Spark MLlib中级考前深度解析:机器学习与DataFrame API详解
需积分: 0 154 浏览量
更新于2024-06-25
收藏 1.45MB PDF 举报
本资源是一份针对大数据应用技术中Spark机器学习库的中级考前辅导材料。主要内容涵盖了MLlib(Spark的早期机器学习库)和Spark ML(Spark 2.0及后续版本的高级API)的区别与特点。
1. SparkMLib介绍:
- MLlib是Apache Spark的一部分,提供了一套可扩展的机器学习工具,主要用于1.2版本之前的Spark版本。它基于RDD(弹性分布式数据集)进行操作,包含了大量的基础机器学习算法,如监督学习(如朴素贝叶斯、K近邻、SVM、决策树、逻辑回归等)、回归算法(如线性回归、逻辑回归、岭回归、Lasso)以及无监督学习(如K-Means聚类、MeanShift、层次聚类等)和关联学习算法(如Apriori、FP-Tree等)。
2. Spark ML发展:
- 从Spark 2.0开始,引入了基于DataFrame的高级API(spark.ml),这是对原始MLlib库的一个重大改进。MLlib逐渐进入了维护模式,不再新增功能,预计在Spark 3.0中会被移除,以支持更现代、高效的数据处理方式。
3. DataFrame API:
- spark.ml的API库主要由Transformer(转换器)、Estimator(预测器)和Pipeline(管道)三个核心组件构成。Transformer用于数据预处理和转换,如特征提取和编码;Estimator是模型的训练器,如LogisticRegression,通过fit()方法训练模型并转化为Transformer;Pipeline则是将多个转换和预测器串联起来形成一个完整的机器学习工作流程,用户可以通过指定一系列阶段来构建复杂的模型。
4. 示例:
- 例如,一个转换器可以接收一个DataFrame,处理特定列(如text列),将其转换为新的特征向量列,然后返回一个新的DataFrame。而Estimator如LogisticRegression,则是在训练数据上学习参数,生成模型,同时也是一个Transformer,可以应用于新的数据。
总结来说,这份资料深入讲解了Spark MLlib与Spark ML在机器学习中的应用,强调了DataFrame API在简化模型构建和提高效率方面的优势。对于准备参加大数据应用技术Spark中级考试的学习者而言,理解和掌握这些知识点是至关重要的,有助于理解和运用Spark进行实际的数据分析和预测任务。
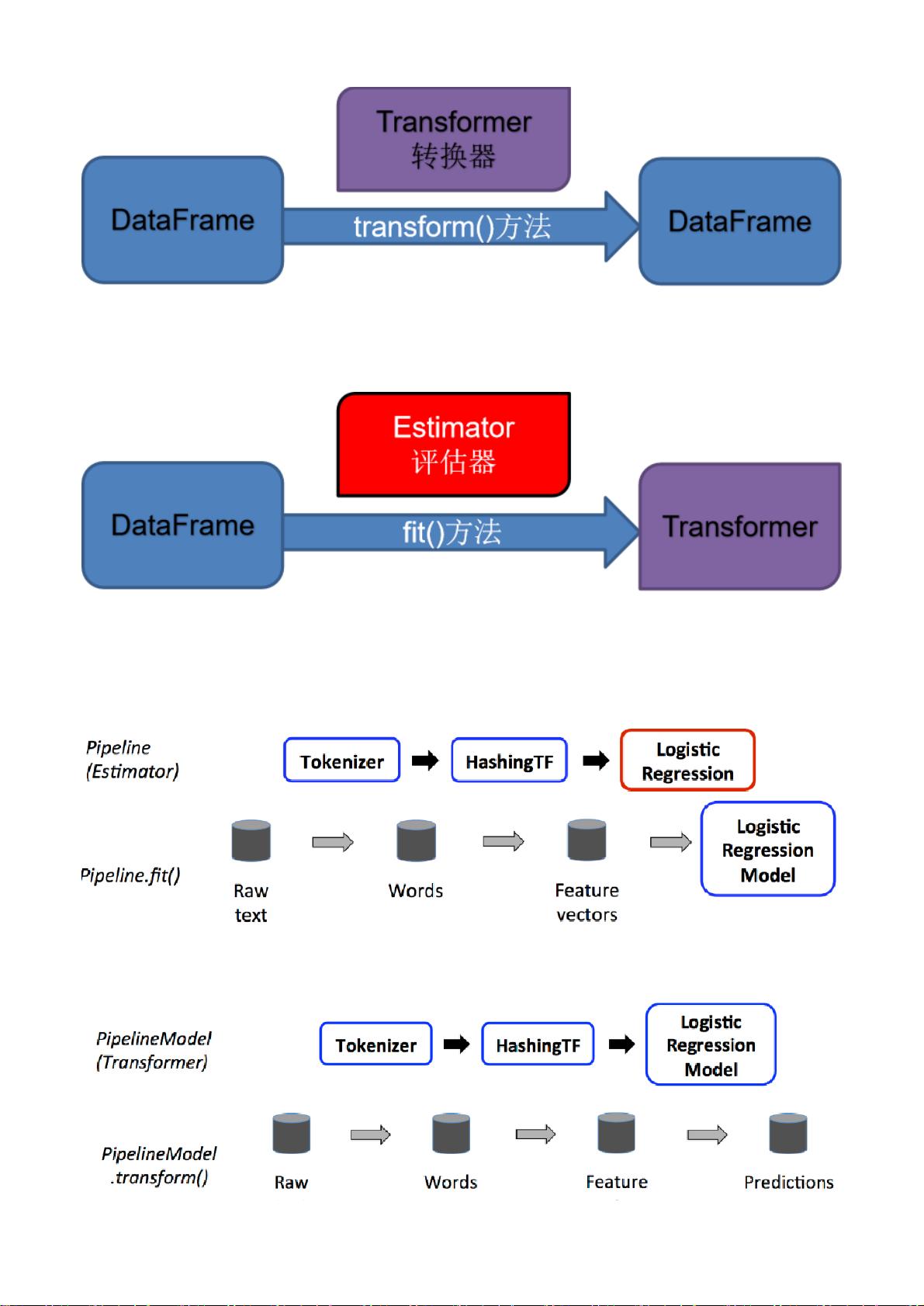
例:一个特征变换器是输入一个DataFrame,读取一列(比如 text),将其映射成一个新列(比如,特征向量),然后
输出一个新的包含这个映射列的DataFrame
预测器是一种算法,可以基于DataFrame产生一个转换器,是学习算法或者其他算法的抽象,用来训练数据。
例:一个机器学习算法是一个Estimator模型学习器,比如这个算法是LogisticRegression,调用fit()方法训练出一
个LogisticRegressionModel,是一个Model,也是一个Transformer。
管道链接多个转换器和预测器生成一个机器学习工作流。管道被指定为一系列阶段,每个阶段是一个转换器或一个预
测器。
上一步骤得到一个文档的模型,用测试数据经过相应处理变成特征向量后输入到模型中,通过预测的准确率来评估
一个模型。
剩余16页未读,继续阅读
2023-05-23 上传
2023-05-23 上传
2018-04-04 上传
2023-06-09 上传
2024-04-10 上传
2023-03-31 上传
2023-06-12 上传
2023-04-06 上传
2023-02-13 上传
2023-06-13 上传

音九尘
- 粉丝: 8
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
