Euler函数与最大公约数的关系
发布时间: 2023-12-20 10:32:53 阅读量: 23 订阅数: 29 
# 1. Euler函数和最大公约数简介
## 1.1 Euler函数的定义和性质
Euler函数,也称为欧拉函数,通常用符号$\phi(n)$表示,表示小于等于n且与n互质的正整数的个数。具体而言,对于正整数n,Euler函数$\phi(n)$的计算公式为:
$$
\phi(n) = n \times \left(1 - \frac{1}{p_1}\right) \times \left(1 - \frac{1}{p_2}\right) \times \ldots \times \left(1 - \frac{1}{p_k}\right)
$$
其中,$p_1, p_2, \ldots, p_k$为n的所有不同的质因数。
Euler函数具有以下性质:
- 若n为质数p,则$\phi(p) = p - 1$
- 若m,n互质,则$\phi(m \times n) = \phi(m) \times \phi(n)$
## 1.2 最大公约数的概念和计算方法
最大公约数(Greatest Common Divisor,简称GCD)指的是两个或多个整数共有约数中最大的一个。常用的求解方法包括欧几里得算法(Euclidean algorithm)和辗转相除法。欧几里得算法的具体过程如下:
```python
def gcd(a, b):
while b:
a, b = b, a % b
return a
```
欧几里得算法通过递归地求解两个数的余数,直到余数为0,此时另一个数即为最大公约数。
## 2. Euler函数与最大公约数的关系
2.1 Euler函数与最大公约数的数学关联
2.2 基于Euler函数的最大公约数的应用
### 3. 计算机科学中的Euler函数和最大公约数
### 4. 数论中的Euler函数与最大公约数
在数
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以“gcd”为主题,深入探讨了最大公约数(GCD)及其相关概念。从初识最大公约数开始,逐步介绍了欧几里得算法和辗转相除法等计算最大公约数的方法,并对GCD算法进行了优化,提出更快速的计算方法。同时,还探讨了最大公约数与最小公倍数的关系,以及在素数分解、模运算、线性同余方程等领域的应用。此外,还涉及GCD在数据结构、密码学、多项式运算等方面的运用,以及与Euler函数、欧拉定理等的关联。最后,对GCD算法的复杂度进行了分析,并探讨了在寻找线性关系和解决循环小数等问题中的应用。通过本专栏的阅读,读者将深入了解最大公约数的计算方法、性质及在不同领域的实际应用,为相关领域的学习和应用提供了丰富的知识储备。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MySQL数据库连接池与缓存:协同提升数据库访问速度

# 1. MySQL数据库连接池概述
连接池是一种数据库管理机制,它通过预先建立并维护一定数量的数据库连接,从而减少应用程序与数据库服务器之间的连接建立和销毁开销,提升数据库访问性能。
连接池通常由以下几个组件组成:
- **连接池管理器:**负责创建、管理和分配连接。
- **连接对象:**封装了与数据库服务器
网络安全风险评估全攻略:识别、应对,构建全面风险评估体系

# 1. 网络安全风险评估概述**
网络安全风险评估是识别、分析和评估网络系统面临的潜在威胁和漏洞的过程。其目的是帮助组织了解其网络安全态势,并制定相应的对策来降低风险。
风险评估涉及识别和分析资产、威胁和漏洞,并评估其对组织的影响。通过评估风险,组织可以确定需要优先处理的领域,并制定相应的缓解措施。
风险评估是一个持续的过程,需要定期进行以跟上不断变化的威胁格局。它有助于组织保
action返回json数据库的测试:确保json转换的准确性和可靠性

# 1. Action返回JSON数据库的测试概述
在现代Web开发中,Action返回JSON数据已成为一种常见的实践,它允许在客户端和服务器之间轻松高效地传输数据。为了确保Action返回的JSON数据准确可靠,测试至关重要。本章将概述Action返回JSON数据库的测试策略,包括测试目标、测试类型和测试工具。
**测试目标**
Action返回JSON
JSON数据存储教育应用:数字化学习与知识共享,赋能教育未来
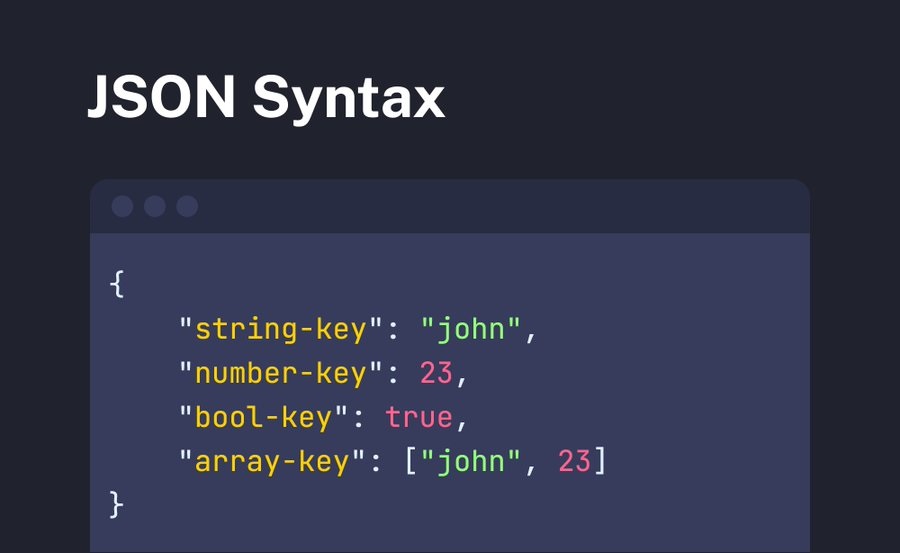
# 1. JSON数据存储概述
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,因其易于阅读和解析而广泛用于存储和传输数据。在教育应用中,JSON数据存储具有以下优点:
- **灵活性:**JSON数据结构灵活,可以存储各种类型的数据,包括对象、数组和嵌套数据。
- **可扩展性:**JSON数据可以轻松扩展,添加或删除字段而不会破坏现有数据。
- **易于解析:**JSON数据可以使用多种编程语言轻松
MySQL数据库启动时服务依赖问题:解决服务依赖问题,保障启动成功

# 1. MySQL数据库启动时服务依赖问题概述
MySQL数据库在启动过程中,需要依赖其他服务或组件才能正常运行。这些服务依赖关系是MySQL数据库启动成功的重要前提。然而,在实际运维中,服务依赖问题往往会成为MySQL数据库启动失败的常见原因。
本章将概述MySQL数据库启动时常见的服务依赖问题,包括依赖关系的概念和重要性,以及MySQL数据库的具体服务依赖关系。通过理解这些问题,可以为后续的服
MySQL数据库与PHP JSON交互:云计算与分布式系统的深入分析

# 1. MySQL数据库与PHP JSON交互概述
### 1.1 背景介绍
MySQL数据库是当今最流行的关系型数据库管理系统之一
边缘计算环境下MySQL数据库备份挑战与解决方案:应对挑战,保障数据安全

# 1. 边缘计算环境下MySQL数据库备份的挑战**
在边缘计算环境中,MySQL数据库备份面临着独特的挑战。这些挑战源于边缘设备资源受限和网络延迟等特性。
**资源受限:**边缘设备通常具有有限的计算能力、内存和存储空间。这使得传统的备份方法,如全量备份,在边缘设备上不可行。
**网络延迟:**边缘设备通常位于网络边缘,与中心数据中心
MySQL数据类型与数据迁移:选择合适的数据类型,优化迁移效率

# 1. MySQL数据类型概述**
MySQL数据类型是用于定义数据库表中列的数据格式和存储规则。不同的数据类型具有不同的存储容量、精度和处理特性,对数据库性能和存储空间利用率有直接影响。
常见的数
MySQL数据库还原后存储过程失效:如何恢复存储过程

# 1. MySQL数据库还原后存储过程失效的原因分析
MySQL数据库还原后,存储过程失效的原因可能有多种。常见原因包括:
- **对象所有权变更:**还原过程可能导致存储过程的所有权发生变更,导致当前用户无法访问或执行存储过程。
- **依赖项丢失:**存储过程可能依赖于其他数据库对象,例如表或函数。如果这些依赖项在还原过程中丢失或损坏,存储过程将无法正常执行。
- **字符集或排序规则不匹配
MySQL JSON数据查询优化宝典:提升查询效率,解锁数据洞察
# 1. MySQL JSON数据查询基础
JSON(JavaScript Object Notation)是一种流行的数据格式,广泛用于存储和传输复杂数据结构。MySQL支持JSON数据类型,允许用户存储和查询JSON数据。
### 1.1 JSO
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )