SVD驱动的轻量化神经网络知识蒸馏提升性能
16 浏览量
更新于2024-06-20
收藏 1.31MB PDF 举报
本文主要探讨了"基于奇异值分解的神经网络知识蒸馏方法"。在当前深度学习领域,分布式神经网络(DNN)因其强大的计算能力和广泛的应用在图像分类、识别等方面表现出色。然而,DNN在移动设备或嵌入式系统上的部署面临存储和计算资源限制的问题,这促使研究人员寻求更轻量级的模型来降低存储需求和计算成本。
传统的解决策略之一是知识蒸馏,由Hinton等人首次提出,通过构建师生网络(Teacher-Student, T-S)架构,将大型复杂网络(Teacher, T-DNN)的知识传授给小型、效率更高的网络(Student, S-DNN)。这种方法旨在提升小规模网络的性能,使其在资源受限的环境中也能达到接近大模型的效果。
现有的T-S-DNN虽然有所改善,但仍存在一定的局限性,特别是在知识转移的效率和质量上。本文作者针对这个问题,提出了一种创新的方法,即利用奇异值分解(SVD)来增强知识的提炼和传递过程。SVD作为一种有效的矩阵分解技术,能够提取数据的主要特征,这对于保留和压缩教师网络的关键信息至关重要。
作者将知识转移视为一个自我监督任务,并设计了一种策略,使得S-DNN能持续从T-DNN中接收指导信息。这样做的目的是确保学生网络能够更有效地学习和模仿教师网络的行为,从而提高知识转移的精准性和有效性。
实验结果显示,采用这种方法的S-DNN在保持计算成本仅为T-DNN的五分之一的情况下,其性能相比于T-DNN提高了1.1%的分类精度。在计算成本相同时,与最先进的蒸馏驱动的S-DNN相比,该方法的S-DNN还能展现出1.79%的优势,进一步证实了其在轻量化学习中的优越性。
文章提供的GitHub代码链接(https://github.com/sseung0703/SSKD)可供读者参考和进一步研究。整个工作不仅关注了深度学习模型的效率优化,还涵盖了矩阵分解技术在知识转移中的应用,对于理解和改进深度学习模型在资源受限环境下的性能具有重要意义。
4
Seung Hyun Lee,Dae Ha Kim,Byung Cheol
Song
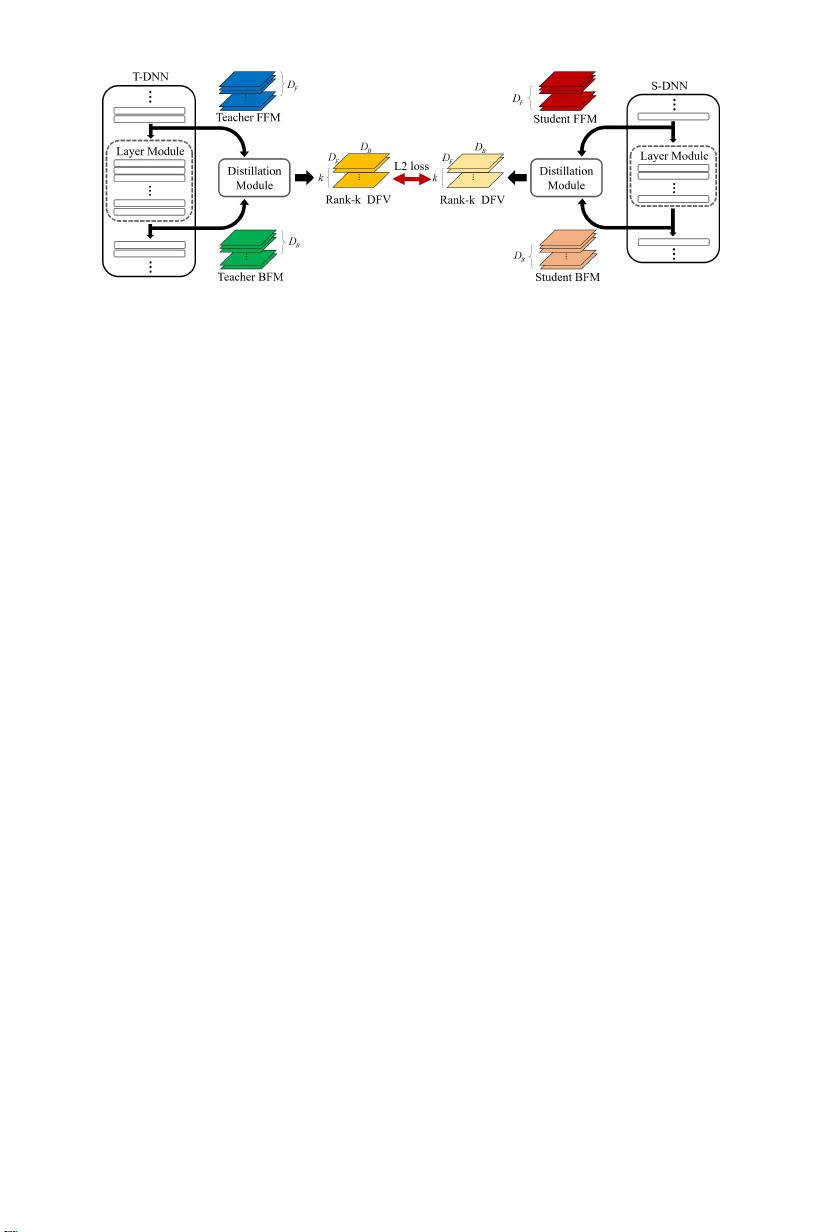
图1:提出了基于知识蒸馏的网络的概念
3
方法
本节详细介绍了拟议的知识转移方法。受[10]思想的启发,我们推导
出从T-DNN中提取的两个特征图之间的相关性,并将其作为知识进行
传输。图1示出了所提出的基于知识蒸馏的网络。首先,取决于目
的,T-DNN和S-DNN都 由预 定 卷 积 层 和 全 连 接 层组 成 例 如 , VGG
[19],MobileNet [7],ResNext [5]等。可以作为DNN。然后,为了提取
每个DNN固有的特征图特征,我们在DNN中指定两个特定的层点,并
感测相应的两个特征图。两点之间的层被定义为层模块。在层模块的
输入处感测的特征图被称为前端特征图(FFM),并且在输出处感测
的特征图被称为后端特征图(BFM)。例如,在MobileNet中,层模块
可以由几个深度可分离卷积组成。设FFM和BFM的深度分别为
D
F
和
D
B
。另一方面,可以在每个DNN中定义若干非重叠层模块以用于鲁
棒蒸馏。在本文中,每个DNN中的层模块的最大数量是
G
。
现在我们可以通过蒸馏模块得到某一层模块的FFM和BFM之间的
相关性。蒸馏模块从FFM和BFM两个输入输出具有
k
×
DF
×
DB
大小
的蒸
馏特征向量(DFV)。参见第第3.1条
最后,我们提出了一种新的训练机制,使得来自T-DNN的知识不会在
第二阶段消失,即,主任务学习过程我们改进了[8]中提出的自监督学
习,以实现更有效的知识转移。参见第3.2.
3.1
拟定蒸馏模块
一般来说,DNN通过多个层生成特征图以适应给定的任务。在[10]的
蒸馏方法中,首先将从DNN获得的特征图之间的相关性定义为知识。
建议的方法也接受
剩余17页未读,继续阅读
2022-09-23 上传
2020-08-05 上传
2023-05-19 上传
2023-05-30 上传
2023-05-31 上传
2023-05-13 上传
2023-09-28 上传
2023-05-27 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
