Apache Hudi简介及基本概念解析
发布时间: 2024-02-21 12:48:55 阅读量: 12 订阅数: 15 
# 1. 引言
## Apache Hudi介绍
Apache Hudi是一种开源数据湖开放表的构建和管理系统,支持数据湖上的增量存储、变更数据管理和查询。它提供了一个用于存储大规模数据并允许先进的数据操作管理,例如记录级更新、插入和删除操作的解决方案。
## 文章目的
本文旨在介绍Apache Hudi的基本概念、核心组件、使用方法及部署技巧,以帮助读者更好地理解和应用Apache Hudi在实际项目中的场景。
## 阅读指南
在本文中,我们将首先了解Apache Hudi的概况,包括其定义、特点以及应用场景。然后,我们将深入解析Apache Hudi的基本概念,比如数据湖与数据湖层存储、Hudi表的结构与特点,以及Hudi的写入与更新流程。接着,我们将介绍Apache Hudi的核心组件,包括Write Client、读取器和元数据存储。最后,我们将讨论如何在项目中使用Apache Hudi、集群部署与配置、性能优化等内容。最后,我们将总结Apache Hudi的优势和不足,探讨其未来的发展方向。
# 2. Apache Hudi概览
Apache Hudi 是一个开源的数据湖工具,旨在简化大数据仓库的更新与增量处理。它采用了一种新颖的数据湖架构, 实现了 ACID 事务、增量数据处理、时态数据查询等功能, 在数据湖层存储方面具有独特优势。
### 什么是Apache Hudi
Apache Hudi 是来自 Apache 基金会的开源项目,全称为 Hadoop Upserts Deletes and Incrementals。它为构建大规模数据湖提供了一种高效的方法,支持增量数据流式处理、数据变更的更新操作。
### Apache Hudi的特点
- 支持大规模数据的增量变更与流式处理,适用于实时数据处理场景。
- 提供了 ACID 事务保证,确保数据的一致性和可靠性。
- 支持时态查询,可以查询历史数据或特定时间点的数据快照。
- 具有高效的数据压缩和索引机制,提高了数据存储和查询性能。
- 易于集成到现有的数据处理框架中,如 Apache Spark、Apache Flink 等。
### Apache Hudi的应用场景
- 金融行业:用于实时交易数据处理与分析。
- 物联网领域:处理海量设备数据的采集与分析。
- 零售行业:用于存储商品销售数据并进行实时更新。
Apache Hudi 的特性和灵活性使其成为处理大规模数据湖的理想选择,帮助用户更好地管理和分析海量数据。
# 3. Apache Hudi基本概念解析
Apache Hudi是一个开源的数据湖管理框架,主要用于流式数据的处理和分析。在本节中,我们将解析Apache Hudi的一些基本概念,包括数据湖与数据湖层存储、Hudi表的结构与特点以及Hudi的写入与更新流程。让我们深入了解Apache Hudi的核心概念。
#### 数据湖与数据湖层存储
数据湖是一种存储大量结构化和非结构化数据的架构,用于支持数据分析和机器学习任务。数据湖层存储是数据湖中的数据存储层,用于管理和存储数据湖中的各种数据。Apache Hudi作为数据湖层存储的一种解决方案,提供了对数据的实时写入、更新和查询功能,同时保证数据的一致性和可靠性。
#### Hudi表(Hudi Table)的结构与特点
在Apache Hudi中,数据以Hudi表的形式进行组织和存储。Hudi表由三个主要部分组成:基础数据文件(Base Files)、变更数据文件(Delta Files)和元数据文件(Metadata File)。基础数据文件存储了原始数据的快照,而变更数据文件记录了数据的变更历史。通过管理这些文件,Hudi表实现了数据的写入、更新和查询操作。
Hudi表的特点包括:
- **幂等性写入**:支持幂等性写入,确保数据写入的原子性和一致性。
- **时间旅行查询**:能够按照时间维度查询数据的历史版本。
- **写入合并**:支持多个并发写入操作的数据合并,保证数据的完整性和一致性。
- **增量查询**:能够高效地处理增量数据加载和查询,提高数据处理的性能。
#### Hudi的写入与更新流程解析
Apache Hudi的写入与更新流程包括以下步骤:
1. **初始化Hudi表**:创建或加载现有的Hudi表,准备进行数据的写入操作。
2. **写入数据**:将数据写入Hudi表,生成新的Delta文件记录数据的变更。
3. **更新数据**:对Hudi表中的数据进行更新操作,生成新的Delta文件记录更新的变更。
4. **查询数据**:通过读取器(Reader)从Hudi表中查询数据,并实现时间旅行查询功能。
5. **元数据管理**:维护Hudi表的元数据,包括数据文件的管理和版本控制。
通过理解Apache Hudi的基本概念和写入流程,我们可以更好地使用和部署Apache Hudi进行数据湖管理和分析。接下来,让我们深入探讨Apache Hudi的核心组件和使用方法。
# 4. Apache Hudi的核心组件
Apache Hudi是一个强大的开源数据湖解决方案,其核心组件包括:
#### 1. Hudi的Write Client
Hudi的Write Client是用于将数据写入Hudi表的组件。通过Hudi的Write Client,用户可以实现数据的插入、更新和删除操作。Write Client提供了丰富的API,使得开发者可以方便地将数据写入Hudi表中。下面是一个简单的Java代码示例,演示了如何使用Hudi的Write Client将数据写入Hudi表中:
```java
// 创建Hudi Write Client
HoodieWriteConfig cfg = HoodieWriteConfig.newBuilder().build();
HoodieWriteClient client = new HoodieWriteClient(jsc, cfg);
// 创建要写入的数据集
List<HoodieRecord> records = generateHoodieRecords(); // 生成Hudi记录的方法
// 将数据写入Hudi表
JavaRDD<HoodieRecord> writeResult = client.upsert(JavaRDD.toRDD(records), instantTime);
```
#### 2. Hudi的读取器
Hudi的读取器用于从Hudi表中读取数据。Hudi提供了灵活的API和查询语言,使得用户可以方便地从Hudi表中读取数据,支持高效的数据查询和分析。下面是一个简单的Python示例,演示了如何使用Hudi的读取器从Hudi表中读取数据:
```python
# 创建Hudi读取器
hudiReadConfig = (HoodieReadClient.ConfigBuilder(env, basePath).build())
hudiReadClient = HoodieReadClient(hudiReadConfig)
# 从Hudi表中读取数据
query = "SELECT * FROM hudi_table WHERE id = 123"
result = hudiReadClient.query(query)
```
#### 3. Hudi的元数据存储
Hudi的元数据存储组件负责管理Hudi表的元数据信息,包括表的schema信息、数据文件的位置和版本信息等。元数据存储是Hudi的核心组件之一,它保证了Hudi表的一致性和可靠性。Hudi的元数据存储采用了先进的元数据管理技术,能够高效地管理Hudi表的元数据信息,确保Hudi表的可靠性和性能。
# 5. Apache Hudi的使用与部署
Apache Hudi是一个用于构建可插入、增量处理和查询的数据湖的开源库。在本章节中,我们将深入探讨如何在项目中使用Apache Hudi、它的集群部署与配置以及性能优化的相关内容。
### 如何在项目中使用Apache Hudi
要在项目中使用Apache Hudi,首先需要确保你已经有一个Hadoop集群或Spark集群的访问权限。接下来,你需要下载Apache Hudi的jar包,并将其添加到你的项目依赖中。
下面是一个简单的Java代码示例,演示了如何使用Apache Hudi创建一个Hudi表并进行数据写入:
```java
// 初始化Hudi表配置
HoodieWriteConfig config = HoodieWriteConfig.newBuilder()
.withPath("hdfs://path/to/hudi_table")
.withTableName("hudi_table_name")
.withTableType(ENCODING)
.build();
// 创建Hudi写入客户端
HoodieWriteClient client = new HoodieWriteClient(jsc, config);
// 准备写入数据
List<String> data = Arrays.asList("1,John,Doe", "2,Jane,Smith");
// 创建Hudi写入数据集
JavaRDD<String> recordsRDD = jsc.parallelize(data);
JavaRDD<HoodieRecord> hoodieRecords = recordsRDD.map(record -> {
String[] fields = record.split(",");
String key = fields[0];
String payload = record.substring(key.length() + 1);
return new HoodieRecord(new HoodieKey(key, ""), payload);
});
// 将数据写入Hudi表
JavaRDD<WriteStatus> writeStatuses = client.upsert(hoodieRecords, commitTime);
// 打印写入结果
writeStatuses.foreach(status -> System.out.println("WriteStatus: " + status));
```
### Apache Hudi的集群部署与配置
为了在集群中部署和配置Apache Hudi,你需要确保Hadoop或Spark集群的正确设置,并且所有节点都能够访问Hudi所需的依赖和资源。你可以通过编辑Hudi的配置文件来指定不同的参数,以满足不同的需求。同时,还可以通过启动不同的服务如HUDI Timeline Server来对Hudi进行监控和管理。
### Apache Hudi的性能优化
想要优化Apache Hudi的性能,一些常见的方法包括优化底层存储(如使用Parquet格式)、调整配置参数(如调整写入批量大小)以及合理使用索引等。此外,也可以考虑使用Apache Hudi提供的工具来分析和优化查询性能。
通过合理地使用Apache Hudi,并结合性能优化策略,可以更高效地构建和管理数据湖,提高数据处理和查询的性能与可靠性。
# 6. 结论及展望
Apache Hudi作为一个开源的数据湖解决方案,在大数据领域有着广泛的应用。通过本文的介绍,我们对Apache Hudi有了更深入的了解,接下来我们将对其进行总结并展望未来的发展。
### Apache Hudi的优势和不足
#### 优势:
1. **增量数据处理**:Apache Hudi支持增量数据写入和更新,可以有效提高数据处理效率。
2. **查询性能**:Hudi通过列式存储和索引优化,能够快速查询大规模数据。
3. **数据湖管理**:Hudi提供了完整的数据湖管理功能,方便用户管理和查询数据湖中的数据。
4. **容错性**:Hudi具有良好的容错性,能够确保数据的完整性和一致性。
#### 不足:
1. **学习成本**:由于Hudi具有一定的复杂性,初学者可能需要一定时间来适应和学习。
2. **性能调优**:在处理大规模数据时,需要进行性能调优,以保证系统的稳定性和效率。
### 未来Apache Hudi的发展方向
未来,Apache Hudi将会朝着以下方向进行发展:
1. **性能优化**:继续优化数据处理性能,提高查询效率和写入性能。
2. **生态建设**:扩大Hudi的生态系统,与更多的大数据组件(如Spark、Flink等)进行集成。
3. **易用性改进**:简化Hudi的配置和部署流程,降低用户的学习成本。
### 结语
Apache Hudi作为一个开源的数据湖解决方案,为大数据领域的数据管理提供了一种全新的思路。通过不断地优化和改进,相信Apache Hudi在未来会有更广阔的应用前景。让我们共同期待Apache Hudi在大数据领域的进一步发展!
0
0
相关推荐

专栏简介
《Apache Hudi数据湖》专栏深度探讨了在当今大数据时代中,如何利用Apache Hudi构建高效、灵活的数据湖架构及各种关键技术应用。首先,通过《Apache Hudi简介及基本概念解析》一文,带领读者了解Apache Hudi的基本概念和特点;随后,结合《Apache Hudi数据湖架构深度解析》,探索数据湖的架构设计和实现原理。然后从实践出发,《Apache Hudi实时数据湖的设计与实现》详细介绍了实时数据湖的构建和操作。此外,对于数据处理和管理,《利用Apache Hudi实现数据湖中的增量数据处理》、《Apache Hudi数据湖与数据质量管理》、《Apache Hudi数据湖中的数据索引优化》等文章提供了深入指导。专栏还关注了数据安全、权限管理和性能优化等重要议题,《Apache Hudi中的数据湖权限管理与数据安全》、《Apache Hudi数据湖中的数据负载均衡与性能优化》等文章系统地探讨了相关技术。最后,结合实际应用,《在Apache Hudi数据湖中使用Apache Hive进行数据查询与分析》、《利用Apache Hudi进行实时流式数据湖的搭建与实现》揭示了数据湖的实际应用场景和解决方案。通过专栏,读者不仅可以深入理解Apache Hudi的理论知识,还能获得丰富实践经验,掌握数据湖的核心技术和应用。
最低0.47元/天 解锁专栏
VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB符号数组:解析符号表达式,探索数学计算新维度

# 1. MATLAB 符号数组简介**
MATLAB 符号数组是一种强大的工具,用于处理符号表达式和执行符号计算。符号数组中的元素可以是符
深入了解MATLAB开根号的最新研究和应用:获取开根号领域的最新动态

# 1. MATLAB开根号的理论基础
开根号运算在数学和科学计算中无处不在。在MATLAB中,开根号可以通过多种函数实现,包括`sqrt()`和`nthroot()`。`sqrt()`函数用于计算正实数的平方根,而`nt
MATLAB在图像处理中的应用:图像增强、目标检测和人脸识别
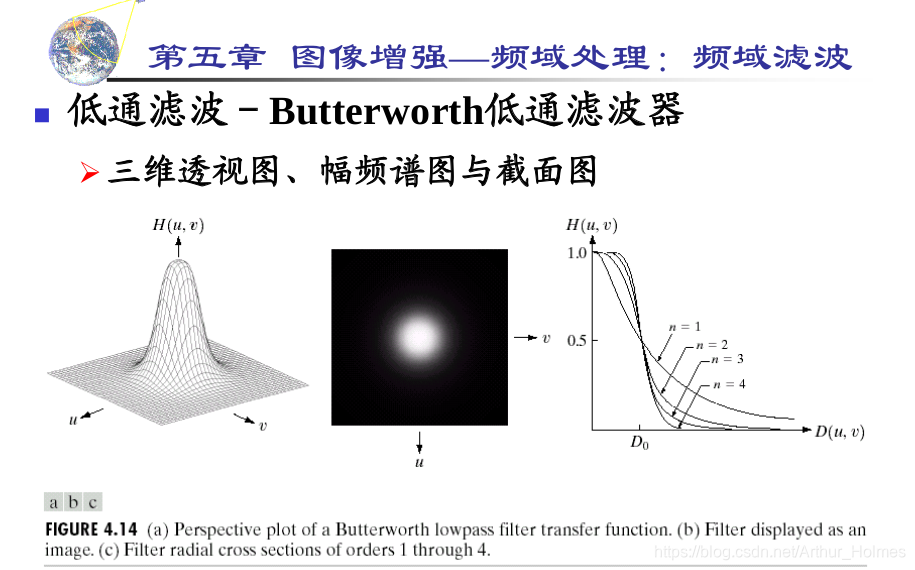
# 1. MATLAB图像处理概述
MATLAB是一个强大的技术计算平台,广泛应用于图像处理领域。它提供了一系列内置函数和工具箱,使工程师
MATLAB字符串拼接与财务建模:在财务建模中使用字符串拼接,提升分析效率

# 1. MATLAB 字符串拼接基础**
字符串拼接是 MATLAB 中一项基本操作,用于将多个字符串连接成一个字符串。它在财务建模中有着广泛的应用,例如财务数据的拼接、财务公式的表示以及财务建模的自动化。
MATLAB 中有几种字符串拼接方法,包括 `+` 运算符、`strcat` 函数和 `sprintf` 函数。`+` 运算符是最简单的拼接
NoSQL数据库实战:MongoDB、Redis、Cassandra深入剖析
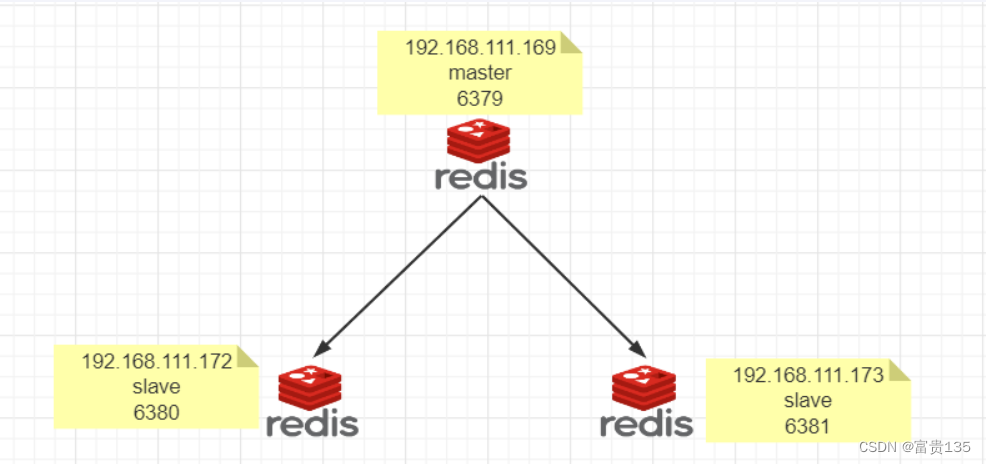
# 1. NoSQL数据库概述
**1.1 NoSQL数据库的定义**
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它不遵循传统的SQL(结构化查询语言)范式。NoSQL数据库旨在处理大规模、非结构化或半结构化数据,并提供高可用性、可扩展性和灵活性。
**1.2 NoSQL数据库的类型**
NoSQL数据库根据其数据模型和存储方式分为以下
MATLAB散点图:使用散点图进行信号处理的5个步骤
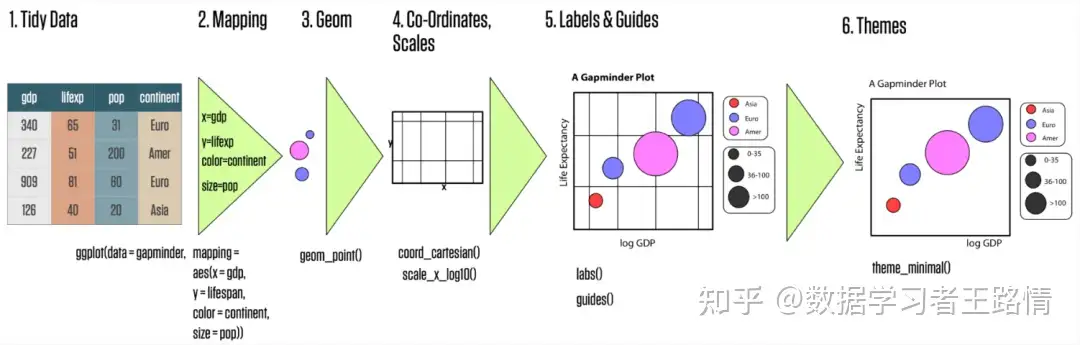
# 1. MATLAB散点图简介
散点图是一种用于可视化两个变量之间关系的图表。它由一系列数据点组成,每个数据点代表一个数据对(x,y)。散点图可以揭示数据中的模式和趋势,并帮助研究人员和分析师理解变量之间的关系。
在MATLAB中,可以使用`scatter`函数绘制散点图。`scatter`函数接受两个向量作为输入:x向量和y向量。这些向量必须具有相同长度,并且每个元素对(x,y)表示一个数据点。例如,以下代码绘制
MATLAB求平均值在社会科学研究中的作用:理解平均值在社会科学数据分析中的意义

# 1. 平均值在社会科学中的作用
平均值是社会科学研究中广泛使用的一种统计指标,它可以提供数据集的中心趋势信息。在社会科学中,平均值通常用于描述人口特
MATLAB柱状图在信号处理中的应用:可视化信号特征和频谱分析

# 1. MATLAB柱状图概述**
MATLAB柱状图是一种图形化工具,用于可视化数据中不同类别或组的分布情况。它通过绘制垂直条形来表示每个类别或组中的数据值。柱状图在信号处理中广泛用于可视化信号特征和进行频谱分析。
柱状图的优点在于其简单易懂,能够直观地展示数据分布。在信号处理中,柱状图可以帮助工程师识别信号中的模式、趋势和异常情况,从而为信号分析和处理提供有价值的见解。
# 2. 柱状图在信号处理中的应用
柱状图在信号处理
MATLAB平方根硬件加速探索:提升计算性能,拓展算法应用领域

# 1. MATLAB 平方根计算基础**
MATLAB 提供了 `sqrt()` 函数用于计算平方根。该函数接受一个实数或复数作为输入,并返回其平方根。`sqrt()` 函数在 MATLAB 中广泛用于各种科学和工程应用中,例如信号处理、图像处理和数值计算。
**代码块:**
```matlab
% 计算实数的平方根
x = 4;
sqrt_x = sqrt(x);
%
图像处理中的求和妙用:探索MATLAB求和在图像处理中的应用

# 1. 图像处理简介**
图像处理是利用计算机对图像进行各种操作,以改善图像质量或提取有用信息的技术。图像处理在各个领域都有广泛的应用,例如医学成像、遥感、工业检测和计算机视觉。
图像由像素组成,每个像素都有一个值,表示该像素的颜色或亮度。图像处理操作通常涉及对这些像素值进行数学运算,以达到增强、分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )