Flink和Alink的安装与配置指南
发布时间: 2023-12-23 23:44:45 阅读量: 83 订阅数: 37 
# 一、Flink和Alink简介
## 1.1 什么是Flink
Flink是一个分布式流处理引擎,提供高吞吐量、低延迟、Exactly-Once的状态一致性以及强大的事件时间处理等特性。它支持在一个系统中同时处理有界和无界的数据流,能够处理批处理和流处理任务。
Flink提供了丰富的API,包括DataStream API用于处理无界数据流、DataSet API用于处理有界数据集以及Table API用于关系型处理。
## 1.2 什么是Alink
Alink是阿里巴巴开源的一款机器学习算法库,提供了大量常用的机器学习算法实现,覆盖了分类、回归、聚类、推荐等多个领域。Alink能够在大规模数据上高效运行,并且与Flink紧密结合,能够无缝地使用Flink进行数据处理和Alink进行机器学习任务。
## 1.3 Flink和Alink的关系
Flink是一个流处理引擎,能够处理和计算数据流;而Alink是一个机器学习算法库,能够对数据进行建模和训练。Flink和Alink通过紧密集成,使得用户可以在Flink中直接使用Alink提供的机器学习算法,并且能够在Flink的流处理任务中实时应用机器学习模型。这种集成使得数据处理和机器学习变得更加高效和灵活。
### 二、安装Flink
Apache Flink是一个开源的流处理框架,具有高性能、容错、精确一次和状态一致性等特点。本章将介绍如何安装Flink。
#### 2.1 硬件和系统要求
在安装Flink之前,需要确保系统符合以下最低要求:
- 内存:建议至少4GB RAM
- 处理器:双核处理器
- 操作系统:Linux、Windows、MacOS
#### 2.2 下载和安装Flink
1. 访问Flink官网(https://flink.apache.org/)下载最新稳定版本的Flink。
2. 解压下载的文件到指定的目录,例如 `/opt/flink/`。
3. 进入 Flink 安装目录:`cd /opt/flink/`
#### 2.3 配置Flink环境变量
编辑 `~/.bashrc` 或 `~/.bash_profile` 文件,添加以下环境变量:
```bash
export FLINK_HOME=/opt/flink
export PATH=$FLINK_HOME/bin:$PATH
```
使修改生效:`source ~/.bashrc` 或 `source ~/.bash_profile`
### 三、配置Flink集群
Apache Flink可以以多种方式进行配置,包括单机模式、分布式模式和高可用性模式。在本节中,我们将介绍如何配置Flink集群。
#### 3.1 单机模式配置
单机模式是最简单的Flink配置。您可以在单台计算机上运行Flink作业,适用于本地开发和调试。
首先,下载并解压Flink安装包:
```bash
wget https://www.apache.org/dyn/closer.lua/flink/flink-1.13.2/flink-1.13.2-bin-scala_2.12.tgz
tar -xzf flink-1.13.2-bin-scala_2.12.tgz
cd flink-1.13.2
```
接下来,启动Flink单机模式:
```bash
./bin/start-cluster.sh
```
现在,您可以访问Web界面 `http://localhost:8081` 来监控单机Flink集群。
#### 3.2 分布式模式配置
在分布式模式下,Flink集群由多个计算节点组成,用于处理大规模数据。配置分布式Flink集群需要更多的步骤,包括修改配置文件和启动各个组件。
首先,在每台计算机上,修改 `conf/flink-conf.yaml` 文件,指定JobManager和TaskManager的地址。
然后,分别启动JobManager和TaskManager:
```bash
./bin/start-cluster.sh
```
#### 3.3 高可用性配置
高可用性模式用于保证Flink作业的稳定性和可靠性。在分布式模式下,您可以配置Flink集群以支持高可用性,包括配置ZooKeeper、设置检查点和故障恢复等。
要启用高可用性模式,请修改 `conf/flink-conf.yaml` 文件,并配置相关参数,例如:
```yaml
high-availability: zookeeper
high-availability.zookeeper.quorum: <ZooKeeper quorum>
```
然后,启动Flink集群:
```bash
./bin/start-cluster.sh
```
以上是Flink集群的配置方式,根据实际需求选择合适的模式进行配置。
### 四、安装Alink
Alink是一种基于Flink的机器学习库,它提供了各种经典和先进的机器学习算法。通过Alink,用户可以在Flink上构建和部署机器学习模型,并进行大规模的数据处理和机器学习训练。
#### 4.1 Alink的功能介绍
Alink内置了许多常见的机器学习算法,包括回归、分类、聚类、推荐和时序分析等,同时还支持自定义算法和特征工程。Alink能够处理大规模的数据,并且具有良好的扩展性和性能表现,使得用户能够在Flink上进行端到端的大规模数据处理和机器学习任务。
#### 4.2 下载和安装Alink
要安装Alink,首先需要确保已经安装了Flink,并且处于运行状态。然后可以通过以下步骤下载和安装Alink:
Step 1: 下载Alink压缩包
```bash
wget https://www.apache.org/dyn/closer.lua/flink/flink-1.13.3/alink-1.13.3-bin-scala_2.11.tgz
```
Step 2: 解压Alink压缩包
```bash
tar -xvf alink-1.13.3-bin-scala_2.11.tgz
```
Step 3: 配置Alink环境变量
```bash
export ALINK_HOME=/path/to/alink-1.13.3
export PATH=$PATH:$ALINK_HOME/bin
```
#### 4.3 配置Alink环境变量
在安装Alink后,需要配置Alink的环境变量,以便系统能够识别Alink的安装路径。在上一步中已经配置了Alink的环境变量,确保ALINK_HOME和PATH变量已正确设置,以便在命令行中使用Alink命令。
### 五、配置Alink
在本节中,我们将介绍如何配置Alink,包括数据连接配置、算法配置以及运行Alink任务的详细步骤。
#### 5.1 数据连接配置
Alink支持各种数据源的连接,包括关系型数据库、大数据存储系统等。在配置数据连接之前,需要确保已经安装并配置好相应的数据源驱动程序。
下面以连接MySQL数据库为例进行说明,首先需要在Alink的配置文件中添加MySQL数据库的相关配置信息:
```properties
# Alink配置文件 alink.properties
# MySQL连接配置
alink.jdbc.driver=com.mysql.jdbc.Driver
alink.jdbc.url=jdbc:mysql://localhost:3306/yourDB
alink.jdbc.user=yourUsername
alink.jdbc.password=yourPassword
```
在以上配置中,你需要将`yourDB`替换为你要连接的数据库名称,`yourUsername`替换为数据库的用户名,`yourPassword`替换为数据库密码。同时,需要将MySQL的JDBC驱动程序(`mysql-connector-java.jar`)放置在Alink的`lib`目录下。
#### 5.2 算法配置
Alink提供了丰富的机器学习算法库,通过配置可以轻松使用这些算法进行数据分析和建模。下面是一个简单的线性回归算法配置示例:
```json
{
"modelName": "linear_regression_model",
"modelType": "linear_regression",
"params": {
"featureColNames": ["feature1", "feature2"],
"labelColName": "label",
"predictionColName": "prediction",
"fitIntercept": true
}
}
```
在以上配置中,我们定义了一个线性回归模型,指定了特征列、标签列和预测列等信息。
#### 5.3 运行Alink任务
配置好数据连接和算法后,我们可以编写Alink任务的代码,并使用Alink提供的API来提交和运行任务。以下是一个简单的Alink任务示例,演示了如何读取MySQL数据并应用线性回归算法:
```java
import com.alibaba.alink.pipeline.Pipeline;
import com.alibaba.alink.pipeline.PipelineModel;
import com.alibaba.alink.pipeline.feature.VectorAssembler;
import com.alibaba.alink.pipeline.regression.LinearRegression;
import com.alibaba.alink.common.io.filesystem.BaseFileSystem;
import com.alibaba.alink.common.io.filesystem.FilePath;
// 读取MySQL数据
DataStream data = envTableEnv.sqlQuery("SELECT * FROM yourTable");
// 特征向量合并
VectorAssembler assembler = new VectorAssembler()
.setSelectedCols(new String[]{"feature1", "feature2"})
.setOutputCol("features");
// 线性回归
LinearRegression lr = new LinearRegression()
.setFeatureCols("features")
.setLabelCol("label")
.setPredictionCol("prediction")
.setWithIntercept(true);
// 构建Pipeline
Pipeline pipeline = new Pipeline().add(assembler).add(lr);
// 训练模型
PipelineModel model = pipeline.fit(data);
// 保存模型
BaseFileSystem.get(FilePath.fromString("hdfs://yourHdfsPath")).overwrite().save(model, "yourModelPath");
```
在以上代码中,我们使用Alink的API从MySQL中读取数据,并构建了一个Pipeline,包含了特征向量组合和线性回归算法。最后,我们将训练好的模型保存到HDFS中。
通过以上配置和示例代码,我们可以轻松地配置和运行Alink任务,实现数据分析和建模的功能。
### 六、Flink和Alink集成
Apache Flink和Alink在实时流处理和机器学习领域都有着广泛应用,它们的集成可以实现流处理和机器学习模型训练一体化。以下将介绍如何将Alink集成到Flink中,并利用Alink执行Flink任务的方法。
#### 6.1 将Alink集成到Flink中
在Flink任务中集成Alink,可以通过使用Alink提供的算法进行数据处理和特征提取。在Flink任务中,可以调用Alink的算法接口对数据进行处理,这样就能够充分利用Alink的机器学习能力。
首先,需要将Alink的依赖包添加到Flink的项目中,然后在Flink任务中引入Alink的算法类进行调用。具体步骤如下:
```java
// 引入Alink的依赖包
import com.alibaba.alink.common.AlinkParameter;
import com.alibaba.alink.operator.batch.BatchOperator;
import com.alibaba.alink.operator.batch.feature.VectorAssemblerBatchOp;
// 在Flink任务中调用Alink的算法类
public class FlinkAlinkIntegrationJob {
public static void main(String[] args) throws Exception {
// Flink任务代码
// 使用Alink的VectorAssembler算法进行特征提取
BatchOperator data = ... // 从Flink数据源获取数据
VectorAssemblerBatchOp vectorAssembler = new VectorAssemblerBatchOp()
.setSelectedCols(new String[]{"col1", "col2", "col3"})
.setOutputCol("features");
vectorAssembler.linkFrom(data).collect(); // 执行特征提取并输出结果
// 其他Flink任务代码
}
}
```
通过以上代码,就可以在Flink任务中调用Alink的算法类,实现Alink和Flink的集成。
#### 6.2 用Alink执行Flink任务
除了将Alink集成到Flink中,也可以使用Alink来执行Flink任务。这意味着可以在Alink的任务中调用Flink的API,实现在Alink任务中执行Flink的数据处理和流处理操作。具体步骤如下:
```java
// 引入Flink的依赖包
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.DataSet;
// 在Alink任务中调用Flink的API
public class AlinkFlinkExecutionJob {
public static void main(String[] args) throws Exception {
// 创建Flink的ExecutionEnvironment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从Alink的数据源中读取数据
DataSet<String> data = ... // 从Alink数据源获取数据
// 在Alink任务中执行Flink的map和reduce操作
DataSet<String> result = data.map(s -> s.toUpperCase())
.reduce((s1, s2) -> s1 + s2);
result.print(); // 输出执行结果
}
}
```
通过以上代码,就可以在Alink任务中调用Flink的API执行数据处理和流处理操作。
#### 6.3 使用Flink实时处理Alink产生的数据
在实际应用中,Alink可能用于离线的机器学习模型训练,而Flink用于实时的流处理任务。此时,可以通过Kafka等消息队列将Alink产生的数据发送给Flink,由Flink进行实时处理。具体步骤如下:
```java
// 在Flink任务中实时处理Alink产生的数据
public class FlinkRealTimeProcessingJob {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从Kafka中读取Alink产生的数据流
DataStream<String> alinkData = env.addSource(new FlinkKafkaConsumer<>("alink-topic", new SimpleStringSchema(), properties));
// 在Flink任务中进行实时处理
DataStream<String> result = alinkData.map(s -> s.toUpperCase())
.keyBy(s -> s.charAt(0))
.timeWindow(Time.seconds(5))
.reduce((s1, s2) -> s1 + s2);
result.print(); // 输出实时处理结果
env.execute("Flink Real Time Processing");
}
}
```
通过以上步骤,可以实现Flink对Alink产生的数据进行实时处理。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在基于Flink和Alink构建全端亿级实时用户画像系统。首先,我们将介绍Flink和Alink的概述,包括它们在实时流计算中的作用和优势。然后,我们会提供Flink和Alink的安装与配置指南,帮助读者快速搭建开发环境。接着,我们将深入学习Flink的DataStream API,并结合实例展示其使用方法。此外,我们将对Alink数据处理框架进行深入解析,包括训练与部署详解。随后,我们将通过实战案例展示Flink与Alink的配合:实时数据流处理的应用。专栏还会介绍Flink SQL这一实时流处理的新思路,并详细讲解模型评估、性能优化和模型集成与复用等关键技术。此外,我们还会探讨分布式机器学习框架选择与实践指南,并阐述Flink与Alink在云原生环境中的应用。最后,我们将讨论实时流计算中的数据时效性与准确性保障,并透彻深入解读Alink机器学习算法库。通过本专栏的学习,读者将能够掌握Flink和Alink构建全端亿级实时用户画像系统的关键技术和实践经验。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Java药店系统国际化与本地化:多语言支持的实现与优化
# 1. Java药店系统国际化与本地化的概念
## 1.1 概述
在开发面向全球市场的Java药店系统时,国际化(Internationalization,简称i18n)与本地化(Localization,简称l10n)是关键的技术挑战之一。国际化允许应用程序支持多种语言和区域设置,而本地化则是将应用程序具体适配到特定文化或地区的过程。理解这两个概念的区别和联系,对于创建一个既能满足
【多线程编程】:指针使用指南,确保线程安全与效率
# 1. 多线程编程基础
## 1.1 多线程编程的必要性
在现代软件开发中,为了提升程序性能和响应速度,越来越多的应用需要同时处理多个任务。多线程编程便是实现这一目标的重要技术之一。通过合理地将程序分解为多个独立运行的线程,可以让CPU资源得到有效利用,并提高程序的并发处理能力。
## 1.2 多线程与操作系统
多线程是在操作系统层面上实现的,操作系统通过线程调度算法来分配CPU时
【MySQL大数据集成:融入大数据生态】
# 1. MySQL在大数据生态系统中的地位
在当今的大数据生态系统中,**MySQL** 作为一个历史悠久且广泛使用的关系型数据库管理系统,扮演着不可或缺的角色。随着数据量的爆炸式增长,MySQL 的地位不仅在于其稳定性和可靠性,更在于其在大数据技术栈中扮演的桥梁作用。它作为数据存储的基石,对于数据的查询、分析和处理起到了至关重要的作用。
## 2.1 数据集成的概念和重要性
数据集成是
【数据库选型指南】:为在线音乐系统选择合适的数据库

# 1. 在线音乐系统对数据库的基本需求
## 1.1 数据存储和管理的必要性
在线音乐系统需要高效可靠地存储和管理大量的音乐数据,包括歌曲信息、用户数据、播放列表和听歌历史等。一个强大的数据库是实现这些功能的基础。
## 1.2 数据库功能和性能要求
该系统对数据库的功能和性能要求较高。需要支持高速的数据检索,
移动优先与响应式设计:中南大学课程设计的新时代趋势

# 1. 移动优先与响应式设计的兴起
随着智能手机和平板电脑的普及,移动互联网已成为人们获取信息和沟通的主要方式。移动优先(Mobile First)与响应式设计(Responsive Design)的概念应运而生,迅速成为了现代Web设计的标准。移动优先强调优先考虑移动用户的体验和需求,而响应式设计则注重网站在不同屏幕尺寸和设
mysql-connector-net-6.6.0云原生数据库集成实践:云服务中的高效部署

# 1. mysql-connector-net-6.6.0概述
## 简介
mysql-connector-net-6.6.0是MySQL官方发布的一个.NET连接器,它提供了一个完整的用于.NET应用程序连接到MySQL数据库的API。随着云
Rhapsody 7.0消息队列管理:确保消息传递的高可靠性

# 1. Rhapsody 7.0消息队列的基本概念
消息队列是应用程序之间异步通信的一种机制,它允许多个进程或系统通过预先定义的消息格式,将数据或者任务加入队列,供其他进程按顺序处理。Rhapsody 7.0作为一个企业级的消息队列解决方案,提供了可靠的消息传递、消息持久化和容错能力。开发者和系统管理员依赖于Rhapsody 7.0的消息队
【C++内存泄漏检测】:有效预防与检测,让你的项目无漏洞可寻

# 1. C++内存泄漏基础与危害
## 内存泄漏的定义和基础
内存泄漏是在使用动态内存分配的应用程序中常见的问题,当一块内存被分配后,由于种种原因没有得到正确的释放,从而导致系统可用内存逐渐减少,最终可能引起应用程序崩溃或系统性能下降。
## 内存泄漏的危害
Java中间件服务治理实践:Dubbo在大规模服务治理中的应用与技巧
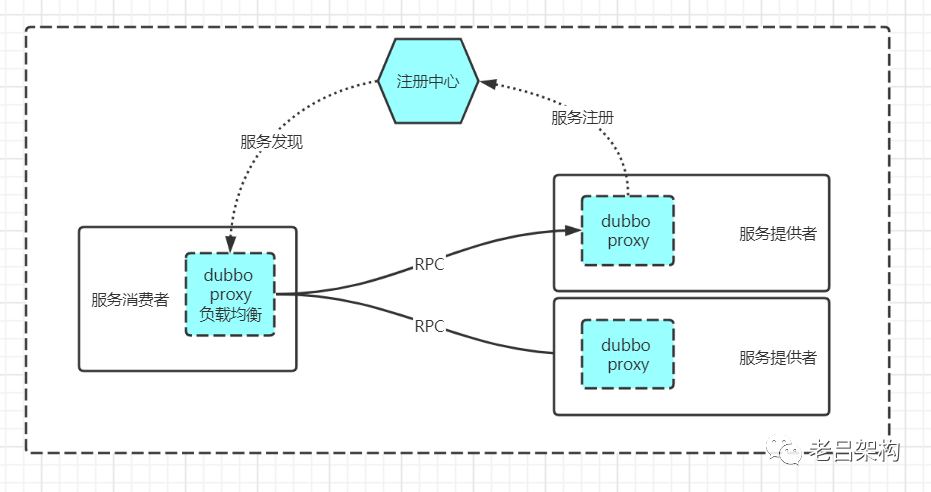
# 1. Dubbo框架概述及服务治理基础
## Dubbo框架的前世今生
Apache Dubbo 是一个高性能的Java RPC框架,起源于阿里巴巴的内部项目Dubbo。在2011年被捐赠给Apache,随后成为了Apache的顶级项目。它的设计目标是高性能、轻量级、基于Java语言开发的SOA服务框架,使得应用可以在不同服务间实现远程方法调用。随着微服务架构
大数据量下的性能提升:掌握GROUP BY的有效使用技巧
# 1. GROUP BY的SQL基础和原理
## 1.1 SQL中GROUP BY的基本概念
SQL中的`GROUP BY`子句是用于结合聚合函数,按照一个或多个列对结果集进行分组的语句。基本形式是将一列或多列的值进行分组,使得在`SELECT`列表中的聚合函数能在每个组上分别计算。例如,计算每个部门的平均薪水时,`GROUP BY`可以将员工按部门进行分组。
## 1.2 GROUP BY的工作原理
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )