40 

基于springboot的在线答疑系统文件源码(java毕业设计完整源码+LW).zip
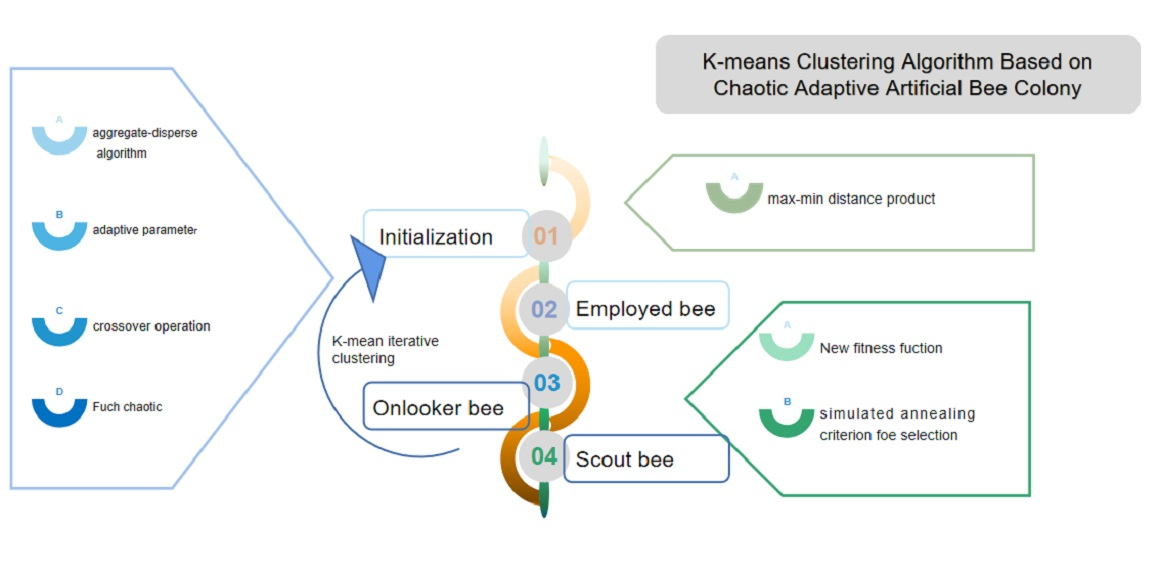
# 1. K均值聚类算法简介**
K均值聚类算法是一种无监督机器学习算法,用于将数据点分组为相似组(称为簇)。其目标是找到一组簇中心,使每个数据点到其最近簇中心的距离之和最小。K均值算法因其简单性和效率而闻名,广泛应用于数据挖掘、客户细分和图像处理等领域。
该算法的优点包括:易于理解和实现、计算效率高、对异常值不敏感。然而,它也有一些局限性,例如:需要预先指定簇的数量(K)、可能收敛于局部最优解、对数据分布敏感。
# 2. K均值聚类算法理论基础**
**2.1 K均值聚类算法的原理**
K均值聚类算法是一种无监督学习算法,用于将数据点划分为K个不同的簇。其基本原理如下:
1. **初始化:**随机选择K个数据点作为初始簇中心。
2. **分配:**将每个数据点分配到距离其最近的簇中心。
3. **更新:**重新计算每个簇的中心,使其等于簇中所有数据点的平均值。
4. **重复:**重复步骤2和3,直到簇中心不再发生变化或达到预定义的迭代次数。
**代码块:**
```python
import numpy as np
def kmeans(X, k):
"""
K均值聚类算法
参数:
X:数据点矩阵,形状为(n_samples, n_features)
k:簇的数量
返回:
簇标签,形状为(n_samples,)
"""
# 初始化簇中心
centroids = X[np.random.choice(X.shape[0], k, replace=False)]
# 分配数据点到簇
labels = np.zeros(X.shape[0], dtype=int)
for i in range(X.shape[0]):
distances = np.linalg.norm(X[i] - centroids, axis=1)
labels[i] = np.argmin(distances)
# 更新簇中心
for i in range(k):
centroids[i] = np.mean(X[labels == i], axis=0)
# 重复分配和更新,直到簇中心不再变化
while True:
prev_labels = labels
labels = np.zeros(X.shape[0], dtype=int)
for i in range(X.shape[0]):
distances = np.linalg.norm(X[i] - centroids, axis=1)
labels[i] = np.argmin(distances)
if np.array_equal(labels, prev_labels):
break
for i in range(k):
centroids[i] = np.mean(X[labels == i], axis=0)
return labels
```
**逻辑分析:**
* 初始化K个簇中心,并将其存储在`centroids`中。
* 对于每

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面解析 K 均值聚类算法,涵盖其原理、实战应用、数学奥秘、优缺点、实现与优化、数据挖掘、图像处理、自然语言处理、推荐系统、金融、医疗、零售、制造、交通、能源等领域的应用,以及最佳实践、常见问题、性能优化、扩展与变体等内容。通过深入浅出的讲解和丰富的案例,本专栏旨在帮助读者掌握 K 均值聚类算法,轻松应对数据聚类挑战,挖掘数据价值,做出明智决策,打造高效聚类模型。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Altium Designer 18 项目管理艺术】:高效组织电子设计的秘籍
# 摘要
本文全面介绍了Altium Designer 18在项目管理方面的应用,涵盖了项目架构创建、组件库管理、PCB设计管理以及高级项目管理技巧等多个方面。文章详细阐述了自动化设计流程配置、多用户协作模式、数据管理策略以及风险评估和质量保证实践。同时,还探讨了如何将敏捷项目管理方法与Altium Designer集成,并预测了未
【空间格局指数透析】:Fragstats4.2专题深度剖析
# 摘要
本文综述了空间格局指数的基础理论,并详细介绍了Fragstats4.2软件的界面、功能、空间数据处理方法以及空间格局指数的计算原理。文中通过操作指南展示了如何使用Fragstats4.2进行空间格局分析,并讨论了指数结果的解读和应用。同时,本文探讨了空间格局指数在生态学评估、景观动态监测、城市规划和土地利用分析中的实际应用。最后,展望了Fragst
【Innovus时序优化宝典】:全面掌握IEEE 1801时序约束

# 摘要
本文系统地介绍了Innovus时序优化的基础知识与实践方法,并深入解读了IEEE 1801时序约束的理论与应用。通过探讨时序约束的概念、分类、定义规则以及高级话题,如多周期路径处理和优化策略,本文旨在为设计工程师提供全面的时序约束管理解决方案。同时,文章详细描述了Innovus时序分析工具的功能、使用方法和进阶技巧,包括时序边界条件
ElementUI el-tree实战演练:如何自定义节点内容

# 摘要
ElementUI的el-tree组件作为前端开发中用于展示树形数据结构的重要元素,广泛应用于信息管理及用户界面设计。本文首先概述了el-tree组件的基本概念和构成,随后深入探讨了其基础属性和数据处理机制,为读者提供了组件的理论基础。接下来,文章详细介绍了节点自定义的原理和关键技术,包括插槽和模板的应用,使开发者能够根据需求设计个性化的节点展示。通过实践操作部分,本文展示了如何实现
SENT协议终极指南:掌握SAE J2716标准与应用
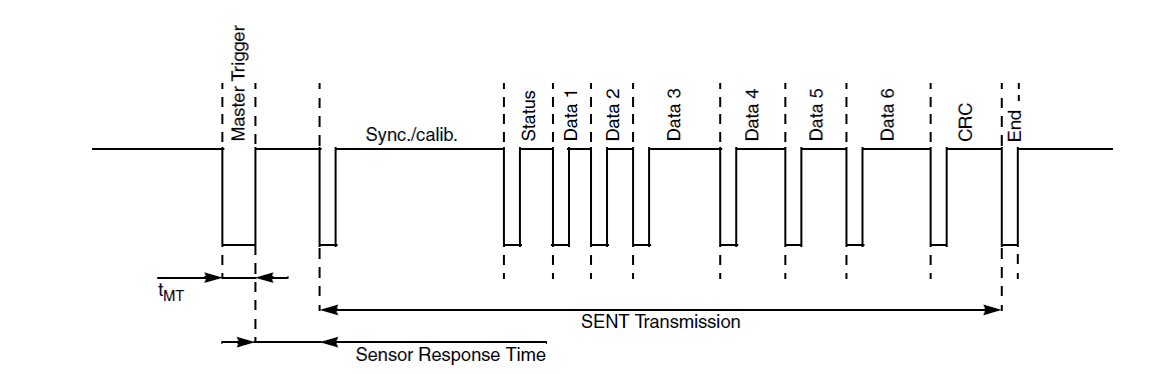
# 摘要
SENT协议是一种在车辆传感器数据传输中广泛使用的通信协议,其概述和SAE J2716标准的详解构成了本文的第一部分。第二部分详细探讨了SENT协议的技术框架、应用场景及其在硬件和软件层面的实践应用。本文还分析了SENT协议的安全性、性能优化以及高级主题,为确保数据传输的安全性和效率提供了解决方案。通过研究SENT协议在豪华轿车和新能源车辆中的实战案例,本文揭示
【TDC-GP21手册深度解读】:中文版权威指南,应用实例全揭秘

# 摘要
TDC-GP21作为一款先进的时域相关技术设备,具有在多个领域内提供精确时间测量和数据处理的独特优势。本文首先概述了TDC-GP21的理论基础,包括其工作原理和核心技术参数,如时间分辨率与精度,以及功能特点和应用场景。接着,文章详细介绍了TDC-GP21的实战部署,包括硬件连接、软件编程和集成,以及实战部署案例分析。性能调优部分则探讨了测试方法论、优化策略和实际调
ADS数据分析案例研究:如何解决实际问题

# 摘要
随着信息技术的快速发展,ADS(高级数据分析)已成为企业和学术界关注的焦点。本文首先概述了ADS数据分析的基础知识,然后深入探讨了数据预处理和探索性分析的重要性,以及如何通过高级数据分析技术,如统计分析和机器学习,来揭示数据背后的深层次模式和关系。第三章重点介绍了大数据技术在ADS中的应用,并探讨了其对处理大规模数据集的贡献。第四章通过具体的行业案例研究和复杂问题的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )