揭秘K均值聚类算法的数学奥秘:掌握原理,轻松应用
发布时间: 2024-08-20 19:01:27 阅读量: 8 订阅数: 11 
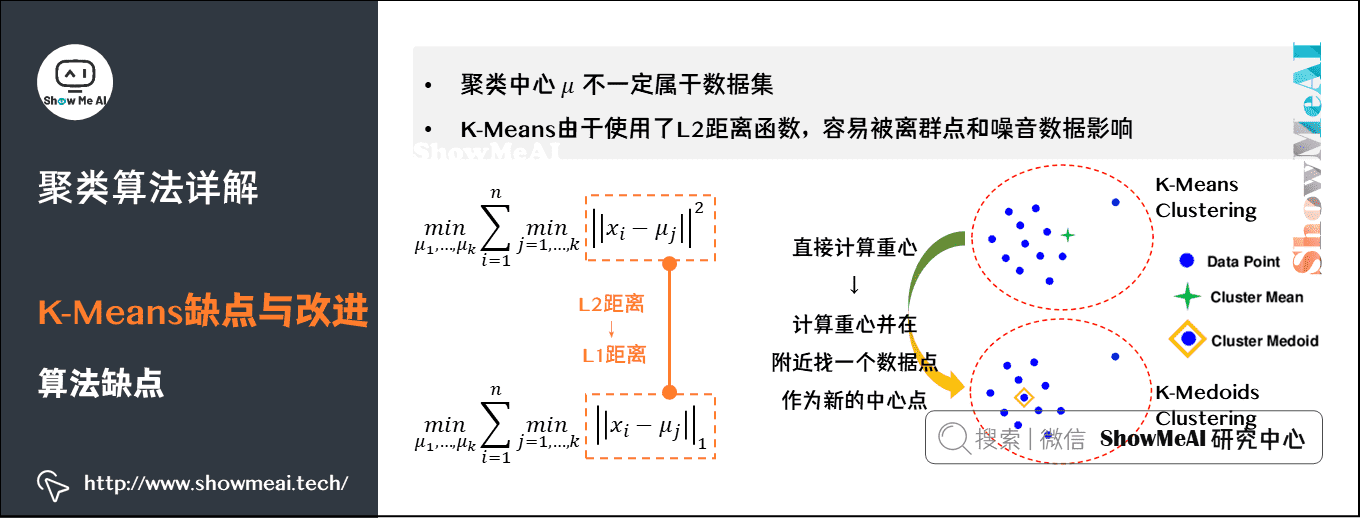
# 1. K均值聚类算法概述
K均值聚类算法是一种无监督机器学习算法,用于将数据点分组为不同的簇。它通过迭代地分配数据点到簇并更新簇的中心来工作,直到簇不再改变。
K均值聚类算法的优点包括:
- 简单且易于实现
- 适用于大数据集
- 可用于各种数据类型
# 2. K均值聚类算法的数学基础
### 2.1 K均值聚类算法的数学模型
#### 2.1.1 距离度量
在K均值聚类算法中,距离度量用于衡量数据点之间的相似性或差异性。常用的距离度量包括:
- **欧几里得距离:**计算两个数据点之间的直线距离。
- **曼哈顿距离:**计算两个数据点之间沿坐标轴的距离总和。
- **闵可夫斯基距离:**欧几里得距离和曼哈顿距离的推广,其中p为参数。
#### 2.1.2 目标函数
K均值聚类算法的目标是找到一组聚类中心,使得数据点到其最近聚类中心的距离之和最小。这个目标函数可以表示为:
```
J(C) = ∑_{i=1}^n ∑_{c∈C} ||x_i - c||^2
```
其中:
- J(C) 为目标函数
- C 为聚类中心集合
- n 为数据点数量
- x_i 为第i个数据点
- c 为聚类中心
### 2.2 K均值聚类算法的优化方法
#### 2.2.1 梯度下降法
梯度下降法是一种迭代优化算法,它通过沿目标函数梯度的负方向更新聚类中心来最小化目标函数。梯度下降法的更新公式为:
```
c_j^{(t+1)} = c_j^{(t)} - α ∇_c_j J(C)
```
其中:
- c_j^{(t)} 为第j个聚类中心在第t次迭代中的值
- α 为学习率
- ∇_c_j J(C) 为目标函数关于第j个聚类中心的梯度
#### 2.2.2 随机梯度下降法
随机梯度下降法是梯度下降法的变体,它一次只更新一个聚类中心,并使用随机梯度来估计目标函数的梯度。随机梯度下降法的更新公式为:
```
c_j^{(t+1)} = c_j^{(t)} - α ∇_c_j J(x_i, c)
```
其中:
- x_i 为随机选择的数据点
- ∇_c_j J(x_i, c) 为目标函数关于第j个聚类中心和数据点x_i的随机梯度
### 2.3 K均值聚类算法的收敛性分析
#### 2.3.1 收敛性定理
K均值聚类算法在满足一定条件下是收敛的。收敛性定理指出,如果目标函数J(C)是凸函数,并且聚类中心初始化合理,那么K均值聚类算法将收敛到局部最优解。
#### 2.3.2 收敛速度
K均值聚类算法的收敛速度取决于目标函数的形状、数据点的分布和聚类中心的初始化。一般来说,如果目标函数是凸的,并且聚类中心初始化合理,那么K均值聚类算法的收敛速度较快。
# 3.1 K均值聚类算法在图像处理中的应用
#### 3.1.1 图像分割
图像分割是将图像分解为具有不同特征(如颜色、纹理、形状等)的区域的过程。K均值聚类算法可以用于图像分割,具体步骤如下:
1. 将图像转换为像素点集合。
2. 选择初始聚类中心。
3. 计算每个像素点到每个聚类中心的距离。
4. 将每个像素点分配到距离其最近的聚类中心。
5. 更新聚类中心。
6. 重复步骤 3-5,直到聚类中心不再发生变化或达到预定的迭代次数。
#### 3.1.2 图像识别
图像识别是识别图像中对象的计算机视觉任务。K均值聚类算法可以用于图像识别,具体步骤如下:
1. 从图像中提取特征(如颜色、纹理、形状等)。
2. 将提取的特征聚类为不同的组。
3. 将每个组与已知的对象类关联。
4. 当新图像输入时,提取其特征并将其分配到最近的组。
5. 根据组的关联,识别图像中的对象。
**代码块:**
```python
import numpy as np
from sklearn.cluster import KMeans
# 加载图像
image = cv2.imread('image.jpg')
# 转换为像素点集合
pixels = image.reshape((-1, 3))
# KMeans 聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(pixels)
# 获取聚类中心
cluster_centers = kmeans.cluster_centers_
# 将像素点分配到聚类中心
labels = kmeans.labels_
# 可视化聚类结果
segmented_image = np.zeros_like(image)
for i in range(len(pixels)):
segmented_image[i] = cluster_centers[labels[i]]
# 显示聚类结果
cv2.imshow('Segmented Image', segmented_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**代码逻辑分析:**
* `cv2.imread('image.jpg')`:加载图像。
* `pixels = image.reshape((-1, 3))`:将图像转换为像素点集合,每个像素点包含 3 个颜色通道(RGB)。
* `kmeans = KMeans(n_clusters=3)`:初始化 KMeans 聚类器,指定聚类中心数量为 3。
* `kmeans.fit(pixels)`:对像素点集合进行聚类。
* `cluster_centers = kmeans.cluster_centers_`:获取聚类中心。
* `labels = kmeans.labels_`:获取每个像素点的聚类标签。
* `segmented_image = np.zeros_like(image)`:创建与原始图像大小相同的空图像,用于存储聚类结果。
* `for i in range(len(pixels)):`:遍历每个像素点。
* `segmented_image[i] = cluster_centers[labels[i]]`:将像素点分配到其最近的聚类中心。
* `cv2.imshow('Segmented Image', segmented_image)`:显示聚类结果。
# 4. K均值聚类算法的扩展与改进
### 4.1 K均值++算法
#### 4.1.1 算法原理
K均值++算法是一种改进的K均值聚类算法,它通过一种启发式方法选择初始聚类中心,从而提高算法的聚类质量。算法步骤如下:
1. 随机选择一个数据点作为第一个聚类中心。
2. 对于每个未分配的数据点,计算它到所有现有聚类中心的距离。
3. 选择距离最远的数据点作为下一个聚类中心。
4. 重复步骤2和3,直到选择出K个聚类中心。
#### 4.1.2 算法性能
K均值++算法与标准K均值算法相比,具有以下优点:
* 减少了陷入局部最优解的可能性。
* 提高了聚类质量,特别是对于非凸数据集。
* 降低了算法对初始聚类中心选择敏感性的影响。
### 4.2 模糊K均值算法
#### 4.2.1 算法原理
模糊K均值算法是一种软聚类算法,它允许数据点同时属于多个聚类。算法步骤如下:
1. 初始化聚类中心和模糊指数m(通常为2)。
2. 对于每个数据点,计算它到所有聚类中心的模糊隶属度。
3. 更新聚类中心,使其为所有数据点模糊隶属度的加权平均值。
4. 重复步骤2和3,直到算法收敛。
#### 4.2.2 算法性能
模糊K均值算法与标准K均值算法相比,具有以下优点:
* 能够处理重叠数据,因为它允许数据点同时属于多个聚类。
* 提高了聚类质量,特别是对于具有噪声或异常值的数据集。
* 提供了数据点到聚类中心的隶属度信息,这可以用于进一步的分析。
### 4.3 流式K均值算法
#### 4.3.1 算法原理
流式K均值算法是一种在线聚类算法,它可以处理不断流入的数据。算法步骤如下:
1. 初始化聚类中心和权重。
2. 对于每个新流入的数据点,计算它到所有聚类中心的距离。
3. 更新聚类中心和权重,以反映新数据点的影响。
4. 重复步骤2和3,直到算法收敛或达到预定义的迭代次数。
#### 4.3.2 算法性能
流式K均值算法与标准K均值算法相比,具有以下优点:
* 能够处理大规模和不断流入的数据。
* 降低了内存消耗,因为它不需要存储所有数据。
* 能够实时更新聚类结果,从而适应数据分布的变化。
# 5. K均值聚类算法的实际案例
### 5.1 案例1:客户细分
**背景:**一家零售公司希望根据客户的购买行为对其客户进行细分,以便更好地针对不同细分市场的营销活动。
**数据:**客户购买记录,包括客户ID、购买日期、购买商品、购买金额等信息。
**方法:**
1. **数据预处理:**对数据进行清洗和标准化,去除异常值和缺失值。
2. **特征工程:**提取客户购买行为的特征,例如购买频率、购买金额、购买类别等。
3. **聚类:**使用K均值聚类算法对客户进行聚类,将客户划分为不同的细分市场。
4. **细分市场分析:**分析不同细分市场的特征,例如人口统计信息、购买偏好、忠诚度等。
**结果:**
聚类算法将客户划分为三个细分市场:
* **高价值客户:**购买频率高、购买金额大、忠诚度高。
* **中度价值客户:**购买频率中等、购买金额中等、忠诚度中等。
* **低价值客户:**购买频率低、购买金额小、忠诚度低。
**应用:**
零售公司根据细分市场结果制定了针对性的营销活动:
* **高价值客户:**提供个性化服务、专属优惠和忠诚度奖励。
* **中度价值客户:**提供折扣和促销活动,鼓励他们增加购买频率和金额。
* **低价值客户:**重新评估营销策略,考虑是否继续针对此细分市场。
### 5.2 案例2:网络安全入侵检测
**背景:**一家网络安全公司希望使用K均值聚类算法检测网络入侵。
**数据:**网络流量数据,包括源IP地址、目标IP地址、端口号、数据包大小等信息。
**方法:**
1. **数据预处理:**对数据进行清洗和标准化,去除异常值和缺失值。
2. **特征工程:**提取网络流量的特征,例如数据包大小、端口号、源IP地址的地理位置等。
3. **聚类:**使用K均值聚类算法对网络流量进行聚类,将流量划分为不同的类别。
4. **入侵检测:**分析不同类别的特征,识别与已知入侵模式相似的流量。
**结果:**
聚类算法将网络流量划分为两个类别:
* **正常流量:**数据包大小正常、端口号常见、源IP地址合法。
* **可疑流量:**数据包大小异常、端口号罕见、源IP地址可疑。
**应用:**
网络安全公司使用可疑流量类别作为入侵检测的触发器:
* **当可疑流量超过一定阈值时,**触发警报并通知安全分析师。
* **安全分析师调查警报,**确定是否发生了实际入侵。
### 5.3 案例3:推荐系统
**背景:**一家电子商务网站希望使用K均值聚类算法为用户推荐商品。
**数据:**用户购买记录,包括用户ID、购买商品、购买日期等信息。
**方法:**
1. **数据预处理:**对数据进行清洗和标准化,去除异常值和缺失值。
2. **特征工程:**提取用户购买行为的特征,例如购买频率、购买类别、购买顺序等。
3. **聚类:**使用K均值聚类算法对用户进行聚类,将用户划分为不同的兴趣组。
4. **推荐:**根据用户的兴趣组,向用户推荐与该组其他用户购买行为相似的商品。
**结果:**
聚类算法将用户划分为三个兴趣组:
* **科技爱好者:**购买电子产品、软件和游戏。
* **时尚达人:**购买服装、配饰和美妆产品。
* **家居爱好者:**购买家具、家电和家居用品。
**应用:**
电子商务网站根据兴趣组结果为用户提供个性化的推荐:
* **科技爱好者:**推荐最新的电子产品和软件。
* **时尚达人:**推荐流行的服装和美妆产品。
* **家居爱好者:**推荐舒适的家具和实用的家居用品。
# 6. K均值聚类算法的总结与展望
### 6.1 K均值聚类算法的优点和缺点
**优点:**
* **简单易懂:**算法原理简单,易于理解和实现。
* **计算高效:**算法时间复杂度为 O(nkt),其中 n 为数据量,k 为聚类数,t 为迭代次数。
* **广泛适用:**适用于各种类型的数据,包括数值型、分类型和混合型数据。
* **鲁棒性强:**对异常值和噪声数据具有较强的鲁棒性。
**缺点:**
* **对初始聚类中心敏感:**算法的收敛结果受初始聚类中心的选择影响。
* **不能处理非凸形状的数据:**算法假设数据分布在凸形状的簇中,对于非凸形状的数据聚类效果不佳。
* **聚类数需预先指定:**算法需要预先指定聚类数,而实际应用中往往难以确定合适的聚类数。
* **容易产生局部最优:**算法采用贪心策略,容易陷入局部最优解,导致聚类结果不理想。
### 6.2 K均值聚类算法的发展趋势
近年来,K均值聚类算法的研究主要集中在以下几个方面:
* **改进初始化方法:**研究更有效的初始化方法,以提高算法的收敛速度和聚类质量。
* **处理非凸形状数据:**开发新的算法或改进现有算法,以处理非凸形状的数据聚类问题。
* **自动确定聚类数:**研究自动确定聚类数的方法,以避免人为指定聚类数的困难。
* **提高算法鲁棒性:**研究提高算法对异常值和噪声数据鲁棒性的方法。
### 6.3 K均值聚类算法的未来应用
随着数据量的不断增长和机器学习技术的不断发展,K均值聚类算法在未来将有广阔的应用前景,包括:
* **大数据分析:**用于处理海量数据,发现隐藏的模式和规律。
* **图像处理:**用于图像分割、目标检测和图像识别。
* **文本挖掘:**用于文本聚类、文本分类和主题模型。
* **生物信息学:**用于基因表达数据分析、蛋白质序列聚类和疾病诊断。
* **推荐系统:**用于个性化推荐和客户细分。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面解析 K 均值聚类算法,涵盖其原理、实战应用、数学奥秘、优缺点、实现与优化、数据挖掘、图像处理、自然语言处理、推荐系统、金融、医疗、零售、制造、交通、能源等领域的应用,以及最佳实践、常见问题、性能优化、扩展与变体等内容。通过深入浅出的讲解和丰富的案例,本专栏旨在帮助读者掌握 K 均值聚类算法,轻松应对数据聚类挑战,挖掘数据价值,做出明智决策,打造高效聚类模型。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB Curve Fitting Toolbox: Built-In Functions, Simplify the Fitting Process
# 1. Introduction to Curve Fitting
Curve fitting is a mathematical technique used to find a curve that optimally fits a given set of data points. It is widely used in various fields, including science, engineering, and medicine.
The process of curve fitting involves selecting an appropriate mathem
7 Applications of Partial Differential Equations in Fluid Mechanics: From Turbulence to Weather Forecasting
# 1. An Overview of Partial Differential Equations in Fluid Mechanics
Partial Differential Equations (PDEs) play a crucial role in fluid mechanics, describing the motion and behavior of fluids. PDEs in fluid mechanics are often highly nonlinear and require numerical methods for solution.
The appli
MATLAB Cross-Platform Compatibility for Reading MAT Files: Seamless Access to MAT Files Across Different Operating Systems
# Introduction to MAT Files
MAT files are a binary file format used by MATLAB to store data and variables. They consist of a header file and a data file, with the header containing information about the file version, data types, and variable names.
The version of MAT files is crucial for cross-pla
【栈与队列算法】:JavaScript中的算法设计与实践

# 1. 栈与队列数据结构概述
## 1.1 栈与队列的定义和重要性
栈和队列是两种最基础的线性数据结构,在计算机科学与信息技术中扮演着关键的角色。它们虽然简单,但应用广泛,是许多复杂数据结构与算法的基础构件。
- 栈(Stack)是一种后进先出(
【Practical Exercise】Communication Principles MATLAB Simulation: Partial Response System
# 1. Fundamental Principles of Communication
Communication principles are the science of how information is transmitted. It encompasses the generation, modulation, transmission, reception, and demodulation of signals.
**Signal** is the physical quantity that carries information, which can be eithe
Investigation of Fluid-Structure Coupling Analysis Techniques in HyperMesh
# 1. Introduction
- Research background and significance
- Overview of Hypermesh application in fluid-structure interaction analysis
- Objectives and summary of the research content
# 2. Introduction to Fluid-Structure Interaction Analysis
- Basic concepts of interaction between fluids and struct
Installation and Usage of Notepad++ on Different Operating Systems: Cross-Platform Use to Meet Diverse Needs
# 1. Introduction to Notepad++
Notepad++ is a free and open-source text editor that is beloved by programmers and text processors alike. It is renowned for its lightweight design, powerful functionality, and excellent cross-platform compatibility.
Notepad++ supports syntax highlighting and auto-co
【环形数据结构的错误处理】:JavaScript中环形数据结构的异常管理
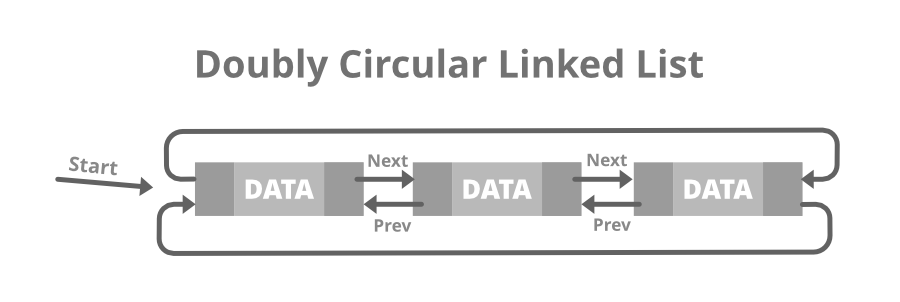
# 1. 环形数据结构的基本概念与JavaScript实现
## 1.1 环形数据结构简介
环形数据结构是一类在图论和数据结构中有广泛应用的特殊结构,它通常表现为一组数据元素以线性序列的形式连接,但其首尾相接,形成一个“环”。这种结构在计算机科学中尤其重要,因为它能够模拟很多现实中的循环关系,比如:链表、树的分
【浏览器缓存与CDN优化指南】:CDN如何助力前端缓存性能飞跃

# 1. 浏览器缓存与CDN的基本概念
在高速发展的互联网世界中,浏览器缓存和内容分发网络(CDN)是两个关键的技术概念,它们共同协作,以提供更快、更可靠的用户体验。本章将揭开这两个概念的神秘面纱,为您构建坚实的理解基础。
## 1.1 浏览器缓存简介
浏览器缓存是存储在用户本地终端上的一种临时存储。当用户访问网站时,浏览器会自动存储一些数据(例如HTML文档、图片、脚本等),以便在用户下次请求相同资源时能
【持久化与不变性】:JavaScript中数据结构的原则与实践

# 1. JavaScript中的数据结构原理
## 数据结构与算法的连接点
在编程领域,数据结构是组织和存储数据的一种方式,使得我们可以高效地进行数据访问和修改。JavaScript作为一种动态类型语言,具有灵活的数据结构处理能力,这使得它在处理复杂的前端逻辑时表现出色。
数据结构与算法紧密相关,算法的效率往往依赖于数据结构的选择。例如,数组提供对元素的快速访问,而链表则在元素的插入和删除操作上更为高效。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )