
programs and even anti-spyware programs are also
installed through exploits.
3. The HoneyMonkey System
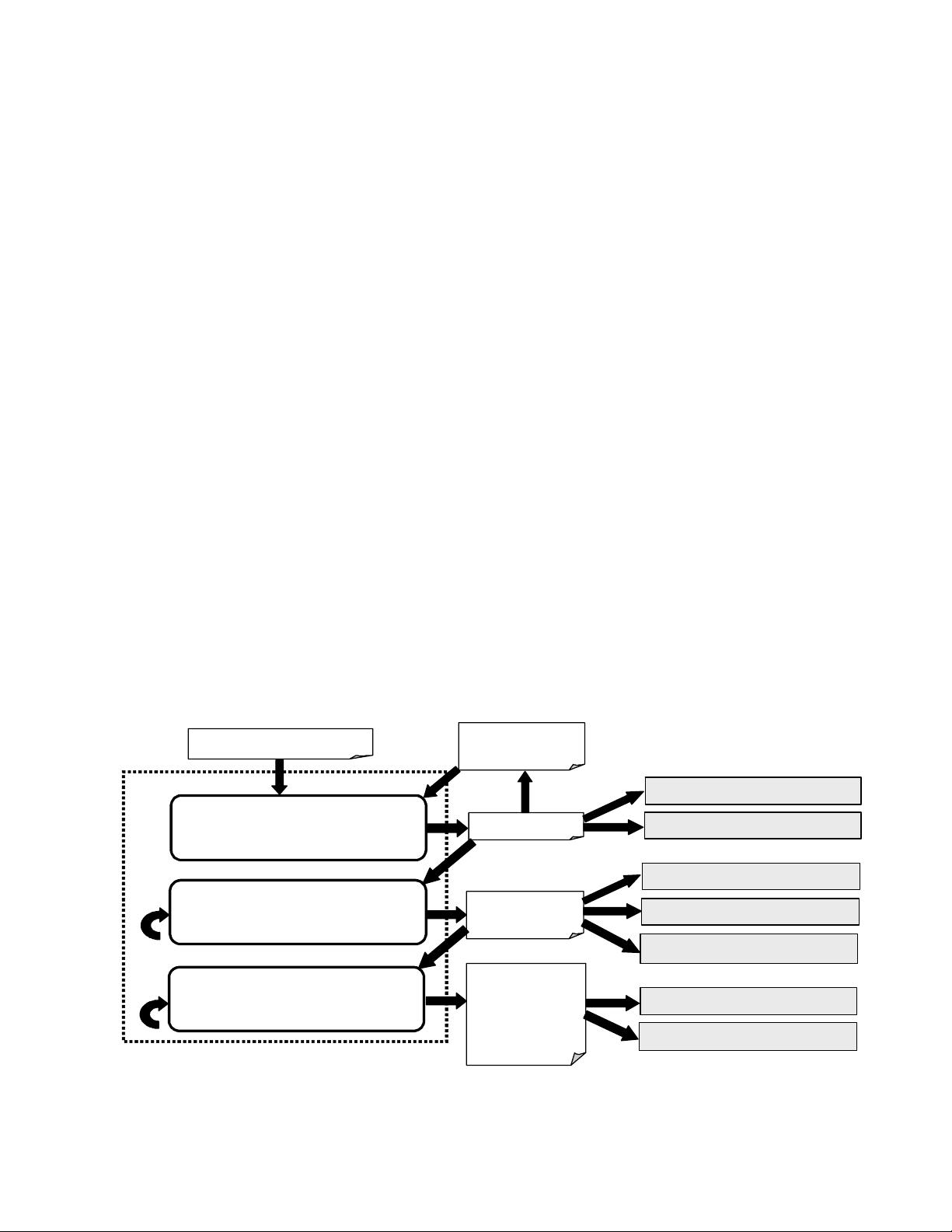
The HoneyMonkey system attempts to automatically
detect and analyze a network of web sites that exploit web
browsers. Figure 2 illustrates the HoneyMonkey Exploit
Detection System, shown inside the dotted square, and the
surrounding Anti-Exploit Process which includes both
automatic and manual components.
3.1. Exploit Detection System
The exploit detection system is the heart of the
HoneyMonkeys design. This system consists of a 3-stage
pipeline of virtual machines. Given a large list of input
URLs with a potentially low exploit-URL density, each
HoneyMonkey in Stage 1 starts with a scalable mode by
visiting N URLs simultaneously inside one unpatched
VM. When the HoneyMonkey detects an exploit, it
switches to the basic, one-URL-per-VM mode to re-test
each of the N suspects in order to determine which ones
are exploit URLs.
Stage-2 HoneyMonkeys scan Stage 1 detected
exploit-URLs and perform recursive redirection analysis
to identify all web pages involved in exploit activities and
to determine their relationships. Stage-3 HoneyMonkeys
continuously scan Stage-2 detected exploit-URLs using
(nearly) fully patched VMs in order to detect attacks
exploiting the latest vulnerabilities.
We used a network of 20 machines to produce the
results reported in this paper. Each machine had a CPU
speed between 1.7 and 3.2 GHz, a memory size between
512 MB and 2GB, and was responsible for running one
VM configured with 256 MB to 512MB of RAM. Each
VM supported up to 10 simultaneous browser processes in
the scalable mode, with each process visiting a different
URL. Due to the way HoneyMonkeys detect exploits
(discussed later), there is a trade-off between the scan rate
and the robustness of exploit detection: if the
HoneyMonkey does not wait long enough or if too many
simultaneous browser processes cause excessive
slowdown, some exploit pages may not be able to perform
a detectable attack (e.g., beginning a software
installation).
Through extensive experiments, we determined that a
wait time of two minutes was a good trade-off. Taking
into account the overhead of restarting VMs in a clean
state, each machine was able to scan and analyze between
3,000 to 4,000 URLs per day. We have since improved the
scalability of the system to a scan rate of 8,000 URLs per
day per machine in the scalable mode. (In contrast, the
basic mode scans between 500 and 700 URLs per day per
machine.) We expect that using a more sophisticated VM
platform that enables significantly more VMs per host
machine and faster rollback [VMC+05] would
significantly increase our scalability.
3.1.1. Exploit Detection
Although it is possible to detect browser exploits by
building signature-based detection code for each known
vulnerability or exploit, this approach is manually
intensive. To lower this cost, we take the following black-
Figure 2. HoneyMonkey Exploit Detection System and Anti-Exploit Process
Depth-N crawling
of given URL
List of “interesting URLs”
Exploit URLs
Topology graph
of exploit URLs
Topology graphs
of zero-day or
latest-patched-
vulnerability
exploit URLs
Stage 1: Scalable HoneyMonkey exploit
detection with unpatched virtual
machines without redirection analysis
Stage 2: Basic HoneyMonkey exploit
detection with unpatched virtual
machines with redirection analysis
Stage 3: Basic HoneyMonkey exploit
detection with (nearly) fully patched
virtual machines with redirection analysis
Analysis of exploit URL density
Fix compromised machines
Internet safety enforcement team
Access blocking
Anti-spyware team
Security response center
Browser and other related teams
Redirect
URLs
HoneyMonkey Exploit Detection System
剩余14页未读,继续阅读

duanlei888
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


