
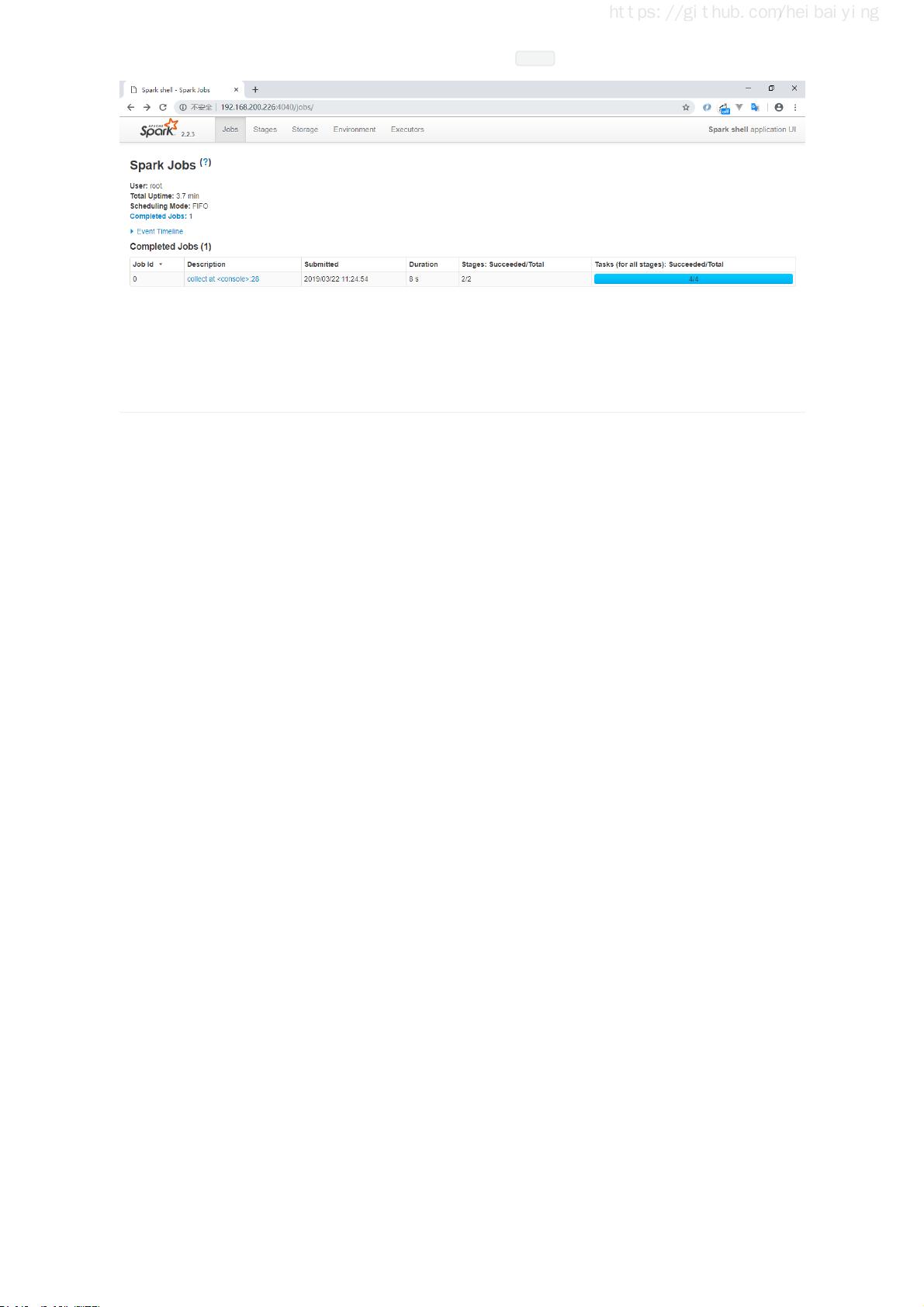
同时还可以通过 Web UI 查看作业的执行情况,访问端口为 4040 :
三、Scala开发环境配置
Spark 是基于 Scala 语言进行开发的,分别提供了基于 Scala、Java、Python 语言的 API,如果你想使
用 Scala 语言进行开发,则需要搭建 Scala 语言的开发环境。
3.1 前置条件
Scala 的运行依赖于 JDK,所以需要你本机有安装对应版本的 JDK,最新的 Scala 2.12.x 需要 JDK
1.8+。
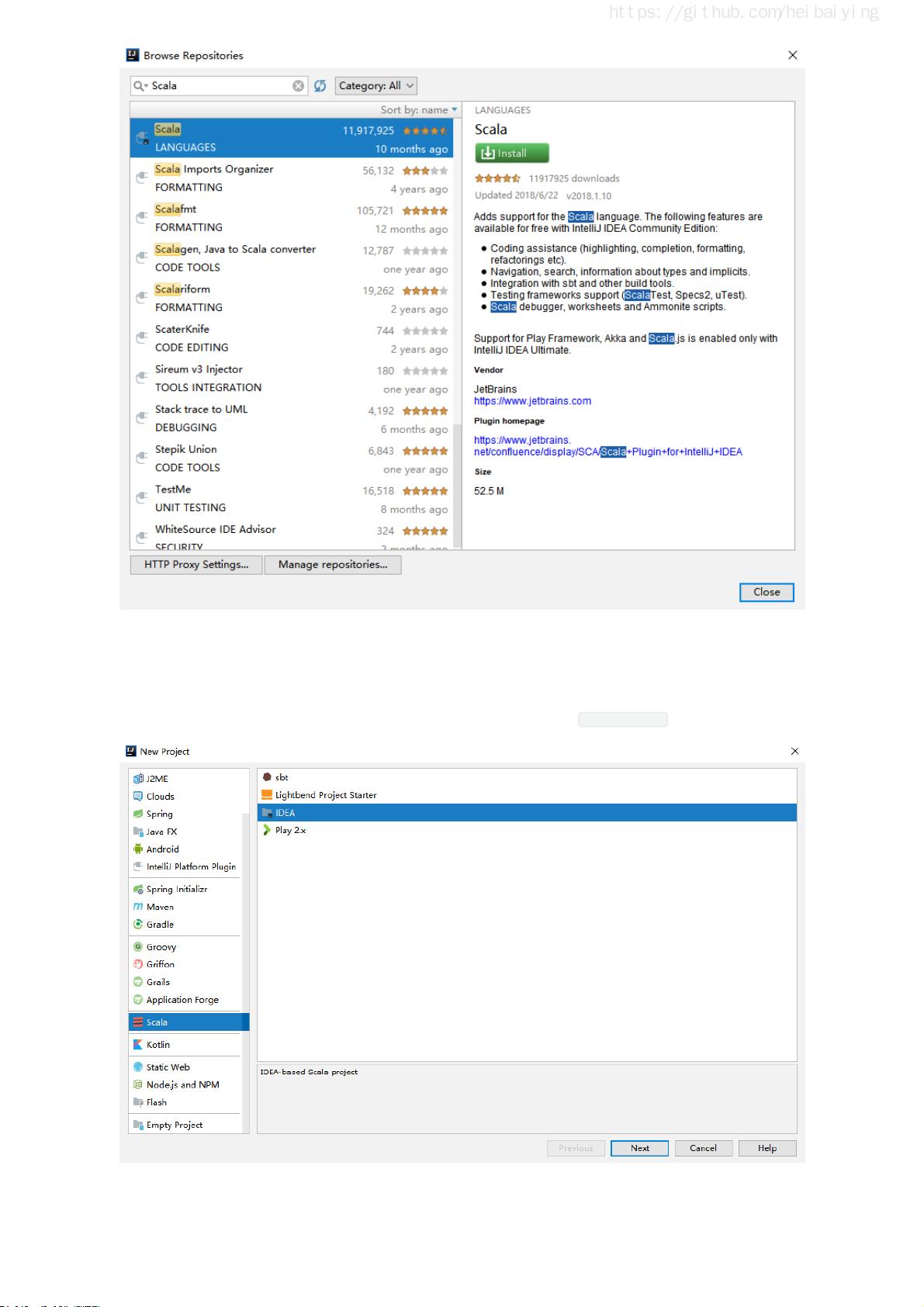
3.2 安装Scala插件
IDEA 默认不支持 Scala 语言的开发,需要通过插件进行扩展。打开 IDEA,依次点击 File =>
settings=> plugins 选项卡,搜索 Scala 插件 (如下图)。找到插件后进行安装,并重启 IDEA 使得安装
生效。
https://github.com/heibaiying
剩余37页未读,继续阅读

zhb31415926
- 粉丝: 12
- 资源: 49
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


