【进阶】梯度下降与优化算法概述
发布时间: 2024-06-26 20:20:12 阅读量: 67 订阅数: 123 

优化算法-梯度下降法.ppt

# 1. 梯度下降算法概述**
梯度下降算法是一种迭代优化算法,用于最小化目标函数。其基本原理是沿着目标函数梯度的负方向迭代更新参数,使得目标函数值逐渐减小。梯度下降算法在机器学习、深度学习等领域有着广泛的应用,是优化问题的核心算法之一。
# 2.1 梯度和方向导数
**梯度**
对于一个多元函数 \(f(x_1, x_2, ..., x_n)\),其梯度是一个向量,表示函数在该点各方向上的变化率。梯度记为:
```
∇f(x) = [∂f/∂x_1, ∂f/∂x_2, ..., ∂f/∂x_n]
```
其中,\(∂f/∂x_i\) 表示函数 \(f(x)\) 对变量 \(x_i\) 的偏导数。
**方向导数**
方向导数表示函数沿特定方向的变化率。对于一个函数 \(f(x)\) 和一个单位向量 \(u\),函数沿 \(u\) 方向的方向导数定义为:
```
D_uf(x) = lim_{h→0} [f(x + hu) - f(x)]/h
```
其中,\(h\) 是一个实数。
方向导数与梯度之间的关系为:
```
D_uf(x) = ∇f(x) · u
```
这表明方向导数是梯度在该方向上的投影。
**例:**
考虑函数 \(f(x, y) = x^2 + y^2\)。
- 梯度:∇f(x, y) = [2x, 2y]
- 沿单位向量 \(u = [1/√2, 1/√2]\) 的方向导数:
```
D_uf(x, y) = ∇f(x, y) · u = [2x, 2y] · [1/√2, 1/√2] = √2(x + y)
```
# 3. 梯度下降算法的实践应用
### 3.1 线性回归中的梯度下降法
**简介**
线性回归是一种广泛用于预测和建模的监督学习算法。它假设目标变量与输入变量之间存在线性关系。梯度下降法可以用来优化线性回归模型的参数,以最小化预测误差。
**步骤**
1. **初始化参数:**设置模型参数(权重和偏置)的初始值。
2. **计算梯度:**计算损失函数关于每个参数的梯度。
3. **更新参数:**使用梯度下降公式更新参数,即:
```python
参数 = 参数 - 学习率 * 梯度
```
4. **重复步骤 2-3:**直到满足收敛条件(例如,损失函数变化小于某个阈值)。
**代码示例**
```python
import numpy as np
def linear_regression_gd(X, y, learning_rate=0.01, max_iter=1000):
"""
使用梯度下降法训练线性回归模型。
参数:
X: 特征矩阵。
y: 目标变量。
learning_rate: 学习率。
max_iter: 最大迭代次数。
返回:
权重和偏置。
"""
# 初始化参数
w = np.zeros(X.shape[1])
b = 0
# 损失函数
def loss(w, b):
return np.mean((np.dot(X, w) + b - y) ** 2)
# 梯度
def gradient(w, b):
return 2 * np.mean(X * (np.dot(X, w) + b - y)[:, np.newaxis], axis=0), 2 * np.mean(np.dot(X, w) + b - y)
# 迭代
for i in range(max_iter):
# 计算梯度
grad_w, grad_b = gradient(w, b)
# 更新参数
w -= learning_rate * grad_w
b -= learning_rate * grad_b
# 计算损失函数
loss_val = loss(w, b)
# 打印损失函数
if i % 100 == 0:
print("迭代次数:", i, "损失函数:", loss_val)
return w, b
```
### 3.2 逻辑回归中的梯度下降法
**简介**
逻辑回归是一种用于二分类问题的监督学习算法。它假设目标变量服从伯努利分布,并使用 sigmoid 函数将输入变量映射到概率值。梯度下降法可以用来优化逻辑回归模型的参数,以最大化似然函数。
**步骤**
1. **初始化参数:**设置模型参数(权重和偏置)的初始值。
2. **计算梯度:**计算损失函数关于每个参数的梯度。
3. **更新参数:**使用梯度下降公式更新参数,即:
```python
参数 = 参数 - 学习率 * 梯度
```
4. **重复步骤 2-3:**直到满足收敛条件(例如,损失函数变化小于某个阈值)。
**代码示例**
```python
import numpy as np
def logistic_regression_gd(X, y, learning_rate=0.01, max_iter=1000):
"""
使用梯度下降法训练逻辑回归模型。
参数:
X: 特征矩阵。
y: 目标变量。
learning_rate: 学习率。
max_iter: 最大迭代次数。
返回:
权重和偏置。
"""
# 初始化参数
w = np.zeros(X.shape[1])
b = 0
# 损失函数
def loss(w, b):
return -np.mean(y * np.log(sigmoid(np.dot(X, w) + b)) + (1 - y) * np.log(1 - sigmoid(np.dot(X, w) + b)))
# 梯度
def gradient(w, b):
return
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了涵盖 Python 编程、数据科学、深度学习和机器学习各个方面的全面教程。从 Python 基础知识和 NumPy、Pandas、Matplotlib 等库的入门,到神经网络、卷积神经网络和循环神经网络等深度学习概念的深入探索,本专栏提供了全面的学习路径。
专栏中包含了丰富的实战项目,涵盖图像分类、自然语言处理、计算机视觉、语音识别、自然语言生成、自动驾驶、人脸识别、机器翻译、推荐系统、异常检测、聊天机器人、医疗诊断、股票预测、物体检测、图像分割和时间序列预测等领域。这些项目提供了动手实践的机会,让读者可以将所学知识应用于实际问题中。
本专栏旨在为初学者和经验丰富的从业者提供一个全面的学习资源,帮助他们掌握 Python 编程、数据科学和深度学习领域的技能。通过循序渐进的教程和丰富的实战项目,读者可以深入了解这些领域的各个方面,并为在这些领域取得成功做好准备。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从0到1:打造SMPTE SDI视频传输解决方案,pg071-v-smpte-sdi应用实践揭秘

# 摘要
随着数字媒体技术的发展,SMPTE SDI视频传输技术已成为广播电视台和影视制作中心的重要标准。本文首先概述了SMPTE SDI技术的原理、标准及接口设备,其次详细分析了基于SMPTE SDI的视频传输解决方案的
【深入探究Word表格边框故障】:原因分析与对策
# 摘要
本论文专注于Word表格边框的构成、功能以及相关的故障类型与影响。通过对表格边框渲染机制和设计原则的理论分析,探讨了软件兼容性、硬件资源限制和用户操作习惯等因素导致的边框故障。提出了一套系统的故障诊断与解决方法,并通过案例分析展示了实际问题的解决过程。最后,论文详细论述了表格边框故障的预防与维护策略,包括建立
【物体建模进阶】:VB布尔运算技巧从入门到精通

# 摘要
本文综合探讨了布尔运算在物体建模领域的理论与实践应用。首先,介绍了布尔运算的基础理论,包括基本概念、规则和性质,并在三维空间中的应用进行了深入分析。其次,通过VB编程语言的实例展示了布尔运算的实现技巧,涵盖了语言基础、内置函数以及代码逻辑优化。文章进一步探讨了布尔运算在3D建模软件中的应用,分析了建模工具的实际案例,并提出了错误处理和优化建议。最后,本文探索了高级布尔建模技巧以及布尔运算在艺术创作中的
【Cortex-M4处理器架构详解】:从寄存器到异常处理的系统剖析
# 摘要
本文全面介绍了Cortex-M4处理器的架构、高级特性和编程技术。首先概述了处理器的核心组成及其基础架构,重点分析了内存管理单元(MMU)的工作原理和异常处理机制。接下来,文中深入探讨了Cortex-M4的高级特性,包括中断系统、调试与跟踪技术以及电源管理策略。然后,文章详细阐述了Cortex-M4的指令集特点、汇编语言编程以及性能优化方法。最后,本文针对Cortex-M4的硬件接口和外设功能,如总线标准、常用外设的控制和外设通信接口进行了分析,并通过实际应用案例展示了实时操作系统(RTOS)的集成、嵌入式系统开发流程及其性能评估和优化。整体而言,本论文旨在为工程师提供全面的Cort
【技术对比】:Flash vs WebGL,哪种更适合现代网页开发?

# 摘要
本文全面比较了Flash与WebGL技术的发展、架构、性能、开发实践以及安全性与兼容性问题,并探讨了两者的未来趋势。文章首先回顾了Flash的历史地位及WebGL与Web标准的融合,接着对比分析了两者在功能性能、第三方库支持、运行时表现等方面的差异。此外,文章深入探讨了各自的安全性和兼容性挑战,以及在现
零基础LabVIEW EtherCAT通讯协议学习手册:起步到精通
# 摘要
随着工业自动化和控制系统的不断发展,LabVIEW与EtherCAT通讯协议结合使用,已成为提高控制效率和精度的重要技术手段。本文首先介绍了LabVIEW与EtherCAT通讯协议的基础概念和配置方法,然后深入探讨了在LabVIEW环境下实现EtherCAT通讯的编程细节、控制策略以及诊断和错误处理。接下来,文章通过实际应用案例,分析了La
51单片机电子密码锁设计:【项目管理】与【资源规划】的高效方法
# 摘要
本文综述了51单片机电子密码锁的设计与实现过程,并探讨了项目管理在该过程中的应用。首先,概述了51单片机电子密码锁的基本概念及其在项目管理理论与实践中的应用。接下来,深入分析了资源规划的策略与实
【探索TouchGFX v4.9.3高级功能】:动画与图形处理的终极指南

# 摘要
TouchGFX作为一个面向嵌入式显示系统的图形库,具备强大的核心动画功能和图形处理能力。本文首先介绍了TouchGFX v4.9.3的安装与配置方法,随后深入解析了其核心动画功能,包括动画类型、实现机制以及性能优化策略。接着,文中探讨了图形资源管理、渲染技术和用户界面优化,以提升图形处理效率。通过具体案例分析,展示了TouchGFX
【Docker持久化存储】:阿里云上实现数据不丢失的3种方法
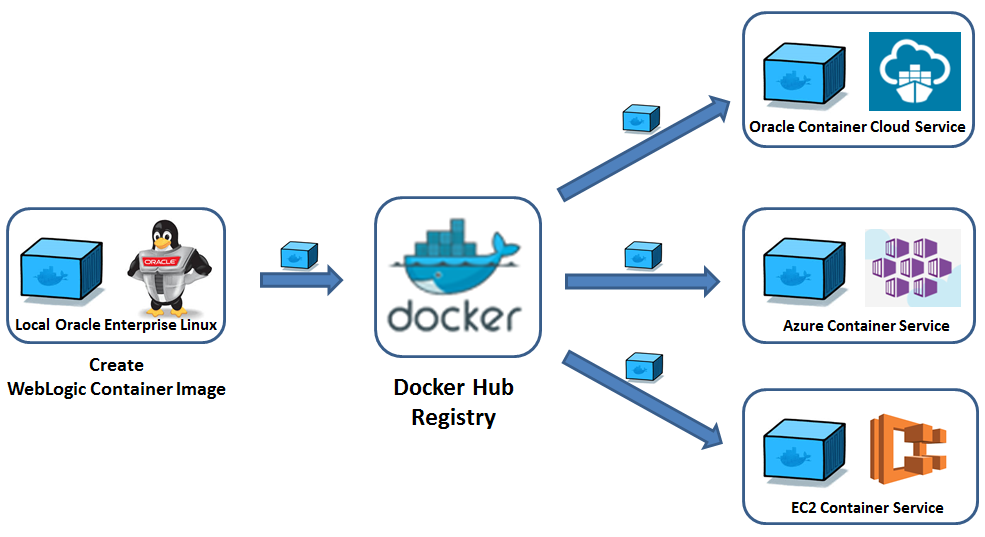
# 摘要
本文详细探讨了Docker持久化存储的概述、基础知识、在阿里云环境下的实践、数据持久化方案的优化与管理,以及未来趋势与技术创新。首先介绍了Docker卷的基本概念、类型和操作实践,然后聚焦于阿里云环境,探讨了如何在阿里云ECS、RDS和NAS服务中实现高效的数据持久化。接着,文章深入分析了数据备份与恢复策略,监控数据持久化状态的重要性以及性能优化与故障排查方法。最后,展望了
【编程进阶之路】:ITimer在优化机器人流程中的最佳实践

# 摘要
ITimer作为一种定时器技术,广泛应用于编程和机器人流程优化中。本文首先对ITimer的基础知识和应用进行了概述,随后深入探讨了其内部机制和工作原理,包括触发机制和事件调度中的角色,以及核心数据结构的设计与性能优化。文章进一步通过具体案例,阐述了ITimer在实时任务调度、缓存机制构建以及异常处理与恢复流程中的应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )