如何在单链表中实现元素的逆序输出
发布时间: 2024-04-12 09:54:15 阅读量: 98 订阅数: 45 

C语言实现单链表逆序与逆序输出实例
# 1. 链表数据结构简介
链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据和指向下一个节点的指针。单链表是最基本的链表结构,具有一个指向下一个节点的指针。单链表的优点是插入和删除节点方便快捷,但查找节点需要遍历整个链表。双链表和循环链表在单链表的基础上进行了扩展,双链表的节点包含指向前一个节点的指针,循环链表的尾节点指向头节点,形成一个闭环。双链表可以实现双向遍历,而循环链表适用于需要首尾相连的场景。链表在实际开发中广泛应用于实现队列、栈、LRU 缓存等数据结构和算法。
# 2. 单链表的创建与基本操作
#### 2.1 创建单链表
##### 2.1.1 头插法创建单链表
在头插法创建单链表中,需要先声明节点类,包含数值和指向下一个节点的指针。接着,初始化头节点为空,循环读入数据并用头插法插入新节点。最后返回头节点即可。
```python
class Node:
def __init__(self, data=None):
self.data = data
self.next = None
def create_linked_list_head():
head = Node()
while True:
data = input("Enter data to be inserted into the linked list (press Enter to stop): ")
if not data:
break
new_node = Node(data)
new_node.next = head.next
head.next = new_node
return head
```
##### 2.1.2 尾插法创建单链表
尾插法创建单链表同样需要节点类的声明,以及头节点的初始化。不同之处在于尾插法是将新节点插入到链表的末尾,因此需要维护一个指向链表尾部的指针。
```python
def create_linked_list_tail():
head = Node()
tail = head
while True:
data = input("Enter data to be inserted into the linked list (press Enter to stop): ")
if not data:
break
new_node = Node(data)
tail.next = new_node
tail = new_node
return head
```
#### 2.2 遍历单链表
##### 2.2.1 顺序遍历
顺序遍历单链表即从头节点开始,依次访问每个节点的数值。当节点的指针为空时,表示到达链表末尾,遍历结束。
```python
def traverse_linked_list(head):
current = head.next
while current:
print(current.data, end=' ')
current = current.next
```
##### 2.2.2 递归遍历
递归遍历单链表可以通过递归函数实现,首先判断节点是否为空,若为空则返回,不为空则输出当前节点的数值并递归地调用函数遍历下一个节点。
```python
def recursive_traverse(head):
d
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了单链表的数据结构,包括其基本操作和高级应用。从单链表的插入和删除操作开始,逐步深入探讨了单链表的节点插入、删除、查找、逆序输出、遍历和环检测等关键操作。同时,还分析了插入和删除操作的时间复杂度,探讨了单链表中的特殊节点(头节点和尾节点)以及单链表的合并、相交判断、反转和快速排序等高级应用。最后,还介绍了单链表的递归操作与迭代操作对比,以及如何解决单链表中的内存泄漏问题。本专栏旨在为读者提供全面的单链表知识,帮助他们掌握这一重要的数据结构及其应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python遥感图像裁剪专家课:一步到位获取精准图像样本

# 摘要
本文详细介绍了Python在遥感图像裁剪领域的应用,首先概述了遥感图像裁剪的基本概念、理论以及应用场景。随后深入探讨了配置P
【TCAD网格划分技巧】:Silvaco仿真精度与速度提升指南

# 摘要
TCAD(技术计算机辅助设计)中的网格划分是确保模拟仿真实现高精度和高效率的关键步骤。本文从基础理论到实践技巧,再到高级应用和未来发展趋势,系统地探讨了TCAD网格划分的不同方面。重点分析了网格划分对仿真精度和速度的影响,阐述了网格类型选择、密度控制以及网格生成算法等基本理论。通过比较不同的网格划分工具和软件,本文提供了实用的实践技巧,并通过案例分析加深理解。同时,探讨了自适应网格划分技术、并行计算和多物理场
【COMSOL Multiphysics软件基础入门】:XY曲线拟合中文操作指南
# 摘要
本文全面介绍了COMSOL Multiphysics软件在XY曲线拟合中的应用,旨在帮助用户通过高级拟合功能进行高效准确的数据分析。文章首先概述了COMSOL软件,随后探讨了XY曲线拟合的基本概念,包括数学基础和在COMSOL中的应用。接着,详细阐述了在COMSOL中进行XY曲线拟合的具体步骤,包括数据准备、拟合过程,
【EmuELEC全面入门与精通】:打造个人模拟器环境(7大步骤)

# 摘要
EmuELEC是一款专为游戏模拟器打造的嵌入式Linux娱乐系统,旨在提供一种简便、快速的途径来设置和运行经典游戏机模拟器。本文首先介绍了EmuELEC的基本概念、硬件准备、固件获取和初步设置。接着,深入探讨了如何定制EmuELEC系统界面,安装和配置模拟器核心,以及扩展其功能。文章还详细阐述了游戏和媒体内容的管理方法,包括游戏的导入、媒体内容的集成和网络功能的
【数据降维实战宝典】:主成分分析(PCA)的高级应用与优化策略

# 摘要
主成分分析(PCA)是一种广泛应用于数据降维、模式识别、图像处理等领域的统计方法。本文旨在系统地介绍PCA的基础理论、
计算机考研(408)数据结构与算法实战训练:全面提升解题技能

# 摘要
本论文系统地介绍了数据结构与算法的基础知识,深入分析了算法效率的评估标准和优化策略。通过对时间复杂度和空间复杂度的讨论,特别是大O表示法的理解和常见算法实例的分析,文章强调了算法设计中分而治之、动态规划、贪心算法与回溯算法的重要性。在数据结构方面,详细探讨了链表、树、高级树结构如B树和红黑树的实现和应用,以及图论在算法中的作用,包括图的表示、遍历、最短路径算法和连通性问题。最后,通过综合算法题目的实战训练,本文阐述
【机器学习入门】:用NASA电池数据集构建你的第一个算法模型

# 摘要
本文从机器学习的基础理论出发,结合NASA电池数据集的应用场景,详细介绍了构建预测电池衰退模型的方法与过程。首先,本文对机器学习的基本概念及其应用场景进行了概述,并对NASA电池数据集的背景、重要性及其结构进行了深入的探讨。接着,文中详细阐述了理论基础,包括机器学习算法的分类、模型训练与测试的方法,以及特征工程与模型优化策略。在实践操作部分,本文指导了如
【GAMS非线性规划应用】:手册翻译,非线性模型构建轻松掌握!
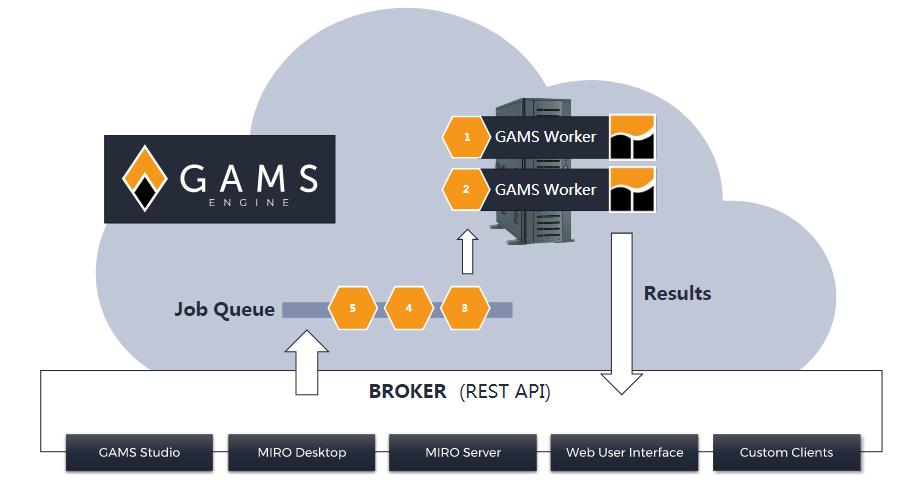
# 摘要
本文系统地介绍了GAMS在非线性规划领域的应用和理论基础。第一章概述了GAMS的基础知识及其在非线性规划中的作用。第二章深入探讨了非线性规划的基本概念、分类以及在GAMS中的求解方法和理论优化技巧。第三章阐述了如何在GAMS中构建非线性模型并进行求解和结果分析。第四章通过多个领域的应用案例展示了GAMS非线性规划的实际效用。第五章介绍了GAMS的高级功能,包括高级求解技术、与外部软件的集成以及提升模型
西门子G120C变频器集成必备

# 摘要
西门子G120C变频器作为一款先进的驱动设备,广泛应用于各类工业控制领域。本文首先对G120C变频器进行了概述,随后详细介绍了其安装、配置以及系统集成的步骤和要点,着重于硬件安装要点、软件配置以及控制与编程技术。文章还探讨了变频器的高级应用,包括通信能力、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )