改进EAST算法在文本检测中的应用与优势
版权申诉
55 浏览量
更新于2024-06-14
收藏 645KB DOCX 举报
"基于改进EAST算法的文本检测文档详细探讨了EAST算法及其改进,应用于文本检测领域,尤其在图像大数据时代的文本信息提取中具有重要意义。文档内容涵盖了深度学习在文本定位和识别中的作用,以及EAST算法的原理和优势。"
在当前的图像处理领域,文本检测和提取是一项至关重要的任务,尤其是在海量图像数据中寻找关键信息。深度学习技术的发展为解决这一问题提供了强大的工具。EAST(Efficient and Accurate Scene Text Detector)算法是其中的佼佼者,由旷视科技在2017年的CVPR会议上提出,旨在提高文本检测的效率和准确性。
EAST算法的核心在于其简洁的设计,它摒弃了传统多阶段、多组件的检测方法,转而采用全卷积神经网络(FCN)直接预测文本的几何属性。这一改变减少了计算复杂性,提高了运行速度。算法能够预测文本的倾斜角度和多边形边界,使得文本检测更为精确,特别是在处理复杂场景时。
文本检测通常被分解为两个主要步骤:文本定位和文本识别。文本定位算法,如EAST,首先确定文本在图像中的位置,创建出边界框。这个过程是文本识别的前提,因为识别算法需要知道文本的具体位置才能进行转录。EAST通过FCN网络生成字符级或文本行的预测,随后利用非极大抑制(NMS)来去除重复的检测结果,进一步优化边界框。
文本识别阶段则是在定位结果的基础上,使用端到端的模型将检测到的文本区域转化为可读的文本。这个过程可以借助循环神经网络(RNN)或者更现代的Transformer结构,将图像中的像素序列转化为字符序列。
EAST算法的优势在于其高效性和准确性,它在多个公开数据集,如ICDAR2015,上达到了较高的F值(0.782)和快速的帧处理速率(13.2fps),展示了在实际应用中的可行性。然而,任何算法都有其局限性,EAST可能在非常复杂或者低质量的图像中表现不佳,这就需要进一步的改进和优化,比如引入更复杂的模型结构或使用数据增强技术。
通过对EAST算法的改进和应用,可以更好地适应不同场景下的文本检测需求,提高整体系统性能,尤其是在实时性和准确度之间找到更好的平衡点。这种改进可以包括优化网络架构、引入更先进的训练策略或是结合其他检测技术,以应对更加多样化的图像文本检测挑战。
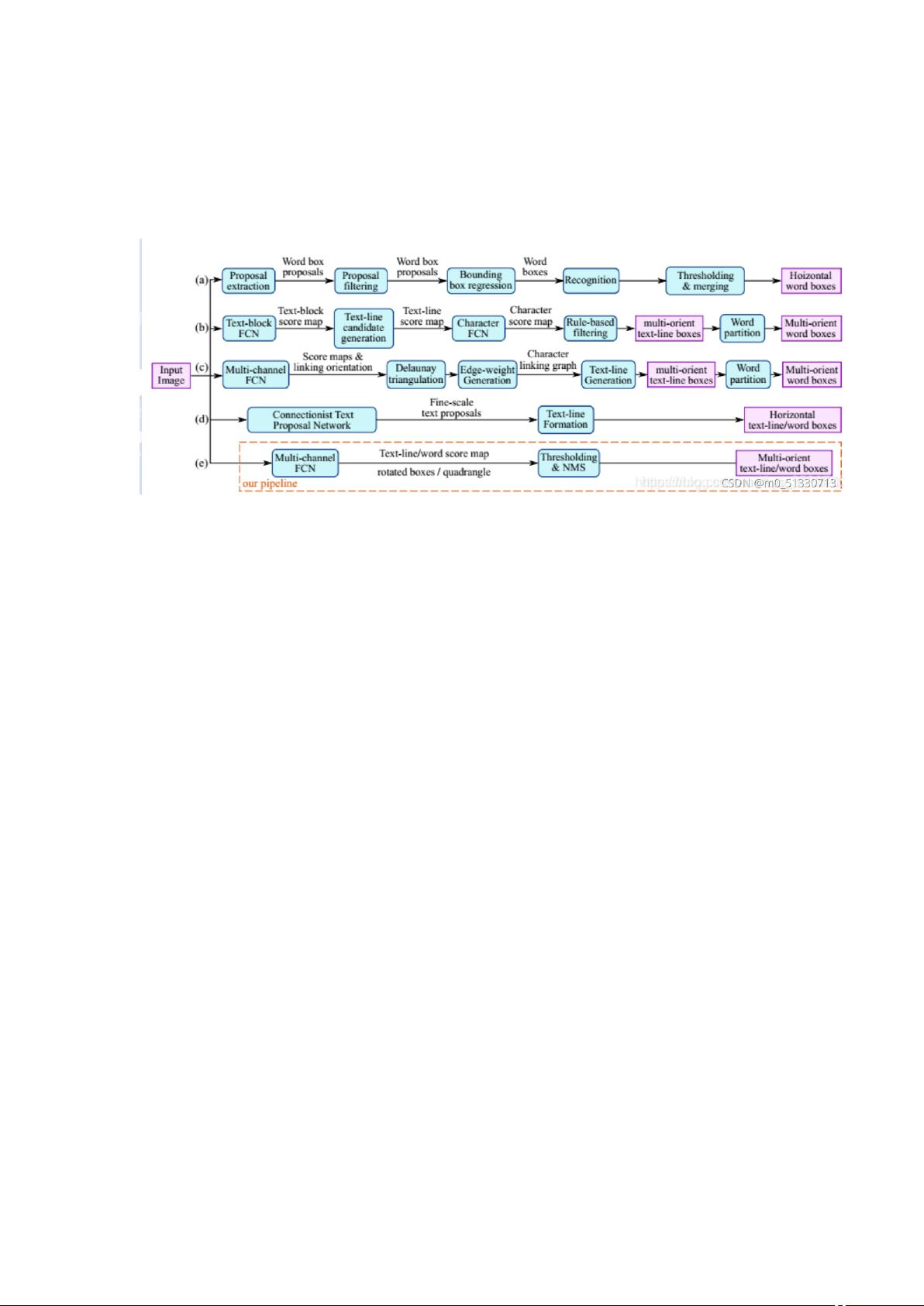
或者矩形框。
3. 在精度和速度都优于当时其他的方法。
那么该算法的优势在于消除传统算法中间冗余而又慢速的步骤,只包
含两个主要流程: 一是使用全卷积网络( fully convolutional
networks,FCN) 模型直接生成单词或文本行级别预测; 二是将生成的
文本预测( 可以是旋转的矩形或四边形) 输入到非极大值抑制
NMS( non-maximum suppression) 中以产生最终结果。而传统的文本
检测方法和一些基于深度神经 网络的文本定位方法由若干组件构成,
包含多个步骤且在训练时需要对其分别进行调优,耗费时间较多。
我打算先介绍一下 EAST 算法,然后再详细讲述基于 EAST 算法的改
进。
https://github.com/argman/EAST
这是原作者参与的一份 tensorflow 版本代码,网上还有其他的实现。
剩余17页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-06-30 上传
2022-06-01 上传
2022-06-26 上传
2022-12-01 上传
2021-10-01 上传

ohmygodvv
- 粉丝: 507
- 资源: 4811
 我的内容管理
展开
我的内容管理
展开







