【图论与搜索策略】:Hackerrank DFS和BFS问题精通指南
发布时间: 2024-09-24 04:00:37 阅读量: 87 订阅数: 34 
# 1. 图论基础与搜索算法概述
## 1.1 图论的基本概念
图论是数学的一个分支,主要研究的是图的性质,以及与图相关的算法。图由节点(顶点)和连接这些节点的边组成。有向图中的边有方向,而无向图中的边则没有。图可以用来表示各种实际问题中的关系和网络,例如社交网络、互联网、电路和交通网络等。
## 1.2 图的分类
根据图的特性可以将其分为多种类型:
- 简单图:没有重边和自环的图
- 加权图:边具有权重,表示连接顶点之间的成本或距离
- 完全图:图中任意两个不同顶点之间都存在一条边
- 二分图:图的顶点可以划分为两个互不相交的集合,任何一条边的两个端点都分别属于这两个集合
## 1.3 搜索算法的类型与作用
搜索算法用于在图中找到从起始点到目标点的路径。常见的搜索算法包括深度优先搜索(DFS)和广度优先搜索(BFS)。DFS通过递归深入每一条可能的分支,而BFS则逐层展开搜索,直到找到目标。
- **深度优先搜索(DFS)**:适用于路径查找和拓扑排序等应用。它通过递归的方式,优先探索图的深度。
- **广度优先搜索(BFS)**:常用于最短路径问题。它使用队列结构,从起始点开始,逐层访问所有邻接点。
这两种搜索算法在解决实际问题时,如导航、网络爬虫、游戏设计等领域中扮演了重要角色。在后续章节中,我们将深入探讨它们的原理、优化和应用场景。
# 2. 深度优先搜索(DFS)详解
### 2.1 DFS理论基础
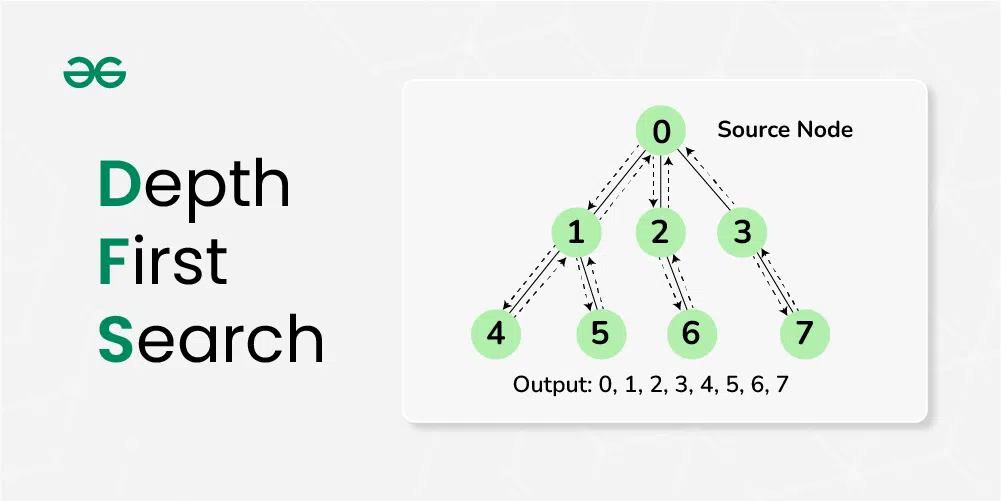
深度优先搜索(DFS)是一种用于遍历或搜索树或图的算法。在图的遍历中,DFS会尽可能深地搜索图的分支,当节点v的所有边都已被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。深度优先搜索利用栈数据结构来实现。
#### 2.1.1 图的遍历与搜索算法概述
在图论中,图可以分为有向图和无向图两种。对于图的遍历,主要有两种基本算法:深度优先搜索(DFS)和广度优先搜索(BFS)。这两种算法有着不同的应用场景和特点。DFS在需要搜索尽可能深的路径时非常有效,而BFS则更适合寻找最短路径。
在DFS中,探索尽可能远的分支,并且在回溯之前不探索邻近分支,可以看作是一种“深挖”策略。而BFS则从源点开始,逐层向外扩展,像是“广撒网”。在实现DFS时,可以使用递归或显式栈数据结构来追踪路径。
#### 2.1.2 DFS的原理与递归实现
DFS可以使用递归或非递归(迭代)的方式实现。递归实现更直观,但可能会受到递归深度限制。以下是DFS的递归实现伪代码:
```pseudo
DFS(node):
if node is visited:
return
mark node as visited
perform action on node
for each neighbor of node:
DFS(neighbor)
```
在实际代码实现中,通常需要一个额外的数据结构(如数组或字典)来标记每个节点是否已经被访问过,以避免无限循环和重复访问。
### 2.2 DFS在Hackerrank中的应用
#### 2.2.1 常见DFS问题解析
在Hackerrank等编程竞赛平台上,DFS常常用于解决需要遍历或搜索的问题。例如,在解决迷宫问题时,我们需要从起点开始,使用DFS寻找到达终点的路径。常见的DFS问题还包括图的连通性判断、求解图中环或路径等问题。
#### 2.2.2 DFS优化技巧和代码实践
DFS的优化主要集中在减少不必要的搜索和加快搜索速度上。一种常见的方式是使用剪枝技术,即在搜索过程中发现某些条件下可以提前结束该分支的搜索。
下面是一个简单的DFS代码示例,展示了如何在Python中实现DFS并进行剪枝优化:
```python
def DFS(graph, node, visited):
if node is the solution:
process_solution()
return
visited.add(node)
for neighbour in graph[node]:
if neighbour not in visited:
DFS(graph, neighbour, visited)
# 初始化图和搜索节点
graph = build_graph()
start_node = get_start_node()
visited = set()
DFS(graph, start_node, visited)
```
### 2.3 DFS的高级应用
#### 2.3.1 DFS变种:双向搜索与迭代加深搜索
双向搜索是从源点和目标点同时进行深度优先搜索,直到两者相遇,这种方法在解决某些问题时可以有效减少搜索空间。迭代加深搜索是深度优先搜索的另一种变体,它通过限制搜索深度来避免陷入过深的路径,然后逐步增加深度限制,直到找到解。
#### 2.3.2 DFS与图着色、拓扑排序等经典问题
DFS与图着色问题结合时,可以用于检测图中是否存在环。如果在DFS的递归过程中,发现一个已访问过的节点,说明存在环。对于有向无环图(DAG),DFS可以用来进行拓扑排序,即将图中的所有节点线性排序,使得对于图中的每一条有向边(u, v),节点u都在节点v之前。
在实际应用中,DFS不仅是一种强大的搜索工具,它还帮助开发者更好地理解图的结构和性质,从而在各种复杂的图论问题中找到解法。在下一章中,我们将探讨广度优先搜索(BFS),这是一种与DFS有着不同特性和应用场景的搜索策略。
# 3. 广度优先搜索(BFS)详解
## 3.1 BFS理论基础
### 3.1.1 BFS的基本原理与队列实现
广度优先搜索(BFS)是一种用于遍历或搜索树或图的算法。它的核心思想是从某一节点开始,先访问它的所有邻近节点,然后再对每个邻近节点逐层进行访问,直到所有的节点都被访问过。BFS使用队列数据结构来跟踪每一层待访问的节点,从而保证算法以广度优先的方式进行。
BFS的伪代码如下:
```
BFS(G, s) // G为图,s为起始节点
let Q be a queue
Q.enqueue(s)
while Q is not empty
v = Q.dequeue()
if v is the goal
return v
for all edges from v to w in G
if w is unmarked
mark w
Q.enqueue(w)
```
在队列实现中,我们通常使用两个标志位,一个用于标记节点是否已经被访问过,另一个用于标记节点是否在当前层。这有助于提高算法的效率,确保我们不会重复访问一个节点,并且可以在每一层遍历结束后正确地切换到下一层。
### 3.1.2 BFS在树和图中的应用差异
BFS在树和图中应用有一些本质的区别。在树中,由于其结构特性(无环且每个节点只有一个父节点),BFS可以直观地一层层遍历所有节点。而在图中,由于可能存在环,BFS的实现需要额外的标记机制来避免重复访问。
在树的遍历中,BFS能够轻易地按层级访问节点,从而得到节点的层序遍历结果。但在图中,BFS则主要用于找到从源点到其他所有可达节点的最短路径,或者判断两个节点是否是连通的。
### 表格:BFS在树和图中应用对比
| 特性 | 树 | 图 |
| --- | --- | --- |
| 数据结构 | 层序遍历 | 最短路径搜索 |
| 路径特点 | 单一路径 | 多条路径可能性 |
| 访问顺序 | 按层访问 | 按访问顺序访问 |
| 避免重复访问 | 可通过访问标记实现 | 需要额外的标记机制(如使用HashSet记录访问过的节点) |
## 3.2 BFS在Hackerrank中的应用
### 3.2.1 常见BFS问题解

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Hacker Rank》专栏是一个全面的资源库,涵盖了解决 Hacker Rank 编程挑战所需的核心数据结构、算法和技术。它提供深入的教程,涵盖了栈、队列、链表、动态规划、图论、字符串处理、数学、排序算法、SQL 查询优化、递归、二分搜索、数组和矩阵操作、模拟算法、数据结构性能、高阶函数、链表反转、时间和空间复杂度分析、贪心算法和回溯算法。通过这些文章,读者可以掌握解决 Hacker Rank 难题所需的技能,并提高他们的编程能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python讯飞星火LLM问题解决】:1小时快速排查与解决常见问题
# 1. Python讯飞星火LLM简介
Python讯飞星火LLM是基于讯飞AI平台的开源自然语言处理工具库,它将复杂的语言模型抽象化,通过简单易用的API向开发者提供强大的语言理解能力。本章将从基础概览开始,帮助读者了解Python讯飞星火LLM的核心特性和使用场景。
## 星火LLM的核心特性
讯飞星火LLM利用深度学习技术,尤其是大规模预训练语言模型(LLM),提供包括但不限于文本分类、命名实体识别、情感分析等自然语言处理功能。开发者可以通过简单的函数调用,无需复杂的算法知识,即可集成高级的语言理解功能至应用中。
## 使用场景
该工具库广泛适用于各种场景,如智能客服、内容审
【MATLAB在Pixhawk定位系统中的应用】:从GPS数据到精确定位的高级分析

# 1. Pixhawk定位系统概览
Pixhawk作为一款广泛应用于无人机及无人车辆的开源飞控系统,它在提供稳定飞行控制的同时,也支持一系列高精度的定位服务。本章节首先简要介绍Pixhawk的基本架构和功能,然后着重讲解其定位系统的组成,包括GPS模块、惯性测量单元(IMU)、磁力计、以及_barometer_等传感器如何协同工作,实现对飞行器位置的精确测量。
我们还将概述定位技术的发展历程,包括
【大数据处理利器】:MySQL分区表使用技巧与实践
# 1. MySQL分区表概述与优势
## 1.1 MySQL分区表简介
MySQL分区表是一种优化存储和管理大型数据集的技术,它允许将表的不同行存储在不同的物理分区中。这不仅可以提高查询性能,还能更有效地管理数据和提升数据库维护的便捷性。
## 1.2 分区表的主要优势
分区表的优势主要体现在以下几个方面:
- **查询性能提升**:通过分区,可以减少查询时需要扫描的数据量
SSM论坛系统部署监控:全方位策略与技巧

# 1. SSM论坛系统概述与监控需求
## 1.1 SSM论坛系统概述
SSM论坛系统是基于Spring、SpringMVC和MyBatis三个框架整合构建的Java Web应用程序。它提供了一个网络平台,用户可以在这里进行交流和分享。SSM论坛系统具有用户管理、帖子发布、评论互动等基本的社区功能。系统的设计注重松耦合和高可用性,便于后续的维护和升级。
## 1.2 系统
【数据集不平衡处理法】:解决YOLO抽烟数据集类别不均衡问题的有效方法

# 1. 数据集不平衡现象及其影响
在机器学习中,数据集的平衡性是影响模型性能的关键因素之一。不平衡数据集指的是在分类问题中,不同类别的样本数量差异显著,这会导致分类器对多数类的偏好,从而忽视少数类。
## 数据集不平衡的影响
不平衡现象会使得模型在评估指标上产生偏差,如准确率可能很高,但实际上模型并未有效识别少数类样本。这种偏差对许多应
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
面向对象编程与函数式编程:探索编程范式的融合之道

# 1. 面向对象编程与函数式编程概念解析
## 1.1 面向对象编程(OOP)基础
面向对象编程是一种编程范式,它使用对象(对象是类的实例)来设计软件应用。
【用户体验设计】:创建易于理解的Java API文档指南
# 1. Java API文档的重要性与作用
## 1.1 API文档的定义及其在开发中的角色
Java API文档是软件开发生命周期中的核心部分,它详细记录了类库、接口、方法、属性等元素的用途、行为和使用方式。文档作为开发者之间的“沟通桥梁”,确保了代码的可维护性和可重用性。
## 1.2 文档对于提高代码质量的重要性
良好的文档
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
绿色计算与节能技术:计算机组成原理中的能耗管理
# 1. 绿色计算与节能技术概述
随着全球气候变化和能源危机的日益严峻,绿色计算作为一种旨在减少计算设备和系统对环境影响的技术,已经成为IT行业的研究热点。绿色计算关注的是优化计算系统的能源使用效率,降低碳足迹,同时也涉及减少资源消耗和有害物质的排放。它不仅仅关注硬件的能耗管理,也包括软件优化、系统设计等多个方面。本章将对绿色计算与节能技术的基本概念、目标及重要性进行概述
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )