R 语言基本数据结构与操作
发布时间: 2024-02-02 13:19:27 阅读量: 61 订阅数: 22 
# 1. 介绍R语言的基本数据结构
## 1.1 R语言的数据类型概述
R 语言是一种专门用于数据处理和统计分析的编程语言,它具有丰富的数据类型,可以更好地适应数据分析的需求。
## 1.2 向量(Vectors)
向量是 R 语言中最基本的数据结构之一,它由相同类型的元素组成,可以是数值、字符或逻辑值等。
```r
# 创建数值向量
numeric_vector <- c(1, 2, 3, 4, 5)
# 创建字符向量
character_vector <- c("apple", "banana", "orange")
# 创建逻辑值向量
logical_vector <- c(TRUE, FALSE, TRUE)
```
## 1.3 列表(Lists)
列表是一种可以包含不同数据类型元素的数据结构,在 R 中用 `list` 创建。
```r
# 创建列表
my_list <- list(name = "Alice", age = 25, favorite_fruit = "apple")
```
## 1.4 数组(Arrays)
数组是具有相同数据类型的多维数据结构,在 R 中由函数 `array` 创建。
```r
# 创建数组
my_array <- array(1:12, dim = c(3, 2, 2))
```
## 1.5 矩阵(Matrices)
矩阵是二维数组的一种特殊形式,所有元素必须是同一种类型,在 R 中可以用 `matrix` 创建。
```r
# 创建矩阵
my_matrix <- matrix(1:6, nrow = 2, ncol = 3)
```
## 1.6 因子(Factors)
因子是一种用于表示分类数据的特殊向量,在 R 中通常用于统计建模。
```r
# 创建因子
my_factor <- factor(c("A", "B", "A", "B", "C"))
```
## 1.7 数据框(Data frames)
数据框是 R 中最常见的数据结构,类似于电子表格,每列可以包含不同的数据类型。
```r
# 创建数据框
name <- c("Alice", "Bob", "Cathy")
age <- c(25, 28, 30)
favorite_fruit <- c("apple", "banana", "orange")
my_df <- data.frame(name, age, favorite_fruit)
```
以上是 R 语言的基本数据结构,熟练掌握这些数据结构将有助于更高效地进行数据处理和分析。
# 2. 向量操作
### 2.1 创建向量
在R语言中,可以使用`c()`函数来创建向量。该函数可以将多个元素组合成一个向量。
```R
# 创建一个数值向量
numbers <- c(1, 2, 3, 4, 5)
print(numbers)
# 创建一个字符向量
names <- c("Alice", "Bob", "Charlie")
print(names)
# 创建一个逻辑向量
logicals <- c(TRUE, FALSE, TRUE)
print(logicals)
```
### 2.2 向量的索引
向量中的元素可以通过索引进行访问。在R语言中,索引是从1开始的。
```R
numbers <- c(1, 2, 3, 4, 5)
# 访问第一个元素
print(numbers[1])
# 访问前三个元素
print(numbers[1:3])
# 使用负索引来排除特定的元素
print(numbers[-4])
```
### 2.3 向量的切片
除了单个元素的索引访问,还可以通过切片来获取向量中的多个连续元素。
```R
numbers <- c(1, 2, 3, 4, 5)
# 获取第2至第4个元素
print(numbers[2:4])
# 获取第1、第3、第5个元素
print(numbers[c(1, 3, 5)])
```
### 2.4 向量的运算
R语言中的向量可以进行各种数学运算,例如加法、减法、乘法、除法等。
```R
numbers1 <- c(1, 2, 3)
numbers2 <- c(4, 5, 6)
# 向量加法
result1 <- numbers1 + numbers2
print(result1)
# 向量减法
result2 <- numbers2 - numbers1
print(result2)
# 向量乘法
result3 <- numbers1 * numbers2
print(result3)
# 向量除法
result4 <- numbers2 / numbers1
print(result4)
```
以上是向量操作的基本内容,通过熟悉向量的创建、索引、切片和运算,可以更加灵活地处理和操作数据。
# 3. 列表与矩阵操作
在R语言中,列表与矩阵是常用的数据结构,本章将介绍如何创建、索引、切片和进行运算操作。
#### 3.1 创建列表与矩阵
##### 创建列表
在R语言中,可以使用`list()`函数创建一个列表,例如:
```R
# 创建一个列表
my_list <- list("apple", 3, TRUE)
print(my_list)
```
##### 创建矩阵
使用`matrix()`函数可以创建一个矩阵,例如:
```R
# 创建一个3x3的矩阵
my_matrix <- matrix(1:9, nrow = 3, ncol = 3)
print(my_matrix)
```
#### 3.2 列表与矩阵的索引
##### 列表索引
对列表进行索引时,可以使用`[[index]]`或`$name`的方式,例如:
```R
# 通过索引获取列表元素
print(my_list[[2]])
# 通过名称获取列表元素
print(my_list$name)
```
##### 矩阵索引
对矩阵进行索引时,可以使用`[row, col]`的方式,例如:
```R
# 获取矩阵元素
print(my_matrix[1, 2])
```
#### 3.3 列表与矩阵的切片
##### 列表切片
对列表进行切片时,可以使用`[start:end]`的方式,例如:
```R
# 对列表进行切片
print(my_list[1:2])
```
##### 矩阵切片
对矩阵进行切片时,也可以使用`[row, col]`的方式,例如:
```R
# 对矩阵进行切片
print(my_matrix[1:2, 2:3])
```
#### 3.4 列表与矩阵的运算
##### 列表运算
对列表进行运算时,可以直接使用`+`、`-`、`*`、`/`等运算符,例如:
```R
# 列表运算示例
list1 <- list(1, 2, 3)
list2 <- list(4, 5, 6)
result <- list1 + list2
print(result)
```
##### 矩阵运算
对矩阵进行运算时,同样可以使用`+`、`-`、`*`、`/`等运算符,例如:
```R
# 矩阵运算示例
matrix1 <- matrix(1:4, nrow = 2, ncol = 2)
matrix2 <- matrix(5:8, nrow = 2, ncol = 2)
result <- matrix1 * matrix2
print(result)
```
本章介绍了如何创建列表与矩阵,并且演示了它们的索引、切片和运算操作,这些操作在实际数据处理中非常常见。
# 4. 因子与数据框操作
在本章中,我们将深入探讨在R语言中如何操作因子(Factors)和数据框(Data frames)。因子是一种用于表示分类数据的特殊数据类型,而数据框则是一种以表格形式存储的数据结构,类似于SQL中的表格。我们将介绍创建因子与数据框的方法,以及它们的索引、切片和运算等操作。让我们一起来看看吧。
### 4.1 创建因子与数据框
#### 4.1.1 创建因子
在R语言中,我们可以使用`factor()`函数来创建因子。下面是一个简单的例子,我们创建一个表示血型的因子:
```R
# 创建血型因子
blood_type <- factor(c("A", "B", "O", "AB", "A", "O"))
# 打印因子
print(blood_type)
```
在上面的例子中,我们使用`factor()`函数将字符向量转换为因子,然后打印出该因子的内容。
#### 4.1.2 创建数据框
数据框可以通过`data.frame()`函数进行创建,下面是一个简单的例子,我们创建一个包含姓名和年龄的数据框:
```R
# 创建数据框
name <- c("Tom", "Jerry", "Alice", "Bob")
age <- c(25, 30, 28, 22)
data <- data.frame(name, age)
# 打印数据框
print(data)
```
在上面的例子中,我们使用`data.frame()`函数将姓名和年龄两个向量合并成一个数据框,并打印出该数据框的内容。
### 4.2 因子与数据框的索引
#### 4.2.1 索引因子
因子的索引可以通过下标或因子水平(levels)的方式进行。下面是一个简单的例子:
```R
# 根据下标索引因子
print(blood_type[3])
# 根据因子水平索引因子
print(blood_type[blood_type == "A"])
```
在上面的例子中,我们展示了如何根据下标和因子水平来索引因子的操作。
#### 4.2.2 索引数据框
数据框的索引与一般的矩阵类似,可以使用`[行, 列]`的方式进行索引。下面是一个简单的例子:
```R
# 根据行索引数据框
print(data[2, ])
# 根据列索引数据框
print(data[, "age"])
```
在上面的例子中,我们展示了如何根据行和列来索引数据框的操作。
### 4.3 因子与数据框的切片
与索引类似,因子和数据框也支持切片操作。下面是一个简单的例子:
```R
# 切片因子
print(blood_type[2:4])
# 切片数据框
print(data[1:3, ])
```
在上面的例子中,我们展示了如何对因子和数据框进行切片操作。
### 4.4 因子与数据框的运算
因子和数据框也支持一些基本的运算操作,例如合并、拆分等。下面是一个简单的例子:
```R
# 合并数据框
data2 <- data.frame(name = c("Lily", "David"), age = c(27, 29))
merged_data <- rbind(data, data2)
print(merged_data)
# 拆分数据框
split_data <- split(merged_data, merged_data$name)
print(split_data)
```
在上面的例子中,我们展示了如何合并和拆分数据框的操作。
至此,我们已经学习了因子与数据框的基本操作,包括创建、索引、切片和运算等。希望这些内容能够帮助你更好地理解和运用R语言中的因子与数据框。
# 5. 复杂数据结构的操作
在实际的数据分析中,我们经常会遇到一些复杂的数据结构,如多维数组、嵌套列表、多重因子等。本章将介绍如何对这些复杂的数据结构进行索引、切片、转换与重塑。
### 5.1 索引与切片的高级技巧
在处理复杂数据结构时,我们需要掌握一些高级的索引与切片技巧来提取所需的数据。以下是一些常用的方法:
#### 5.1.1 多维数组的索引与切片
多维数组是由多个向量按照一定的规则组合而成的数据结构。我们可以使用`[ ]`运算符来进行索引与切片。下面是一个例子:
```python
import numpy as np
# 创建一个3行3列的二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 使用索引获取某个元素
element = arr[0, 1] # 获取第一行第二列的元素
print(element) # 输出结果: 2
# 使用切片获取某一行或某几行
row = arr[1, :] # 获取第二行的所有元素
print(row) # 输出结果: [4 5 6]
# 使用切片获取某一列或某几列
column = arr[:, 2] # 获取第三列的所有元素
print(column) # 输出结果: [3 6 9]
# 使用切片获取某个区域
region = arr[1:, :2] # 获取第二行及以后的行,第一列及以前的列
print(region) # 输出结果: [[4 5]
# [7 8]]
```
#### 5.1.2 嵌套列表的索引与切片
嵌套列表是一个列表中包含了其他列表的数据结构。我们可以使用`[ ]`运算符与循环遍历来进行索引与切片。以下是一个例子:
```python
# 创建一个嵌套列表
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 使用索引获取某个元素
element = nested_list[0][1] # 获取第一个列表的第二个元素
print(element) # 输出结果: 2
# 使用循环遍历获取某一行或某几行
rows = [nested_list[i] for i in range(1, len(nested_list))] # 获取第二个列表及以后的列表
print(rows) # 输出结果: [[4, 5, 6], [7, 8, 9]]
# 使用循环遍历获取某一列或某几列
columns = [nested_list[i][2] for i in range(len(nested_list))] # 获取每个列表的第三个元素
print(columns) # 输出结果: [3, 6, 9]
# 使用循环遍历获取某个区域
region = [nested_list[i][:2] for i in range(1, len(nested_list))] # 获取第二个列表及以后的列表的前两个元素
print(region) # 输出结果: [[4, 5], [7, 8]]
```
### 5.2 数据结构的转换与重塑
在处理复杂数据结构时,有时我们需要进行数据结构的转换或重塑以便更好地进行分析。以下是一些常用的方法:
#### 5.2.1 多维数组的转换与重塑
在NumPy中,我们可以使用`reshape()`函数来进行多维数组的形状变换。以下是一个例子:
```python
import numpy as np
# 创建一个4行3列的二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
# 将二维数组转换为3行4列的二维数组
reshaped_arr = arr.reshape(3, 4)
print(reshaped_arr)
# 输出结果:
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
# 将二维数组转换为一维数组
flattened_arr = arr.flatten()
print(flattened_arr)
# 输出结果: [ 1 2 3 4 5 6 7 8 9 10 11 12]
```
#### 5.2.2 列表的转换与重塑
在Python中,我们可以使用`zip()`函数来进行列表的转换与重塑。以下是一个例子:
```python
# 创建一个原始列表
original_list = [1, 2, 3, 4, 5, 6]
# 将列表分割为两个子列表
list1, list2 = zip(*[(original_list[i], original_list[i+3]) for i in range(3)])
print(list1) # 输出结果: (1, 4)
print(list2) # 输出结果: (2, 5)
```
### 5.3 数据的合并与拆分
在数据分析中,有时我们需要将多个数据结构合并或拆分以方便分析。以下是一些常用的方法:
#### 5.3.1 数据结构的合并
在Python中,我们可以使用`+`运算符来合并数据结构。以下是一个例子:
```python
# 合并两个列表
list1 = [1, 2, 3]
list2 = [4, 5, 6]
merged_list = list1 + list2
print(merged_list) # 输出结果: [1, 2, 3, 4, 5, 6]
# 合并两个多维数组
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[5, 6]])
merged_arr = np.concatenate((arr1, arr2), axis=0)
print(merged_arr)
# 输出结果:
# [[1 2]
# [3 4]
# [5 6]]
```
#### 5.3.2 数据结构的拆分
在Python中,我们可以使用索引与切片来拆分数据结构。以下是一个例子:
```python
# 拆分列表
merged_list = [1, 2, 3, 4, 5, 6]
split_list1 = merged_list[:3]
split_list2 = merged_list[3:]
print(split_list1) # 输出结果: [1, 2, 3]
print(split_list2) # 输出结果: [4, 5, 6]
# 拆分多维数组
merged_arr = np.array([[1, 2], [3, 4], [5, 6]])
split_arr1 = merged_arr[:2, :]
split_arr2 = merged_arr[2:, :]
print(split_arr1)
# 输出结果:
# [[1 2]
# [3 4]]
print(split_arr2) # 输出结果: [[5 6]]
```
以上是关于复杂数据结构的操作的基本内容,掌握了这些技巧后,我们可以更灵活地处理各种数据结构。在下一章节中,我们将介绍R语言中常用的数据操作函数。
# 6. 数据结构的相关函数与包
R语言提供了丰富的数据操作函数和数据处理包,可以帮助用户更高效地操作和处理数据。本章将介绍R语言中常用的数据操作函数、数据处理包以及数据可视化方法。
### 6.1 R语言中常用的数据操作函数
在R语言中,有许多内置的函数可以用于数据操作,例如:
- `which()`: 用于确定向量中满足特定条件的元素索引。
- `subset()`: 可以从数据框中选择符合特定条件的子集。
- `merge()`: 用于将两个数据框按照一定的条件合并。
- `aggregate()`: 用于数据聚合操作,可以对数据按照条件进行分组并进行统计。
- `transform()`: 用于在数据框中添加新的列。
这些函数可以帮助用户快速地对数据进行筛选、合并、聚合等操作,提高了数据处理的效率和灵活性。
### 6.2 R语言中常用的数据处理包介绍
除了内置函数外,R语言还有许多优秀的数据处理包,例如:
- `dplyr`包:提供了一套功能强大且一致的数据操作函数,如`mutate()`、`filter()`、`summarise()`等,可以大幅简化数据操作流程。
- `tidyr`包:用于数据的整洁化和重塑,包括`gather()`、`spread()`等函数,可以帮助用户更好地处理数据。
- `ggplot2`包:是R语言中最著名的数据可视化包,提供了丰富多样的绘图函数,用户可以轻松创建漂亮的统计图表。
- `reshape2`包:提供了数据重塑和转换的函数,如`melt()`和`dcast()`,可以帮助用户进行数据结构转换操作。
这些包的使用大大丰富了R语言的数据处理能力,使得用户可以更加便捷地进行数据操作和可视化。
### 6.3 R语言中的数据可视化方法
数据可视化是数据分析中至关重要的一环,R语言提供了丰富多样的数据可视化方法,包括基础绘图函数和各种专业的可视化包,如`ggplot2`、`plotly`等。用户可以根据数据的特点和分析目的选择合适的可视化方法,将数据更直观地呈现出来。
在本章中,我们将会详细介绍这些数据操作函数和数据处理包的使用方法,以及如何利用R语言进行数据可视化,帮助读者更好地理解和运用R语言进行数据分析和处理。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《R语言数据分析基础与应用》专栏涵盖了R语言在数据分析领域的基础知识和实际应用,旨在帮助读者快速掌握R语言的数据分析技能。专栏以"R 语言简介与环境搭建"作为开篇,逐步介绍了R语言的基本数据结构与操作、数据可视化基础、数据清洗与预处理、线性回归与相关性分析等内容。同时,专栏还涵盖了数据挖掘、时间序列分析、文本挖掘、网络分析、深度学习和地理空间数据可视化等领域的进阶知识。读者将通过专栏学习到如何利用R语言进行数据挖掘、对时间序列进行分析、应用深度学习技术处理数据等内容,从而全面提升在数据分析领域的能力。本专栏将对读者进行全方位的训练,使其掌握R语言数据分析的基础理论和实际操作技能,成为数据分析领域的专业人士。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【性能优化】:提升Virtex-5 FPGA RocketIO GTP Transceiver效率的实用指南
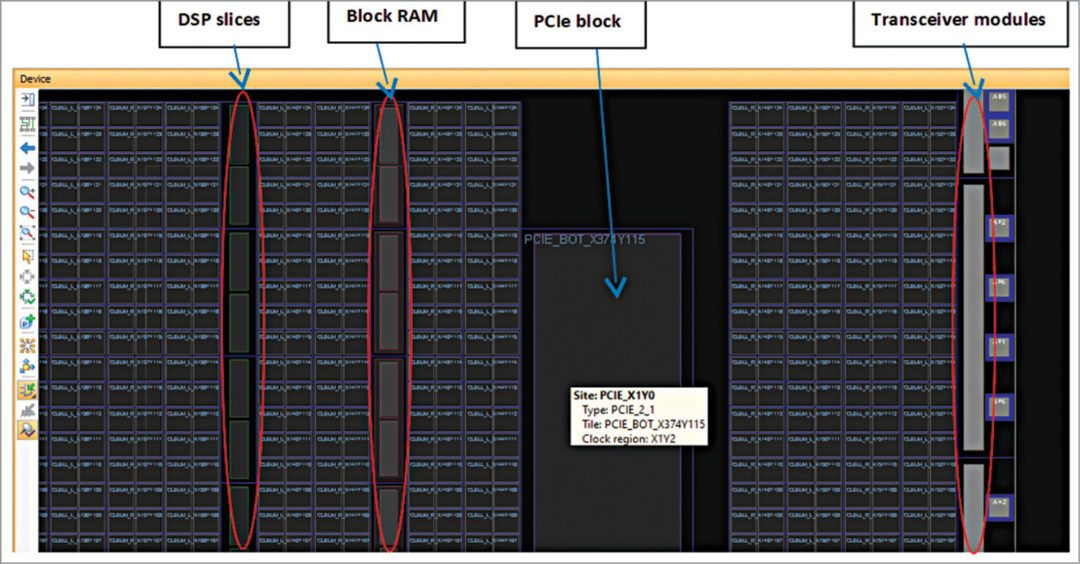
# 摘要
本文针对Virtex-5 FPGA RocketIO GTP Transceiver的性能优化进行了全面的探讨。首先介绍了GTP Transceiver的基本概念和性能优化的基础理论,包括信号完整性、时序约束分析以及功耗与热管理。然后,重点分析了硬件设计优化实践,涵盖了原理图设计、PCB布局布线策略以及预加重与接收端均衡的调整。在固件开发方面,文章讨论了GTP初始化与配置优化、串行协议栈性能调优及专用IP核的
【LBM方柱绕流模拟中的热流问题】:理论研究与实践应用全解析

# 摘要
本文全面探讨了Lattice Boltzmann Method(LBM)在模拟方柱绕流问题中的应用,特别是在热流耦合现象的分析和处理。从理论基础和数值方法的介绍开始,深入到流场与温度场相互作用的分析,以及热边界层形成与发展的研究。通过实践应用章节,本文展示了如何选择和配置模拟软
MBIM协议版本更新追踪:最新发展动态与实施策略解析

# 摘要
随着移动通信技术的迅速发展,MBIM(Mobile Broadband Interface Model)协议在无线通信领域扮演着越来越重要的角色。本文首先概述了MBIM协议的基本概念和历史背景,随后深入解析了不同版本的更新内容,包括新增功能介绍、核心技术的演进以及技术创新点。通过案例研究,本文探讨了MB
海泰克系统故障处理快速指南:3步恢复业务连续性
# 摘要
本文详细介绍了海泰克系统的基本概念、故障影响,以及故障诊断、分析和恢复策略。首先,概述了系统的重要性和潜在故障可能带来的影响。接着,详细阐述了在系统出现故障时的监控、初步响应、故障定位和紧急应对措施。文章进一步深入探讨了系统
从零开始精通DICOM:架构、消息和对象全面解析
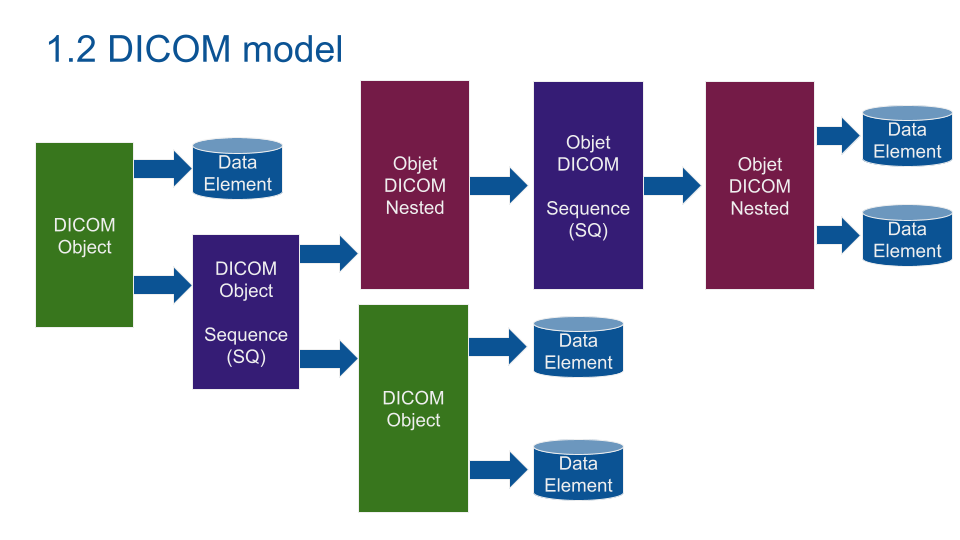
# 摘要
DICOM(数字成像和通信医学)标准是医疗影像设备和信息系统中不可或缺的一部分,本文从DICOM标准的基础知识讲起,深入分析了其架构和网络通信机制,消息交换过程以及安全性。接着,探讨了DICOM数据对象和信息模型,包括数据对象的结构、信息对象的定义以及映射资源的作用。进一步,本文分析了DICOM在医学影像处理中的应用,特别是医学影像设备的DICOM集成、医疗信息系统中的角色以及数据管理与后处理的
配置管理数据库(CMDB):最佳实践案例与深度分析

# 摘要
本文系统地探讨了配置管理数据库(CMDB)的概念、架构设计、系统实现、自动化流程管理以及高级功能优化。首先解析了CMDB的基本概念和架构,并对其数据模型、数据集成策略以及用户界面进行了详细设计说明。随后,文章深入分析了CMDB自
【DisplayPort over USB-C优势大揭秘】:为何技术专家力荐?

# 摘要
DisplayPort over USB-C作为一种新兴的显示技术,将DisplayPort视频信号通过USB-C接口传输,提供了更高带宽和多功能集成的可能性。本文首先概述了DisplayPort over USB-C技术的基础知识,包括标准的起源和发展、技术原理以及优势分析。随后,探讨了在移动设备连接、商
RAID级别深度解析:IBM x3650服务器数据保护的最佳选择

# 摘要
本文全面探讨了RAID技术的原理与应用,从基本的RAID级别概念到高级配置及数据恢复策略进行了深入分析。文中详细解释了RAID 0至RAID 6的条带化、镜像、奇偶校验等关键技术,探讨了IBM x3650服务器中RAID配置的实际操作,并分析了不同RAID级别在数据保护、性能和成本上的权衡。此外,本文还讨论了RAID技术面临的挑战,包括传统技术的局限性和新兴技术趋势,预测了RAID在硬件加速和软件定义存储领域的发展方向。通过对RAID技术的深入
【jffs2数据一致性维护】

# 摘要
本文全面探讨了jffs2文件系统及其数据一致性的理论与实践操作。首先,概述了jffs2文件系统的基本概念,并分析了数据一致性的基础理论,包括数据一致性的定义、重要性和维护机制。接着,详细描述了jffs2文件系统的结构以及一致性算法的核心组件,如检测和修复机制,以及日志结构和重放策略。在实践操作部分,文章讨论了如何配置和管理jffs2文件系统,以及检查和维护
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )