

+v:mala2277获取更多论
文
×
i
−
1
M
−
i
−
1
i
−
1
D
−
D
transformer
层。
可以作为进一步优化的良好起点我们建议读者
参阅
Chen et al.
(
2021
)以了解有关宽度扩展
的 更 多 详 细 信 息 。 不 同 于
Chen et al.
(2021),我们在初始化期间将随机噪声δ
i
额
外引入
到Wj的新复制参数中。这些轻微的噪音
会破坏复制后的对称性,加速后期的预训练。
深度扩展。对于深度扩展,复杂的工作通常通
过 参数复制 将 所 有 原 始 PLM 层 堆 叠 成 2 层
(
Gong et al.
,
2019
)。这种初始化被证明可
以提高训练效率。
然而,上述
层堆叠
方法
将放大的
PLM M
D
的层的数量限制
为原始
PLM
M
i
-1
的层的数量的整数倍
,这
对于实际使用来说是不灵活的。
为了提高
扩展的灵活性,使得
i
-1
可以扩展为任意层
数,
我们提出了一种新的
层插入
方法来
构造
具有L
+
L
J
层的新的PLM M D 1,其中
训练阶段。
3.3
预先训练的域提示
我们不需要为每个领域训练一个单独的模型,
而是希望一个紧凑的
PLM
来整合来自所有来
源的知识。当面对来自特定领域的下游任务
时,PLM需要展示在预培训期间学到的适当
知识。为了促进预培训期间的知识获取和微调
期间的知识暴露软提示已被证明是优秀的任务
指示符(
Qin et al.
,
2021 b
),并具有非平凡
的任务之间的可转移性(苏等。,
2021
年)。
具体来说,在预训练期间,为了理清来自
不同来源的知识,我们在输入中植入了一个
软提示令牌,以引导
PLM
学习哪种知识域
i
的
prompt是一个可调向量p
i
。我们准备
在原始令牌嵌入H
0
之前的p
i
=
1 ≤L
J
我
≤
L
。具体来说,我们随机选择
L
J
{
h
0
,
. . .
,
h
0
}
对于输入x∈ D
i
,得到
M中的图层
1
,复制每个层
|x|
i
−
1
修改的输入H
0
=
{
p
i
;
h
0
,
. . .
,
h
0
}
,即
并在原始层之前
/
之后插入复制层 我们根据
经验发现,将复制的层插入到其他位置会导
致性能下降,原因是它会违反原始层序列的
处理顺序
并破坏
PLM
的原始功能
。 在每个扩
展阶段,当有新的数据出现时,由于不同的
层有不同的功能
,我们总是选择那些以前
没
有被复制的层来帮助
PLM
全面开发
,而不仅
仅是开发
某种功能。 由于宽度
扩展和深度扩
展是相互兼容
的,我们同时对它们进行扩
展,构造了一个扩展模型
M
WD
,它继承了参
数中包含的M
i
−1
的知识。
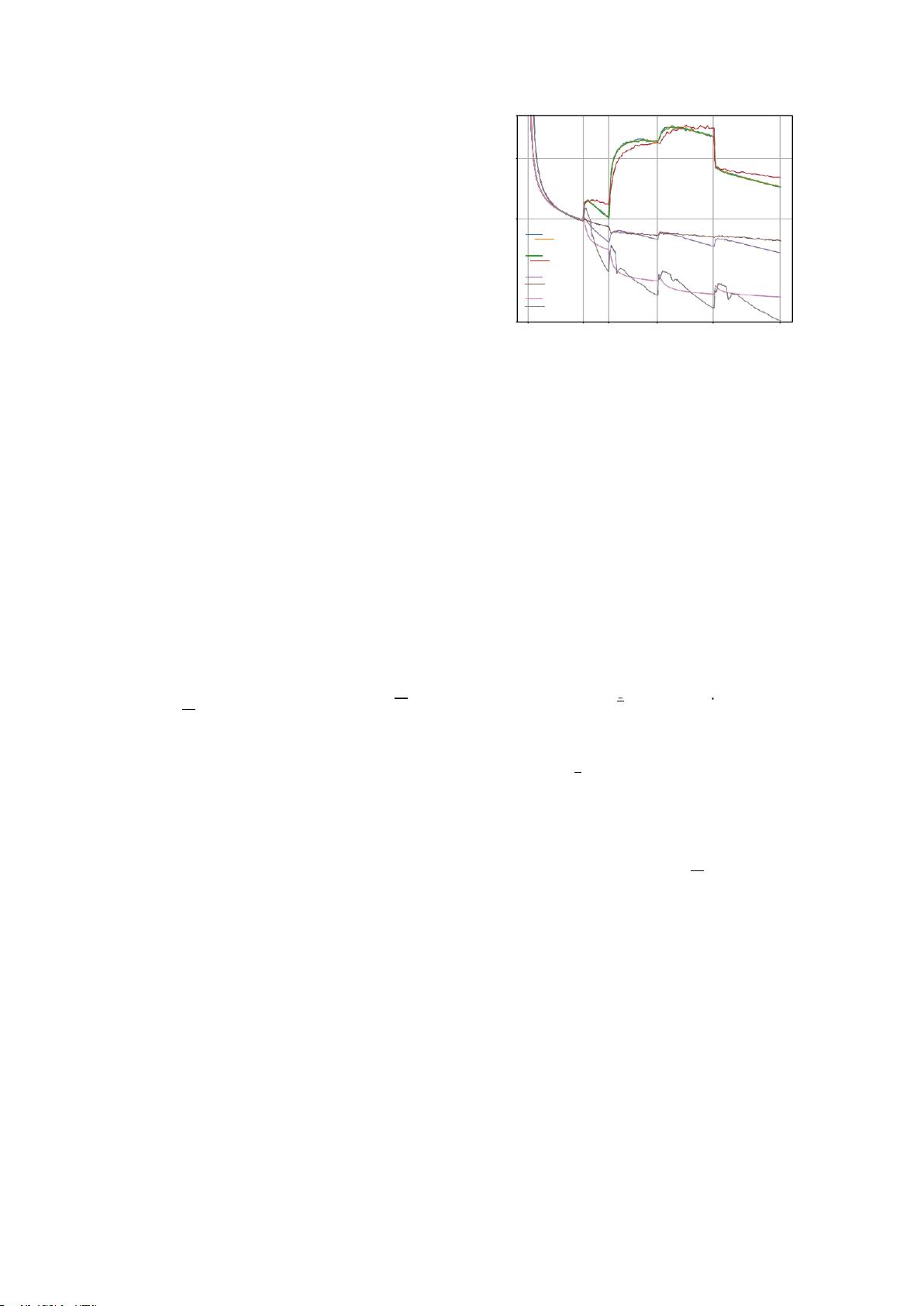
功能恢复热身。由于上述模型扩展不能保证
精确的功能保持, 结果 在功能丢失和性能
下降的情况下,我们在
然后由所有的
T1
处理
|X|
每个
在预训练期间
,
在微调过程中,当在前面看到
的类似数据域上应用
PLM
时,我们可以利用
经过训练的域提示并将其置于输入之前 下游
数据。通过这种方式,我们手动操作PLM,
以激发在预培训期间学到的最
4
实验
4.1
实验环境
数据流。我们模拟了顺序收集来自5个域的流
数据的场景,即,
WIKIPEDIA
和
BOOK C ORPUS
(WB)的串联(Zhu et al. ,2015)、NEWS A
RTICLES
(
N S
) (
Zellers et al.
,
2019
) ,
A
MA-ZON R EVIEWS ( R EV ) ( He and
McAuley
,
2016
),
B IOMEDICAL P APERS
(
B
IO)(Lo et al. ,2020)和C OMPUTER S CIENCE
P APERS
(
CS
)(
Lo et al.
、
子
i
−
1
2020年)。对于每个语料库D
i
,我们大致采样
以往语料库
i1
保存在内存
恢复在模型扩展过程中丢失的语言能力,这
被称为函数恢复预热(FRW)。预热后,我
们得到
M
WD+
,它成功地继承了来自
M
i
−
1
的知
识,也为接下来的
3400
M
代币,每个代币的数量
i
是
与
BERT
的预训练数据相当(
De-vlinet al.
,
2019
)。此外,考虑到在实践中,存储的费用
远远低于用于预训练的计算资源,我们保持了
相对较大的内存,
剩余25页未读,继续阅读

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- AirKiss技术详解:无线传递信息与智能家居连接
- Hibernate主键生成策略详解
- 操作系统实验:位示图法管理磁盘空闲空间
- JSON详解:数据交换的主流格式
- Win7安装Ubuntu双系统详细指南
- FPGA内部结构与工作原理探索
- 信用评分模型解析:WOE、IV与ROC
- 使用LVS+Keepalived构建高可用负载均衡集群
- 微信小程序驱动餐饮与服装业创新转型:便捷管理与低成本优势
- 机器学习入门指南:从基础到进阶
- 解决Win7 IIS配置错误500.22与0x80070032
- SQL-DFS:优化HDFS小文件存储的解决方案
- Hadoop、Hbase、Spark环境部署与主机配置详解
- Kisso:加密会话Cookie实现的单点登录SSO
- OpenCV读取与拼接多幅图像教程
- QT实战:轻松生成与解析JSON数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


