MapReduce任务调优指南:如何根据数据量精确配置MapTask数量


掌握 MapReduce 核心:ReduceTask 数据处理全解析
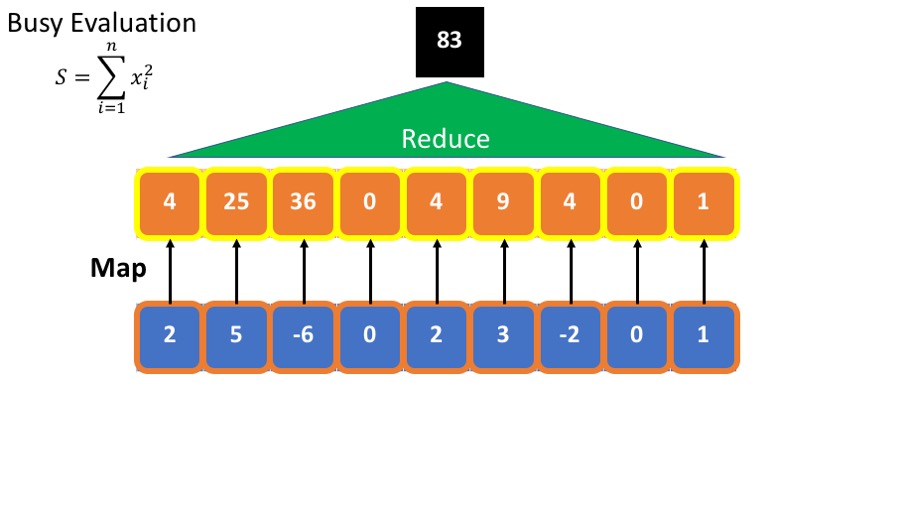
1. MapReduce基础和原理
在大数据处理领域,MapReduce已成为处理大量数据的关键技术之一。它是一种编程模型,用于处理并生成大规模数据集的并行算法。本章我们将探讨MapReduce的核心概念,以及其底层工作原理。
1.1 MapReduce的定义和作用
MapReduce是一种由Google提出的编程模型,主要用于在大量计算节点组成的分布式环境中处理数据。它通过简化算法的开发,使得开发者无需关注底层的并行计算和数据分布细节。MapReduce模型通过两个关键步骤处理数据:Map步骤和Reduce步骤。
在Map步骤中,输入数据被分割为独立的数据块,并在多个节点上并行处理。每个节点运行Map函数处理数据块,并输出中间键值对。接着,Reduce步骤中,相同键的所有值被合并处理,最终生成用户需要的结果。
1.2 MapReduce原理简介
MapReduce原理主要依赖于两个关键概念:映射(Map)和规约(Reduce)。在Map阶段,原始数据经过过滤和映射,转换为键值对形式;在Reduce阶段,相同键的所有值进行合并处理,以此来生成最终的输出结果。
MapReduce的运行机制包括以下部分:
- 输入分片(Input Splits):输入数据集被分割成固定大小的分片,每个分片独立由一个Map任务处理。
- Map任务:Map函数对分片中的数据进行处理,生成中间键值对输出。
- Shuffle过程:系统自动将具有相同键的中间键值对分组,并传递给相应的Reduce任务。
- Reduce任务:Reduce函数对分组后的数据进行处理,生成最终结果。
通过这样的分布式处理模式,MapReduce能够高效处理PB级别的数据量,成为大数据分析的基石。我们将在下一章节中深入探讨如何对MapReduce任务进行配置,以适应不同数据处理的需求。
2. MapReduce任务配置基础
MapReduce是一个强大的编程模型,广泛应用于大规模数据集的并行运算。它能够处理PB级别的数据,被多个分布式处理框架所采用,包括Hadoop。本章节将详细介绍MapReduce任务的基本配置方法和工作原理,帮助读者深入理解任务配置的细节,并能够在实际应用中进行合理配置。
2.1 MapReduce任务的基本参数
2.1.1 任务调度参数
MapReduce任务调度参数决定了任务的执行策略和调度顺序。掌握这些参数对于优化任务执行效率至关重要。
mapreduce.job.jar: 指定MapReduce作业的jar包,这是运行作业的主要类所在的jar包。mapreduce.job.name: 指定MapReduce作业的名称,这有助于在Hadoop集群中追踪和识别作业。mapreduce.jobtracker.address: 指定作业跟踪器的地址,这是Hadoop 1.x时代的参数,在Hadoop 2.x中已被yarn.resourcemanager.address替代。yarn.resourcemanager.address: 指定YARN资源管理器的地址,YARN是Hadoop 2.x引入的资源管理框架。
示例代码块:
- <configuration>
- <property>
- <name>mapreduce.job.jar</name>
- <value>myjob.jar</value>
- </property>
- <property>
- <name>mapreduce.job.name</name>
- <value>MyFirstMapReduce</value>
- </property>
- <!-- YARN specific configuration -->
- <property>
- <name>yarn.resourcemanager.address</name>
- <value>myresourcemanager:8032</value>
- </property>
- </configuration>
2.1.2 数据处理相关参数
在MapReduce中,数据处理相关的参数控制着数据的读写和处理方式,直接影响到作业的性能。
mapreduce.input.fileinputformat.split.minsize: 设置Map阶段处理数据块的最小大小。mapreduce.input.fileinputformat.split.maxsize: 设置Map阶段处理数据块的最大大小。***press: 是否对输出数据进行压缩,可选值为true或false。
示例代码块:
- <configuration>
- <!-- Set the minimum and maximum size of splits -->
- <property>
- <name>mapreduce.input.fileinputformat.split.minsize</name>
- <value>***</value> <!-- 10MB -->
- </property>
- <property>
- <name>mapreduce.input.fileinputformat.split.maxsize</name>
- <value>***</value> <!-- 100MB -->
- </property>
- <!-- Enable compression for output -->
- <property>
- <name>***press</name>
- <value>true</value>
- </property>
- </configuration>
2.2 MapTask的工作原理
MapTask是MapReduce框架中的核心组件之一,它的主要工作是读取输入数据,进行处理,并生成键值对(key-value pairs)供Reduce阶段使用。
2.2.1 MapTask的数据输入
MapTask从输入分片(splits)中读取数据,这些分片是由输入格式类(InputFormat)根据输入数据源划分的。常见的输入格式包括TextInputFormat和SequenceFileInputFormat等。
输入分片的处理流程:
- 读取分片信息:MapReduce运行时会读取作业的输入分片信息。
- 读取数据:使用相应的
RecordReader类从输入分片中读取数据,一般情况下,RecordReader会将数据转换为键值对形式。 - 键值对生成:最后生成的键值对作为输入传递给Mapper类。
示例代码块:
- public class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
- public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- // 处理键值对并输出
- context.write(value, new IntWritable(1));
- }
- }
2.2.2 MapTask的数据处理
Mapper类处理由RecordReader生成的键值对,并产生新的键值对输出。输出的键值对会被送入Partitioner进行分组,最终发送给对应的ReduceTask。
Mapper处理流程:
- 读取键值对:从
RecordReader读取键值对。 - 数据处理:通过Mapper的
map方法对键值对进行处理,并生成新的键值对。 - 分组排序:产生的键值对通过Partitioner确定发送至哪个ReduceTask,并按照key排序。
- 写入环形缓冲区:排序后的键值对写入环形缓冲区。
示例代码块:
- public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
- public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
- // 汇总计数
- int sum = 0;
- for (IntWritable val : values) {
- sum += val.get();
- }
-

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
一文读懂STC8单片机:架构解读与性能特点
eWebEditor全攻略:提升网页编辑效率的终极秘诀
STM32最小系统的电源管理与省电技巧:故障分析与解决方案
【电源设计诀窍】:LLC开关电源性能指标的准确计算(专家建议)
Kibana交互式仪表板:构建高效可视化解决方案
智能温湿度监控系统构建指南:STM32F103C8T6实战案例分析
vRealize Automation 7.0进阶配置:打造你的定制化自动化解决方案
波士顿矩阵在物联网项目中的决策分析:物联网时代的智能选择
vCenter Appliance的定期维护任务:保持系统最佳性能的顶级指南


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )