Jdk1.8 HashMap实现原理详解与碰撞处理策略
107 浏览量
更新于2024-09-03
收藏 358KB PDF 举报
**Jdk1.8 HashMap实现原理详解**
Jdk1.8版本的HashMap是一种基于哈希表的Map接口非同步实现,它支持null值和null键,但不保证映射的顺序稳定性。HashMap的核心数据结构由数组和链表或红黑树组成,这在内存管理上提供了高效的数据存储和查找能力。
HashMap的核心数据结构:
1. 数组(Node[] table):这是HashMap的基础,存储着键值对,每个数组元素关联一个Node对象,Node是内部类,包含键(key)、值(value)、哈希码(hash)和指向下一个Node的引用(next)。数组大小是动态调整的,以适应不同负载情况。
2. 链地址法(Open Addressing):当哈希冲突(Hash碰撞)发生时,数据会被插入到数组相应位置的链表中。早期版本的HashMap使用链表解决冲突,但在Jdk1.8之后,引入了红黑树的优化。当链表长度超过8时,会将链表转换为红黑树,这样可以保持查询性能,减少遍历整个链表的开销。
3. 红黑树:这是一种自平衡二叉查找树,它能够确保在最坏情况下,查找、插入和删除操作的时间复杂度仍为O(log n)。当链表过长变为红黑树后,可以提高并发环境下的性能,因为红黑树的查找效率更高。
为了平衡空间和时间成本,HashMap的设计策略是:
- 根据负载因子(load factor,通常默认为0.75)动态调整数组大小。当元素数量接近数组容量的75%时,会自动扩容,将链表转为红黑树,从而降低碰撞概率。
- 采用优秀的哈希函数:虽然无法完全避免碰撞,但好的哈希函数能尽可能地均匀分布键值,减少冲突。Jdk1.8中的哈希函数经过精心设计,旨在减小碰撞发生的可能性。
总结,Jdk1.8 HashMap的实现原理着重于数组、链表和红黑树的巧妙结合,以及哈希算法的选择与动态调整,以提供高效且稳定的键值对存储和查询功能。理解这些原理有助于开发者更好地利用HashMap,并在实际应用中优化性能。
Jdk1.8 HashMap实现原理详细介绍实现原理详细介绍
主要介绍了Jdk1.8 HashMap实现原理详细介绍的相关资料,需要的朋友可以参考下
HashMap概述概述
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap的数据结构的数据结构
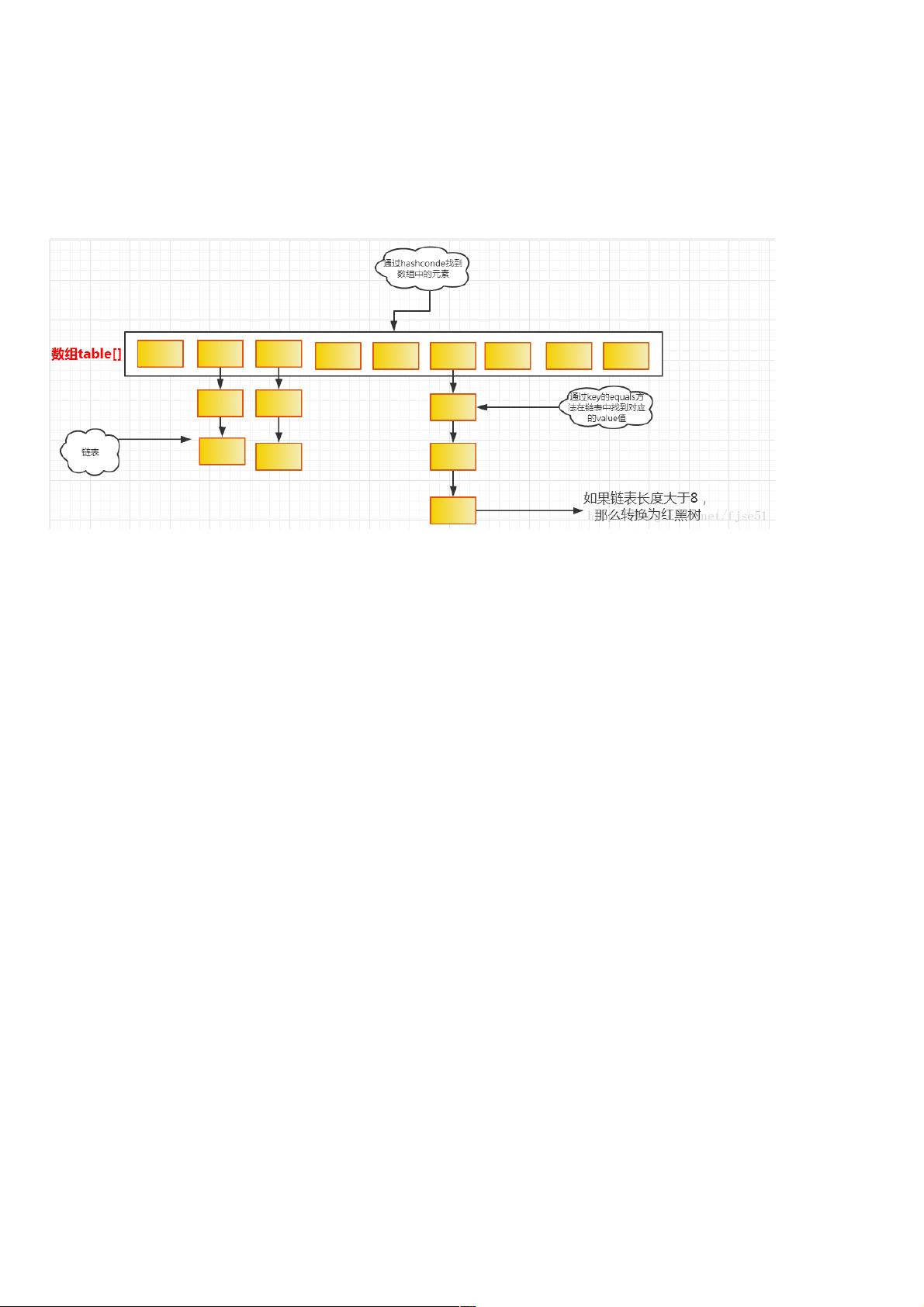
在Java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap
实际上是一个“链表散列”的数据结构,即数组和链表的结构,但是在jdk1.8里
加入了红黑树的实现,当链表的长度大于8时,转换为红黑树的结构。
从上图中可以看出,java中HashMap采用了链地址法。链地址法,简单来说,就是数组加链表的结合。在每个数组元素上都一个链表结构,当数据被Hash后,得到数组下标,把
数据放在对应下标元素的链表上。
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;//用于定位数组索引的位置
final K key;
V value;
Node<K,V> next;//链表的下一个Node
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
Node是HashMap的一个内部类,实现了Map.Entry接口,本质是就是一个映射(键值对)。
有时两个key会定位到相同的位置,表示发生了Hash碰撞。当然Hash算法计算结果越分散均匀,Hash碰撞的概率就越小,map的存取效率就会越高。
HashMap类中有一个非常重要的字段,就是 Node[] table,即哈希桶数组,明显它是一个Node的数组。
如果哈希桶数组很大,即使较差的Hash算法也会比较分散,如果哈希桶数组数组很小,即使好的Hash算法也会出现较多碰撞,所以就需要在空间成本和时间成本之间权衡,其
实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的hash算法减少Hash碰撞。那么通过什么方式来控制map使得Hash碰撞的概率又小,哈希桶数组(Node[]
table)占用空间又少呢?答案就是好的Hash算法和扩容机制。
在理解Hash和扩容流程之前,我们得先了解下HashMap的几个字段。从HashMap的默认构造函数源码可知,构造函数就是对下面几个字段进行初始化,源码如下:
int threshold; // 所能容纳的key-value对极限
final float loadFactor; // 负载因子
int modCount;
int size;
首先,Node[] table的初始化长度length(默认值是16),Load factor为负载因子(默认值是0.75),threshold是HashMap所能容纳的最大数据量的Node(键值对)个数。threshold =
length * Load factor。也就是说,在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
结合负载因子的定义公式可知,threshold就是在此Load factor和length(数组长度)对应下允许的最大元素数目,超过这个数目就重新resize(扩容),扩容后的HashMap容量是之前
容量的两倍。默认的负载因子0.75是对空间和时间效率的一个平衡选择,建议大家不要修改,除非在时间和空间比较特殊的情况下,如果内存空间很多而又对时间效率要求很
高,可以降低负载因子Load factor的值;相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
size这个字段其实很好理解,就是HashMap中实际存在的键值对数量。注意和table的长度length、容纳最大键值对数量threshold的区别。而modCount字段主要用来记录
HashMap内部结构发生变化的次数,主要用于迭代的快速失败。强调一点,内部结构发生变化指的是结构发生变化,例如put新键值对,但是某个key对应的value值被覆盖不属
于结构变化。
在HashMap中,哈希桶数组table的长度length大小必须为2的n次方(一定是合数),这是一种非常规的设计,常规的设计是把桶的大小设计为素数。相对来说素数导致冲突的概率
要小于合数,具体证明可以参考//www.jb51.net/article/100911.htm,Hashtable初始化桶大小为11,就是桶大小设计为素数的应用(Hashtable扩容后不能保证还是素数)。
HashMap采用这种非常规设计,主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap定位哈希桶索引位置时,也加入了高位参与运算的过程。
这里存在一个问题,即使负载因子和Hash算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响HashMap的性能。于是,在JDK1.8版本中,
对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会用到
红黑树的插入、删除、查找等算法
确定哈希桶数组索引位置确定哈希桶数组索引位置
代码实现:
//方法一:
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 为第一步 取hashCode值
// h ^ (h >>> 16) 为第二步 高位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
下载后可阅读完整内容,剩余5页未读,立即下载
2020-08-02 上传
2023-02-28 上传
2023-12-04 上传
2024-04-30 上传
2023-05-15 上传
2023-06-06 上传
2023-06-06 上传
2024-02-28 上传
2023-07-25 上传

weixin_38732811
- 粉丝: 6
- 资源: 958
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
