第6版计算机网络Transport Layer详解:服务原理与协议解析
版权申诉
161 浏览量
更新于2024-07-03
收藏 9.84MB PPT 举报
在计算机网络第6版的课件中,章节3专注于Transport Layer(传输层)的探讨。Transport Layer是计算机网络体系结构中的关键层次,它的主要目标是确保数据在网络中的可靠传输,同时实现多路复用、分用、流量控制和拥塞控制等重要功能。
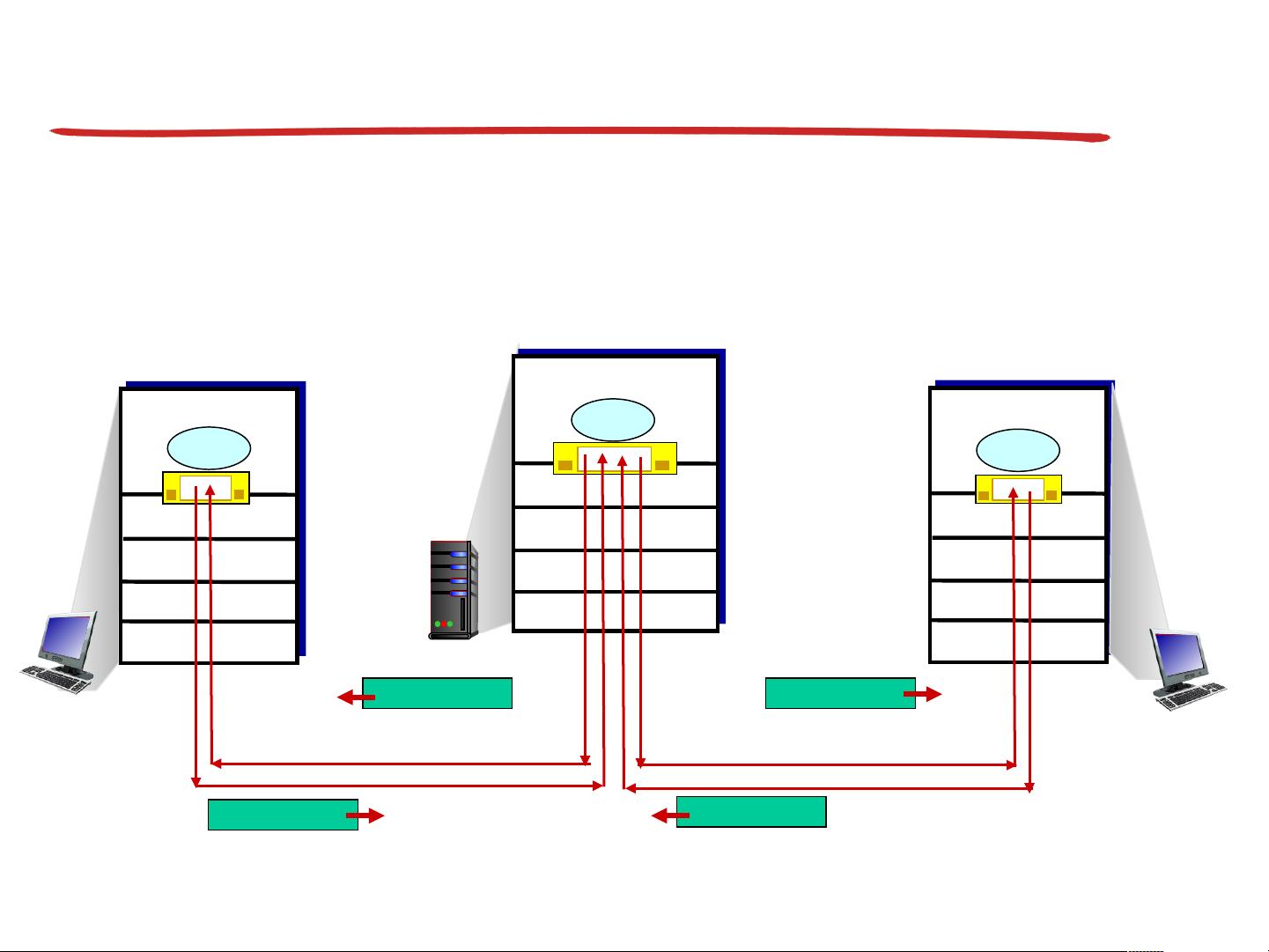
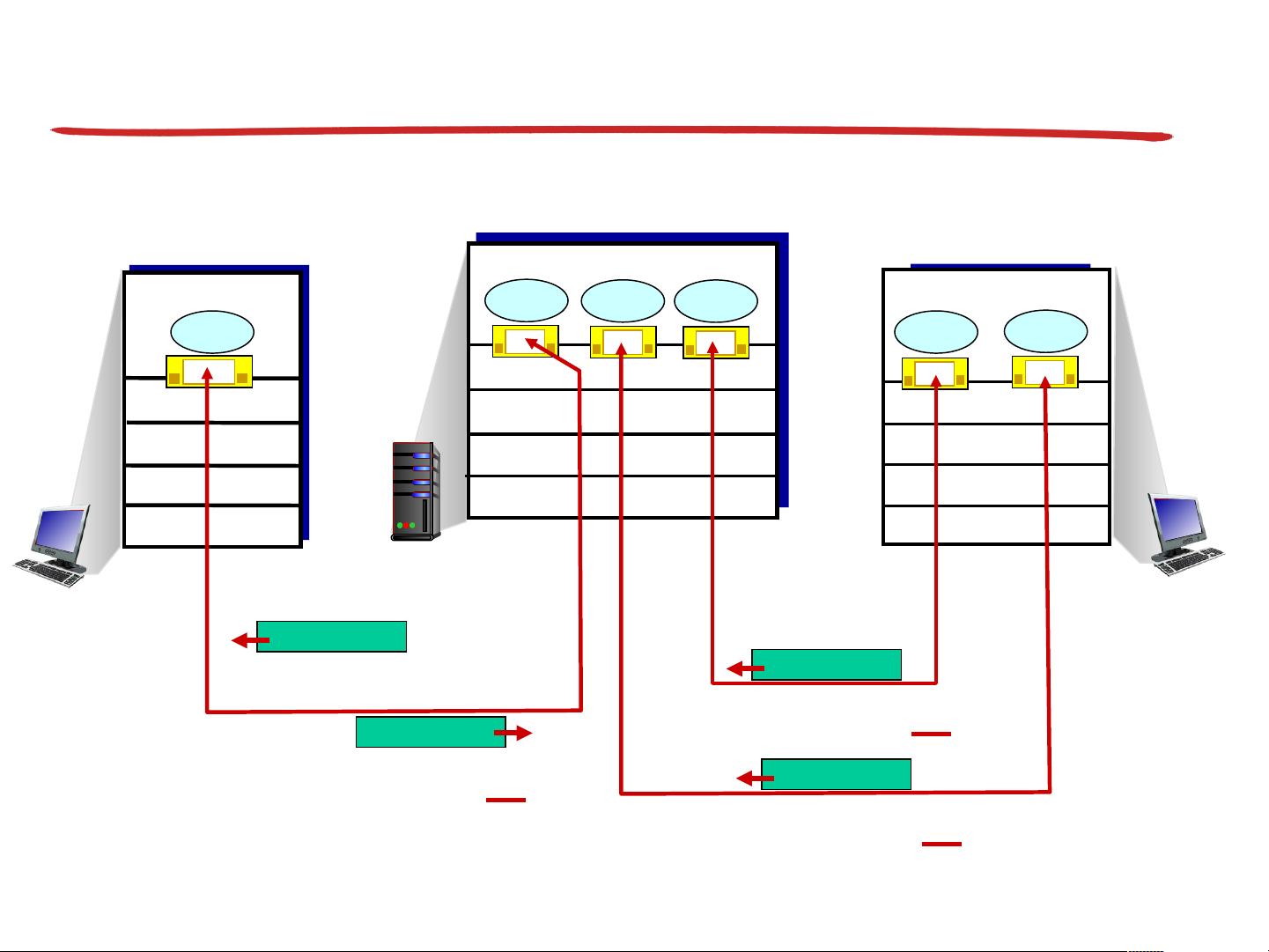
首先,课程强调理解运输层服务背后的基本原理。其中,多路复用(Multiplexing)是指在单个物理连接上同时支持多个独立的通信会话,使得多个应用程序能够共享网络资源,提高效率。相反,分用(Demultiplexing)则是接收端将这些复用的数据流解耦,恢复到各自的源应用程序。
可靠性是Transport Layer的核心关注点之一,它通过错误检测和纠正机制,如TCP(Transmission Control Protocol)中的确认机制,确保数据在传输过程中的完整性。此外,流量控制(Flow Control)是为了避免发送方发送过快,导致接收方无法处理,通常由发送方向接收方发送一个信号,指示其接收能力。
拥塞控制(Congestion Control)是另一个关键概念,用于管理网络中的数据流量,防止过多的数据涌入导致网络拥塞。这通常涉及到发送方根据网络条件调整发送速率,以保持网络的稳定性和效率。
课程还将讲解互联网上的运输层协议,例如TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)。TCP是一种面向连接的协议,提供可靠的数据传输服务,适合需要数据完整性和顺序性的应用;而UDP则是一种无连接的协议,它牺牲了可靠性来换取更高的传输速度,适用于实时应用,如视频流和在线游戏,因为它们可以容忍偶尔的数据丢失。
学习Transport Layer的内容对于理解网络通信的高效和可靠至关重要,无论是设计高效的网络应用还是优化网络性能,掌握这一层次的功能和协议都是必不可少的。在使用这些课件时,请确保尊重作者的版权要求,提及其来源,并在必要时注明改编或引用。
&"
&
DatagramSocket serverSocket
= new DatagramSocket
(6428);
3
)3
P3
3
)3
P1
3
)3
P4
DatagramSocket
mySocket1 = new
DatagramSocket
(5775);
DatagramSocket
mySocket2 = new
DatagramSocket
(9157);
"<01
"/ :
"/ :
"<01
"@
"@
"@
"@

剩余63页未读,继续阅读
2023-05-05 上传
2023-07-13 上传
2023-06-02 上传
2023-06-02 上传
2023-06-02 上传
2023-05-25 上传
2023-06-10 上传
2023-05-05 上传

wxg520cxl
- 粉丝: 24
- 资源: 3万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
