揭秘OpenVINO YOLO单图像推理:模型部署与调优秘籍
发布时间: 2024-08-18 05:01:38 阅读量: 43 订阅数: 39 

ysoserial-master.zip
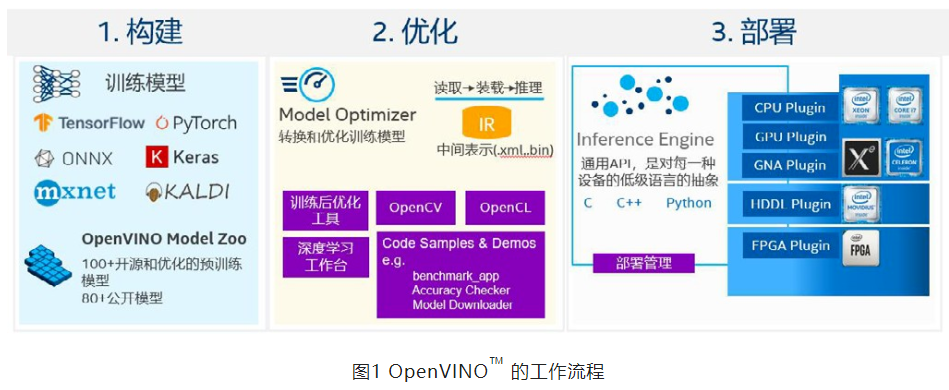
# 1. OpenVINO简介**
OpenVINO™ 工具套件是一个开源的计算机视觉、机器学习和深度学习推理框架,用于加速各种平台上的深度学习模型的部署和推理。它由英特尔开发,旨在优化模型性能,同时提供跨不同硬件架构的可移植性。
OpenVINO™ 工具套件包含一系列组件,包括:
* **Model Optimizer:**将深度学习模型转换为 OpenVINO™ IR(中间表示)格式,以便在各种硬件平台上进行优化推理。
* **Inference Engine:**一个 C++ 库,提供用于在 CPU、GPU 和 VPU(视觉处理单元)等不同硬件平台上执行模型推理的 API。
* **OpenVINO™ 开发工具包:**一组用于开发和部署 OpenVINO™ 应用程序的工具,包括 Python API、示例和教程。
# 2. YOLO模型部署**
**2.1 模型转换和优化**
**2.1.1 Model Optimizer工具介绍**
Model Optimizer是OpenVINO工具包中用于将预训练模型转换为OpenVINO IR格式的工具。它支持各种深度学习框架,包括TensorFlow、Caffe和PyTorch。Model Optimizer通过以下步骤转换模型:
- **冻结图(Freeze Graph)**:将训练模型中的所有变量转换为常量,使其不再依赖于训练数据。
- **图优化(Graph Optimization)**:应用各种优化技术,例如常量折叠、子图合并和冗余消除,以减小模型大小和提高推理速度。
- **IR生成(IR Generation)**:将优化后的模型转换为OpenVINO IR格式,该格式由Inference Engine用于推理。
**2.1.2 模型转换参数详解**
Model Optimizer提供了一系列参数来控制转换过程,包括:
| 参数 | 描述 |
|---|---|
| `--input` | 输入节点名称 |
| `--output` | 输出节点名称 |
| `--data_type` | 模型数据类型(FP32、FP16、INT8) |
| `--layout` | 模型布局(NCHW、NHWC) |
| `--model_name` | 输出IR模型的名称 |
| `--scale` | 输入图像的预处理比例 |
| `--mean_values` | 输入图像的预处理均值 |
**2.2 模型推理引擎集成**
**2.2.1 Inference Engine API介绍**
Inference Engine是OpenVINO工具包中的推理引擎,用于执行模型推理。它提供了一个跨平台的API,允许开发者在各种设备(CPU、GPU、VPU)上部署和运行模型。
Inference Engine API主要包括以下功能:
- **模型加载和编译**:加载IR模型并将其编译为设备特定的可执行代码。
- **输入数据预处理**:将输入数据预处理为模型所需的格式。
- **模型推理**:执行模型推理并生成预测结果。
- **输出数据后处理**:将预测结果后处理为最终输出。
**2.2.2 模型推理流程分析**
模型推理流程通常包括以下步骤:
1. **模型加载**:使用Inference Engine加载IR模型。
2. **输入预处理**:将输入数据预处理为模型所需的格式,包括调整大小、归一化和转换布局。
3. **模型推理**:使用Inference Engine执行模型推理,生成预测结果。
4. **输出后处理**:将预测结果后处理为最终输出,例如应用非极大值抑制(NMS)以过滤冗余检测。
**代码示例:**
```python
import openvino.inference_engine as ie
# 加载模型
model = ie.IECore().read_network("model.xml", "model.bin")
# 输入预处理
input_blob = model.inputs["input"]
input_data = preprocess_input(input_blob)
# 模型推理
exec_net = ie.IECore().load_network(model, "CPU")
result = exec_net.infer(inputs={input_blob: input_data})
# 输出后处理
output_blob = model.outputs["output"]
output_data = postprocess_output(result[output_blob])
`
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以“OpenVINO YOLO单张图像推理”为主题,深入浅出地讲解了如何利用OpenVINO工具包和YOLO算法进行图像识别。从基础概念到实战指南,专栏涵盖了模型部署、性能优化、图像预处理、后处理、嵌入式设备部署、性能分析、瓶颈优化、与其他框架的对比、多模型推理、自定义模型训练、与其他计算机视觉任务集成,以及在工业、医疗、零售、教育、自动驾驶等领域的应用案例。通过循序渐进的讲解和丰富的实践经验,本专栏旨在帮助读者掌握OpenVINO YOLO单张图像推理的精髓,解锁图像识别的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
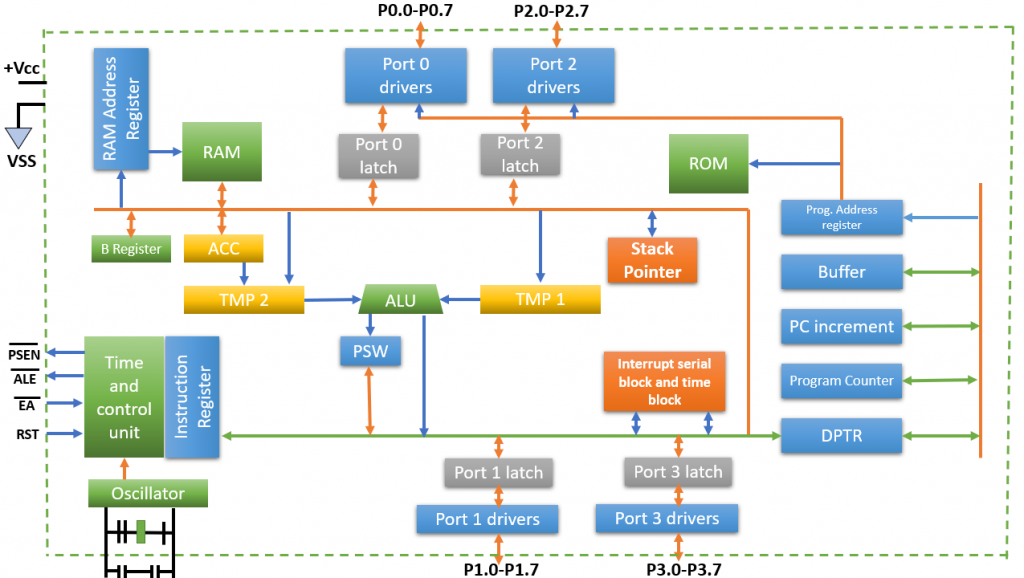
【51单片机数字时钟案例分析】:深入理解中断管理与时间更新机制
# 摘要
本文详细探讨了基于51单片机的数字时钟设计与实现。首先介绍了数字时钟的基本概念、功能以及51单片机的技术背景和应用领域。接着,深入分析了中断管理机制,包括中断系统原理、51单片机中断系统详解以及中断管理在实际应用中的实践。本文还探讨了时间更新机制的实现,阐述了基础概念、在51单片机下的具体策略以及优化实践。在数字时钟编程与调试章节中,讨论了软件设计、关键功能实现以及调试
【版本升级无忧】:宝元LNC软件平滑升级关键步骤大公开!

# 摘要
宝元LNC软件的平滑升级是确保服务连续性与高效性的关键过程,涉及对升级需求的全面分析、环境与依赖的严格检查,以及升级风险的仔细评估。本文对宝元LNC软件的升级实践进行了系统性概述,并深入探讨了软件升级的理论基础,包括升级策略
【异步处理在微信小程序支付回调中的应用】:C#技术深度剖析

# 摘要
本文首先概述了异步处理与微信小程序支付回调的基本概念,随后深入探讨了C#中异步编程的基础知识,包括其概念、关键技术以及错误处理方法。文章接着详细分析了微信小程序支付回调的机制,阐述了其安全性和数据交互细节,并讨论了异步处理在提升支付系统性能方面的必要性。重点介绍了如何在C#中实现微信支付的异步回调,包括服务构建、性能优化、异常处理和日志记录的最佳实践。最后,通过案例研究,本文分析了构建异步支付回调系统的架构设计、优化策略和未来挑战,为开
内存泄漏不再怕:手把手教你从新手到专家的内存管理技巧

# 摘要
内存泄漏是影响程序性能和稳定性的关键因素,本文旨在深入探讨内存泄漏的原理及影响,并提供检测、诊断和防御策略。首先介绍内存泄漏的基本概念、类型及其对程序性能和稳定性的影响。随后,文章详细探讨了检测内存泄漏的工具和方法,并通过案例展示了诊断过程。在防御策略方面,本文强调编写内存安全的代码,使用智能指针和内存池等技术,以及探讨了优化内存管理策略,包括内存分配和释放的优化以及内存压缩技术的应用。本文不
反激开关电源的挑战与解决方案:RCD吸收电路的重要性
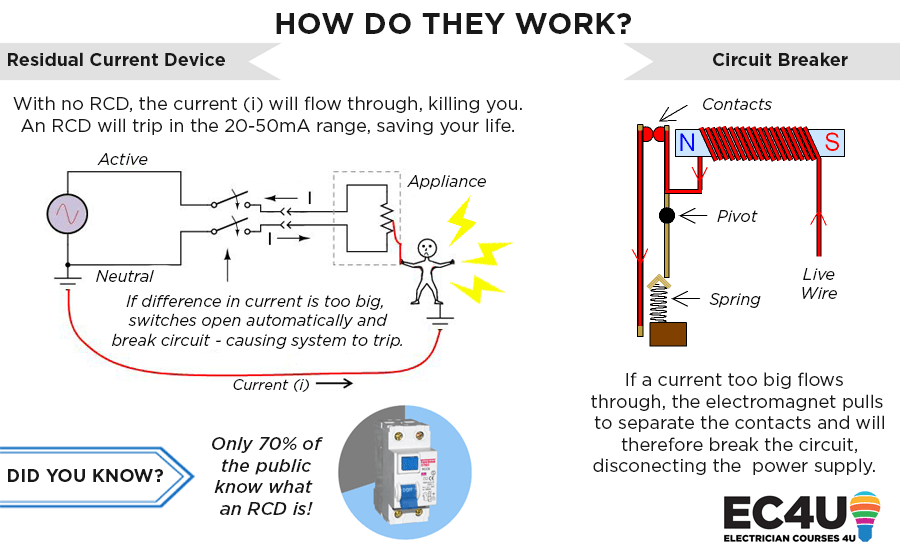
# 摘要
本文系统探讨了反激开关电源的工作原理及RCD吸收电路的重要作用和优势。通过分析RCD吸收电路的理论基础、设计要点和性能测试,深入理解其在电压尖峰抑制、效率优化以及电磁兼容性提升方面的作用。文中还对RCD吸收电路的优化策略和创新设计进行了详细讨论,并通过案例研究展示其在不同应用中的有效性和成效。最后,文章展望了RCD吸收电路在新材料应用
【Android设备标识指南】:掌握IMEI码的正确获取与隐私合规性

# 摘要
IMEI码作为Android设备的唯一标识符,不仅保证了设备的唯一性,还与设备的安全性和隐私保护密切相关。本文首先对IMEI码的概念及其重要性进行了概述,然后详细介绍了获取IMEI码的理论基础和技术原理,包括在不同Android版本下的实践指南和高级处理技巧。文中还讨论了IMEI码的隐私合规性考量和滥用防范策略,并通过案例分析展示了IMEI码在实际应用中的场景。最后,本文探讨了隐私保护技术的发展趋势以及对开发者在合规性
E5071C射频故障诊断大剖析:案例分析与排查流程(故障不再难)
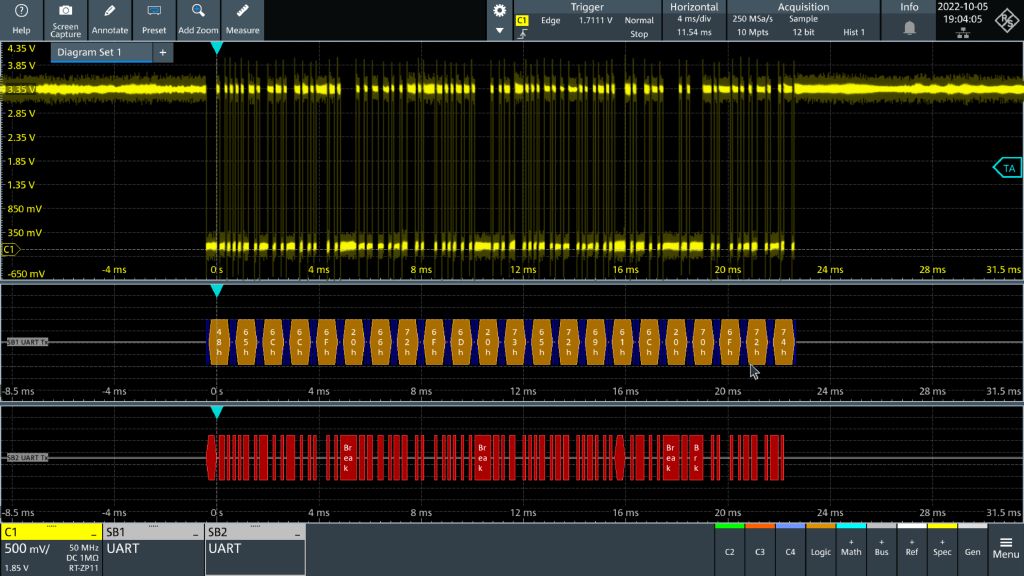
# 摘要
本文对E5071C射频故障诊断进行了全面的概述和深入的分析。首先介绍了射频技术的基础理论和故
【APK网络优化】:减少数据消耗,提升网络效率的专业建议

# 摘要
随着移动应用的普及,APK网络优化已成为提升用户体验的关键。本文综述了APK网络优化的基本概念,探讨了影响网络数据消耗的理论基础,包括数据传输机制、网络请求效率和数据压缩技术。通过实践技巧的讨论,如减少和合并网络请求、服务器端数据优化以及图片资源管理,进一步深入到高级优化策略,如数据同步、差异更新、延迟加载和智能路由选择。最后,通过案例分析展示了优化策略的实际效果,并对5G技
DirectExcel数据校验与清洗:最佳实践快速入门
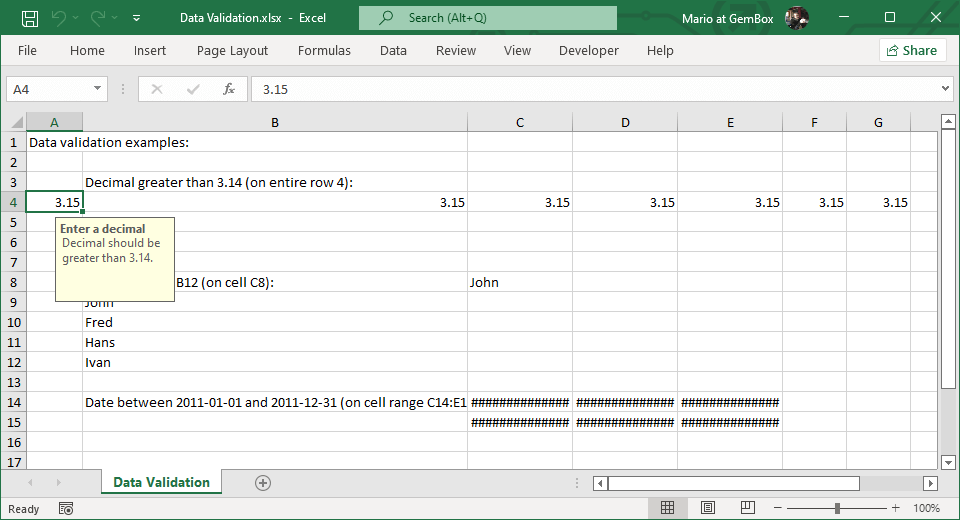
# 摘要
本文旨在介绍DirectExcel在数据校验与清洗中的应用,以及如何高效地进行数据质量管理。文章首先概述了数据校验与清洗的重要性,并分析了其在数据处理中的作用。随后,文章详细阐述了数据校验和清洗的理论基础、核心概念和方法,包括校验规则设计原则、数据校验技术与工具的选择与应用。在实践操作章节中,本文展示了DirectExcel的界面布局、功能模块以及如何创建
【模糊控制规则优化算法】:提升实时性能的关键技术
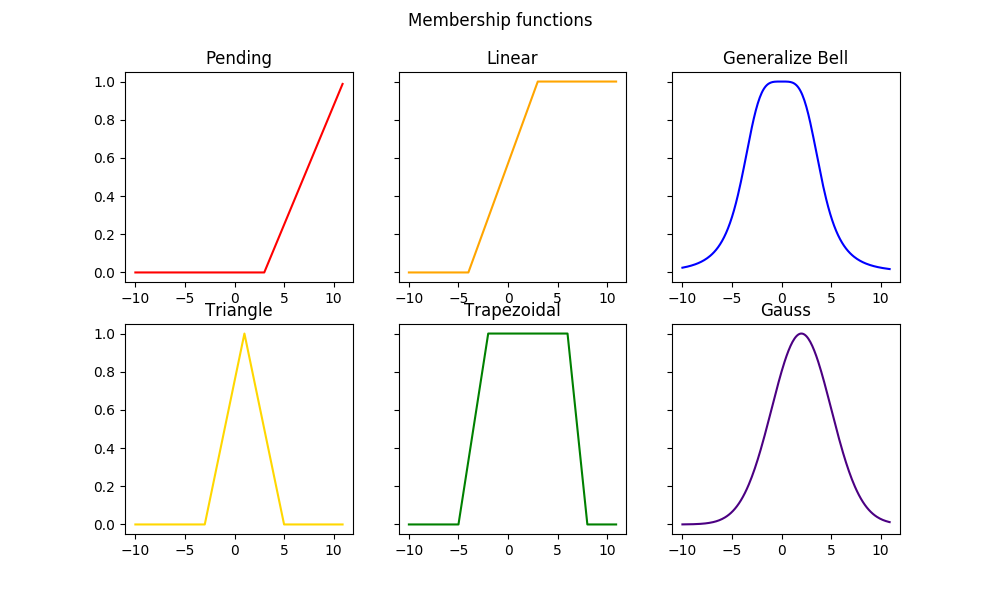
# 摘要
模糊控制规则优化算法是提升控制系统性能的重要研究方向,涵盖了理论基础、性能指标、优化方法、实时性能分析及提升策略和挑战与展望。本文首先对模糊控制及其理论基础进行了概述,随后详细介绍了基于不同算法对模糊控制规则进行优化的技术,包括自动优化方法和实时性能的改进策略。进一步,文章分析了优化对实时性能的影响,并探索了算法面临的挑战与未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )