词向量表示与 Bag of Words 模型
需积分: 0 45 浏览量
更新于2024-07-01
收藏 4.56MB PDF 举报
"词向量1"
本文主要探讨了在自然语言处理中,如何有效地表示词汇,特别是针对词向量的几种方法。首先介绍了最简单的词表示方式——one-hot编码,以及其存在的问题,如无法表达单词间的语义关系以及高维度导致的存储和计算效率低下。接着,提到了BOW(Bag of Words)模型,它忽略了词序信息,但简化了文档的表示。
在向量空间模型(VSM)中,文档被表示为一个向量,其中每个单词对应一个维度。文档-单词矩阵用于记录每个文档中每个单词的出现情况,初始版本仅记录单词是否存在,后来改进为考虑单词出现的频率,以赋予不同权重。这里提到了两种常见的权重计算方法:一是词频(Term Frequency, TF),直接用单词在文档中的出现次数作为权重;二是TF-IDF(Term Frequency-Inverse Document Frequency),通过结合词频和逆文档频率来降低常见词汇的重要性。
TF-IDF的计算公式为`TF-IDF = TF * log(总文档数 / (含有该词的文档数 + 1))`,它考虑了单词在文档中出现的频率和在整个语料库中的普遍性。更高的TF-IDF值通常意味着单词对文档的特异性更高。
词向量的目的是捕捉词汇的语义和语法特性,以便于计算相似度和进行各种自然语言处理任务。传统的one-hot编码和BOW模型虽然简单,但在理解和处理语言的复杂性上存在局限。为了解决这些问题,后续引入了如Word2Vec、GloVe等词嵌入技术,它们能够学习到每个词的低维连续向量表示,使得相似的词汇在向量空间中具有相近的距离。
Word2Vec是一种常用的方法,包括CBOW(Continuous Bag of Words)和Skip-gram两种模型。CBOW通过上下文词来预测目标词,而Skip-gram则是反过来,通过目标词来预测上下文词。这些模型通过神经网络训练,能够在向量空间中捕获词汇的上下文信息,从而实现语义表示。
GloVe(Global Vectors for Word Representation)则采用统计方法,基于全局词共现矩阵来学习词向量,同时考虑了全局统计信息和局部上下文信息,能够平衡稀疏性和深度学习模型的训练效率。
词向量技术是自然语言处理领域的重要工具,通过学习得到的词向量可以用来执行诸如情感分析、语义相似度计算、机器翻译等多种任务。随着深度学习的发展,词向量的表示能力也在不断进化,为理解文本数据提供了强大支持。

2022/4/27 8_word_representation
huaxiaozhuan.com/深度学习/chapters/8_word_representation.html 7/38
根据:
,则有:
。
的物理意义为:词汇表
中所有单词的输出向量的加权和,其权重为
。
4.
考虑到
,则有:
写成矩阵的形式为:
,其中
为克罗内克积。
由于
是 one-hote
编码,所以它只有一个分量非零,因此
只有一行非零,且该非零行就等
于
。因此得到更新方程:
其中
为
非零分量对应的
中的行,而
的其它行在本次更新中都保持不变。
5.
考虑更新
第
行的第
列,则:
当
时,
趋近于
0
,则更新的幅度将非常微小。
当
与
差距越大,
绝对值越大,
则更新的幅度越大。
6.
当给定许多训练样本(每个样本由两个单词组成),上述更新不断进行,更新的效果在不断积累。
根据单词的共现结果,输出向量与输入向量相互作用并达到平衡。
输出向量
的更新依赖于输入向量
:
。
这里隐向量
等于输入向量
。
输入向量
的更新依赖于输出向量
:
。
这里
为词汇表
中所有单词的输出向量的加权和,其权重为
。
平衡的速度与效果取决于单词的共现分布,以及学习率。
3.1.3
多个单词上下文
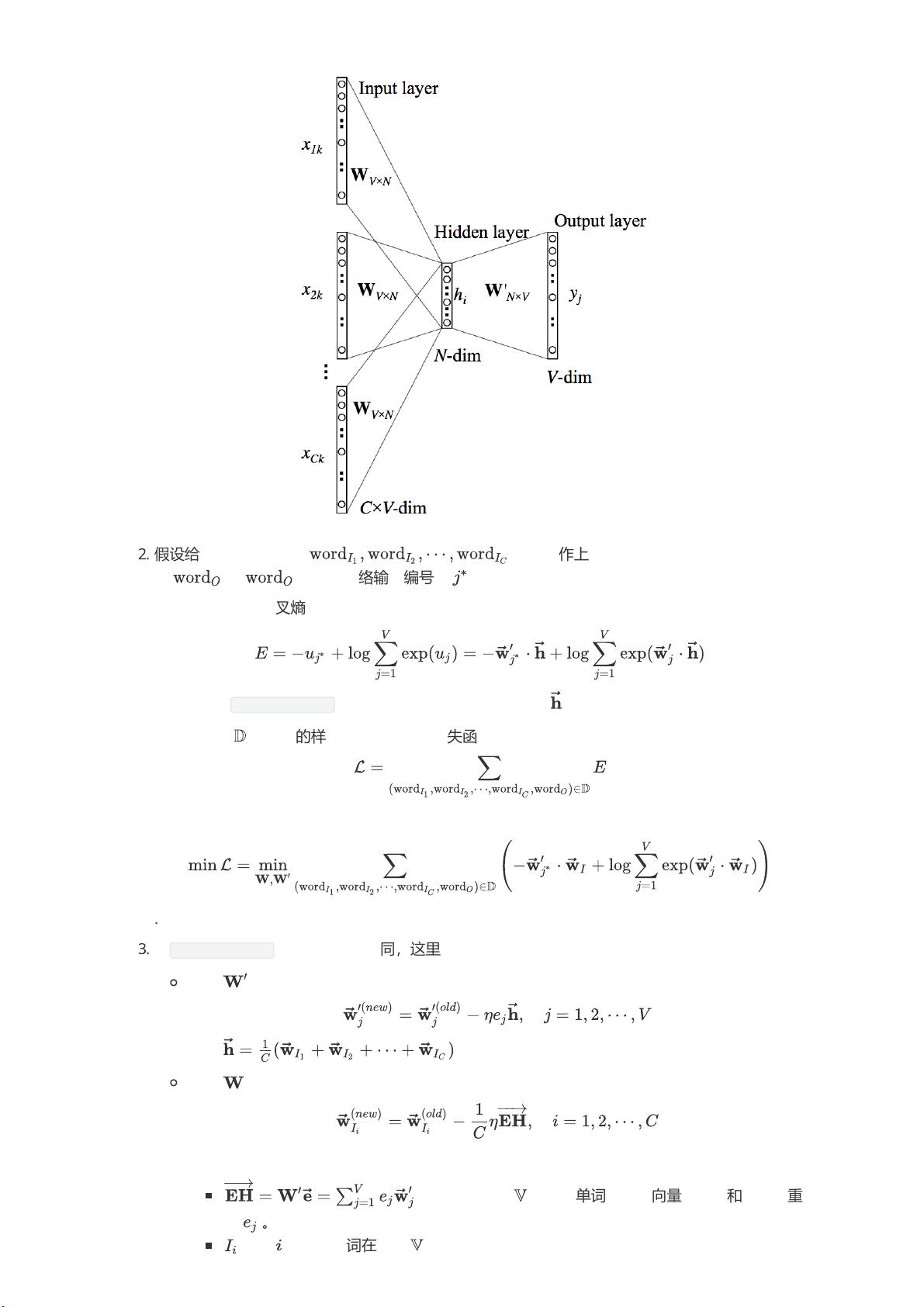
1.
考虑输入为目标单词前后的多个单词(这些单词作为输出的上下文),输入为
个单词:
。对于每个输入单词,其权重矩阵都为
,这称作权重共享。这里的权重共享隐
含着:每个单词的表达是固定的、唯一的,与它的上下文无关。
隐向量为所有输入单词映射结果的均值:
其中:
表示第
个输入单词在词汇表
中的编号,
为矩阵
的第
行,它是对应输入单词
的输入向量。
剩余37页未读,继续阅读
2023-05-31 上传
2023-08-15 上传
2023-05-28 上传
2023-06-03 上传
2023-09-08 上传
2023-05-20 上传
2023-05-31 上传

XU美伢
- 粉丝: 112
- 资源: 341
 我的内容管理
展开
我的内容管理
展开







最新资源
- Lombok 快速入门与注解详解
- SpringSecurity实战:声明式安全控制框架解析
- XML基础教程:从数据传输到存储解析
- Matlab实现图像空间平移与镜像变换示例
- Python流程控制与运算符详解
- Python基础:类型转换与循环语句
- 辰科CD-6024-4控制器说明书:LED亮度调节与触发功能解析
- AE particular插件全面解析:英汉对照与关键参数
- Shell脚本实践:创建tar包、字符串累加与简易运算器
- TMS320F28335:浮点处理器与ADC详解
- 互联网基础与结构解析:从ARPANET到多层次ISP
- Redhat系统中构建与Windows共享的Samba服务器实战
- microPython编程指南:从入门到实践
- 数据结构实验:顺序构建并遍历链表
- NVIDIA TX2系统安装与恢复指南
- C语言实现贪吃蛇游戏基础代码
