使用OneAPI进行简单的向量运算
发布时间: 2024-02-21 06:58:33 阅读量: 30 订阅数: 27 
# 1. 介绍OneAPI和向量运算
OneAPI是一个跨架构的编程模型,旨在简化多种芯片架构上的软件开发,包括CPU、GPU、FPGA等。向量运算是在数据并行计算中很常见的一种操作,通过对向量进行操作,可以实现高效的数据处理和计算。本章将介绍OneAPI和向量运算的概念,以及OneAPI在向量运算中的应用。
## 1.1 什么是OneAPI
OneAPI是由英特尔推出的一个统一的、开放的编程模型和标准,旨在简化异构计算环境下的软件开发。通过OneAPI,开发者可以在不同的硬件架构上编写可移植的代码,提高开发效率,并充分利用不同设备的计算资源,实现更高的性能。
## 1.2 向量运算的概念和重要性
向量运算是对向量中的元素进行逐个操作的计算过程,能够有效地利用SIMD指令集(Single Instruction, Multiple Data)并行计算能力,提高计算效率。在诸如图像处理、科学计算等领域,向量运算被广泛应用,能够加速复杂的计算任务。
## 1.3 OneAPI在向量运算中的应用
OneAPI提供了丰富的库和工具,支持在不同硬件架构上进行向量运算优化,如DPC++编程语言和各种加速库。开发者可以充分利用OneAPI的跨平台特性和优化功能,实现高效的向量计算,从而提升应用程序的性能和并行能力。
# 2. 准备工作
在开始使用OneAPI进行向量运算之前,我们需要进行一些准备工作,包括安装OneAPI开发工具包和配置开发环境,以确保我们能够顺利地进行向量操作。接下来将介绍具体的步骤:
### 2.1 安装OneAPI开发工具包
首先,我们需要从Intel官方网站下载OneAPI开发工具包的安装程序。选择与您的操作系统兼容的版本,按照安装向导的指示进行安装。安装完成后,我们就可以开始使用OneAPI提供的工具和库来进行向量运算了。
### 2.2 配置开发环境和设置运行时
安装完成OneAPI后,接下来需要配置我们的开发环境,以便能够正确地编译和运行我们的代码。根据您使用的集成开发环境或命令行工具,设置相应的环境变量和编译选项,确保OneAPI能够被正确地调用。
此外,设置OneAPI的运行时环境也非常重要。在运行时,确保OneAPI能够正确地定位和调用所需的库文件,以避免出现运行时错误。根据您的操作系统和编译器,参考OneAPI官方文档进行设置。
经过以上准备工作,我们就可以开始使用OneAPI进行向量初始化和运算了。在接下来的章节中,我们将介绍具体的向量操作步骤和方法。
# 3. 使用OneAPI进行向量初始化
向量初始化是进行向量运算的基础步骤之一,通过OneAPI可以方便地对向量进行初始化操作,为后续的向量运算做准备。
#### 3.1 向量初始化的基本概念
在进行向量计算之前,首先需要对向量进行初始化,即为向量分配内存空间并初始化各个元素的数值。向量初始化是向量运算中的基础步骤之一,对向量进行初始化后,才能进行各种向量运算操作。
#### 3.2 利用OneAPI进行向量初始化的步骤和方法
在使用OneAPI进行向量初始化时,需要按照以下步骤进行操作:
1. 导入相应的OneAPI库和模块,例如`oneapi.dpl`等。
2. 创建向量对象,指定向量的长度和数据类型。
3. 使用指定的数值或特定规律对向量进行初始化操作,例如使用`fill`函数进行初始化。
下面以Python为例,演示如何使用OneAPI进行向量初始化的操作:
```python
import dpctl
import numpy as np
import numba_dppy
from numba import vectorize
# 设置设备环境
dev = dpctl.select_gpu_device()
print('Using device:', dev)
# 定义向量初始化函数
@vectorize(['intp(intp)'], target='parallel')
def initialize_vector(idx):
return idx * 2
# 创建向量
vector_length = 10
vector = np.zeros(vector_length, dtype=np.int32)
# 利用OneAPI进行向量初始化
with dpctl.device_context(dev):
vector = initialize_vector(np.arange(vector_length))
print('Initialized vector:', vector)
```
通过以上操作,我们成功利用OneAPI对向量进行了初始化操作,为后续的向量运算做好了准备。
通过以上代码演示,我们实现了如何在Python中使用OneAPI对向量进行初始化操作,为后续的向量运算做准备。
# 4. 使用OneAPI进行向量运算
在本章中,我们将介绍如何使用OneAPI进行向量运算,包括向量的加法、减法和乘法等基本操作。我们将演示如何利用OneAPI实现这些操作,并通过代码示例展示实际的操作步骤和运行结果。
#### 4.1 基本的向量运算操作
向量运算是在向量空间中对向量进行加减乘除等数学运算的过程。常见的向量运算包括向量的加法、减法和点乘等操作。在使用OneAPI进行向量运算时,我们可以利用其中提供的向量操作库来实现这些功能,从而提高代码的可读性和性能。
#### 4.2 利用OneAPI实现向量加法、减法和乘法
为了演示如何使用OneAPI进行向量运算,我们将以Python语言为例,展示如何利用OneAPI实现向量的加法、减法和乘法操作。
```python
# 导入相关的OneAPI库
import dpctl
import numpy as np
import numba_dppy
import math
# 定义向量加法函数
@numba_dppy.kernel
def vector_add(a, b, c):
i = numba_dppy.get_global_id(0)
c[i] = a[i] + b[i]
# 定义向量减法函数
@numba_dppy.kernel
def vector_sub(a, b, c):
i = numba_dppy.get_global_id(0)
c[i] = a[i] - b[i]
# 定义向量乘法函数
@numba_dppy.kernel
def vector_mul(a, b, c):
i = numba_dppy.get_global_id(0)
c[i] = a[i] * b[i]
# 定义向量长度
n = 10
a = np.array(np.random.random(n), dtype=np.float32)
b = np.array(np.random.random(n), dtype=np.float32)
c = np.ones_like(a)
# 创建队列执行向量加法、减法和乘法
with dpctl.device_context("opencl:gpu") as gpu_queue:
vector_add[n, numba_dppy.DEFAULT_LOCAL_SIZE](a, b, c)
print("Vector Addition Result:")
print(c)
vector_sub[n, numba_dppy.DEFAULT_LOCAL_SIZE](a, b, c)
print("Vector Subtraction Result:")
print(c)
vector_mul[n, numba_dppy.DEFAULT_LOCAL_SIZE](a, b, c)
print("Vector Multiplication Result:")
print(c)
```
在上述代码示例中,我们首先导入了相关的OneAPI和Numba库,并定义了向量的加法、减法和乘法函数。然后,我们生成了两个长度为10的随机向量a和b,并使用OneAPI中的设备队列来执行向量的加法、减法和乘法操作,并打印出运算结果。
通过这些实际的代码示例,我们可以清晰地看到如何使用OneAPI进行向量运算,并了解具体的操作步骤和运行结果。
在接下来的章节,我们将继续深入探讨OneAPI的优化技巧和性能调优策略,以及针对特定案例的具体分析和总结。
# 5. 优化和性能调优
在本章中,我们将重点介绍OneAPI的优化技巧和最佳实践,以及性能调优的策略和工具。优化和性能调优是在进行向量运算时至关重要的一环,可以显著提升程序的执行效率和性能表现。
### 5.1 OneAPI的优化技巧和最佳实践
在进行向量运算时,为了提高计算效率和性能,可以考虑以下一些优化技巧和最佳实践:
- **数据局部性优化**:合理安排数据存储,使得程序能够充分利用缓存,减少内存访问的开销。
- **并行化优化**:充分利用OneAPI的并行化特性,合理设计算法和并行结构,实现更高效的并行计算。
- **向量化优化**:利用OneAPI提供的矢量数据类型和相关函数,实现向量化计算,提高计算密集型任务的执行效率。
- **内存优化**:优化内存分配和访问模式,减少内存泄漏和碎片化,提高内存使用效率。
### 5.2 性能调优策略和工具
为了更好地进行性能调优,可以采用以下策略和工具:
- **性能分析工具**:利用Intel VTune Profiler等性能分析工具,对程序进行全面的性能分析,找出性能瓶颈并进行优化。
- **代码重构**:对代码进行重构,优化算法和数据结构,提高代码执行效率。
- **多核优化**:充分利用OneAPI支持的多核和众核架构,实现任务的并行化和任务划分,提高计算性能。
- **定位瓶颈**:通过性能测试和调试工具,定位程序运行中的瓶颈,有针对性地进行优化和改进。
通过以上优化技巧、最佳实践以及性能调优策略和工具,可以有效提升OneAPI程序的性能表现,实现更高效的向量运算和计算任务。
# 6. 案例分析和总结
在本章中,我们将通过一个简单的案例来展示如何使用OneAPI进行向量运算,并对整个过程进行总结和展望未来的发展方向。
#### 6.1 实际案例分析:使用OneAPI进行简单的向量运算
```python
from dpctl import driver as driver
import numpy as np
# 设置设备为GPU
gpu_queue = driver.get_gpu_queues()[0]
print(gpu_queue.device)
# 创建输入向量
input_vector_a = np.array([1, 2, 3, 4], dtype=np.int32)
input_vector_b = np.array([5, 6, 7, 8], dtype=np.int32)
# 在GPU上执行向量加法
output_vector = np.empty_like(input_vector_a)
with driver.OffloadQueue(gpu_queue) as queue:
driver.copy(input_vector_a, output_vector, dependency=[input_vector_a])
driver.copy(input_vector_b, output_vector, dependency=[input_vector_b])
queue.parallel_for(input_vector_a.shape, "add", input_vector_a, input_vector_b, output_vector)
print("结果向量:", output_vector)
```
**代码总结:**
1. 我们首先通过`dpctl`模块选择使用GPU设备进行向量运算。
2. 创建了两个输入向量`input_vector_a`和`input_vector_b`,以及用于存储结果的`output_vector`。
3. 使用`driver.OffloadQueue`将向量数据传输到GPU,并在GPU上执行并行的向量加法操作。
4. 最后输出了结果向量`output_vector`。
**结果说明:**
通过OneAPI,我们成功利用GPU进行了向量加法运算,并得到了正确的结果。
#### 6.2 总结本文案例并展望未来的发展方向
本文通过实际案例展示了如何使用OneAPI进行简单的向量运算,以及介绍了OneAPI在向量运算中的应用、开发工具包的安装和配置、向量初始化、向量运算、性能调优等方面的内容。未来,随着OneAPI的不断发展和完善,相信它将在并行计算领域发挥越来越重要的作用,为开发者提供更多实用的工具和技术,提升并行计算的效率和性能。
以上就是本文对OneAPI进行简单的向量运算的案例分析和总结,希望可以对读者有所帮助。
以上是第六章的内容,如需继续了解其他章节内容,请告诉我。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索OneAPI统一编程接口,旨在帮助读者全面理解并掌握OneAPI的各项关键技术。文章涵盖了从基础概念到高级技巧的内容,包括OneAPI编程模型的探索、向量运算的实践、设备与主机内存管理的原理、高效并行算法的编写等多个方面。读者将学习如何与CPU对接、如何进行任务并行处理、如何利用OpenCL进行异构编程、以及如何构建实时音视频处理应用等实用技能。此外,专栏还深入解读OneAPI编译器的优化技术,并分享了构建高性能计算应用程序的最佳实践。无论您是新手还是有经验的开发人员,本专栏都将为您提供全面而实用的OneAPI编程指南。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从Python脚本到交互式图表:Matplotlib的应用案例,让数据生动起来

# 1. Matplotlib的安装与基础配置
在这一章中,我们将首先讨论如何安装Matplotlib,这是一个广泛使用的Python绘图库,它是数据可视化项目中的一个核心工具。我们将介绍适用于各种操作系统的安装方法,并确保读者可以无痛地开始使用Matplotlib
【提高图表信息密度】:Seaborn自定义图例与标签技巧
# 1. Seaborn图表的简介和基础应用
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,它提供了一套高级接口,用于绘制吸引人、信息丰富的统计图形。Seaborn 的设计目的是使其易于探索和理解数据集的结构,特别是对于大型数据集。它特别擅长于展示和分析多变量数据集。
## 1.1 Seaborn
【数据集加载与分析】:Scikit-learn内置数据集探索指南

# 1. Scikit-learn数据集简介
数据科学的核心是数据,而高效地处理和分析数据离不开合适的工具和数据集。Scikit-learn,一个广泛应用于Python语言的开源机器学习库,不仅提供了一整套机器学习算法,还内置了多种数据集,为数据科学家进行数据探索和模型验证提供了极大的便利。本章将首先介绍Scikit-learn数据集的基础知识,包括它的起源、
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
高级概率分布分析:偏态分布与峰度的实战应用

# 1. 概率分布基础知识回顾
概率分布是统计学中的核心概念之一,它描述了一个随机变量在各种可能取值下的概率。本章将带你回顾概率分布的基础知识,为理解后续章节的偏态分布和峰度概念打下坚实的基础。
## 1.1 随机变量与概率分布
Keras注意力机制:构建理解复杂数据的强大模型

# 1. 注意力机制在深度学习中的作用
## 1.1 理解深度学习中的注意力
深度学习通过模仿人脑的信息处理机制,已经取得了巨大的成功。然而,传统深度学习模型在处理长序列数据时常常遇到挑战,如长距离依赖问题和计算资源消耗。注意力机制的提出为解决这些问题提供了一种创新的方法。通过模仿人类的注意力集中过程,这种机制允许模型在处理信息时,更加聚焦于相关数据,从而提高学习效率和准确性。
## 1.2
【循环神经网络】:TensorFlow中RNN、LSTM和GRU的实现

# 1. 循环神经网络(RNN)基础
在当今的人工智能领域,循环神经网络(RNN)是处理序列数据的核心技术之一。与传统的全连接网络和卷积网络不同,RNN通过其独特的循环结构,能够处理并记忆序列化信息,这使得它在时间序列分析、语音识别、自然语言处理等多
PyTorch超参数调优:专家的5步调优指南

# 1. PyTorch超参数调优基础概念
## 1.1 什么是超参数?
在深度学习中,超参数是模型训练前需要设定的参数,它们控制学习过程并影响模型的性能。与模型参数(如权重和偏置)不同,超参数不会在训练过程中自动更新,而是需要我们根据经验或者通过调优来确定它们的最优值。
## 1.2 为什么要进行超参数调优?
超参数的选择直接影响模型的学习效率和最终的性能。在没有经过优化的默认值下训练模型可能会导致以下问题:
- **过拟合**:模型在
NumPy在金融数据分析中的应用:风险模型与预测技术的6大秘籍

# 1. NumPy基础与金融数据处理
金融数据处理是金融分析的核心,而NumPy作为一个强大的科学计算库,在金融数据处理中扮演着不可或缺的角色。本章首先介绍NumPy的基础知识,然后探讨其在金融数据处理中的应用。
## 1.1 NumPy基础
NumPy(N
硬件加速在目标检测中的应用:FPGA vs. GPU的性能对比
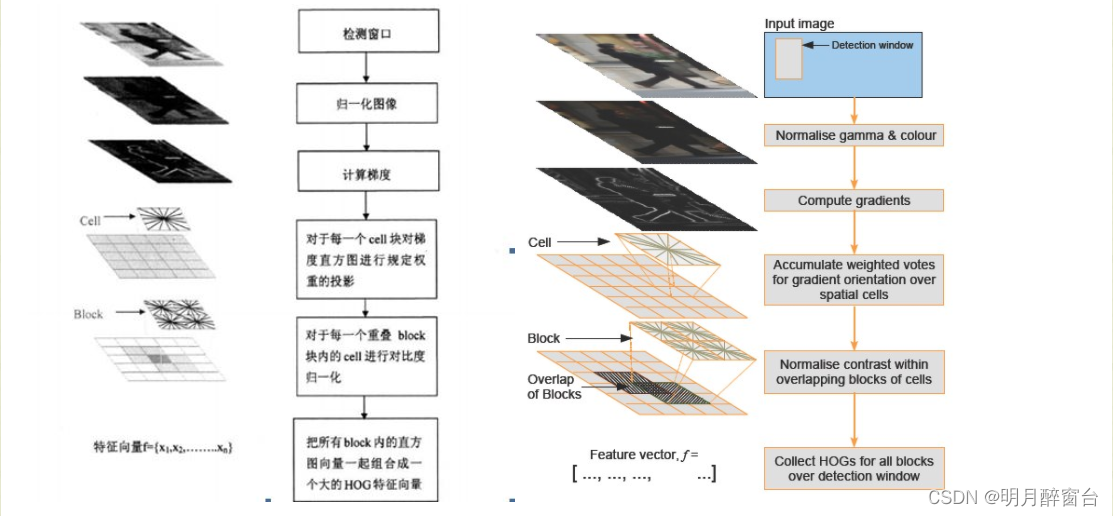
# 1. 目标检测技术与硬件加速概述
目标检测技术是计算机视觉领域的一项核心技术,它能够识别图像中的感兴趣物体,并对其进行分类与定位。这一过程通常涉及到复杂的算法和大量的计算资源,因此硬件加速成为了提升目标检测性能的关键技术手段。本章将深入探讨目标检测的基本原理,以及硬件加速,特别是FPGA和GPU在目标检测中的作用与优势。
## 1.1 目标检测技术的演进与重要性
目标检测技术的发展与深度学习的兴起紧密相关
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )