YARN资源调度器详解:CapacityScheduler与FairScheduler策略对比
需积分: 0 148 浏览量
更新于2024-08-04
收藏 546KB PDF 举报
在大数据时代,Hadoop框架中的YARN(Yet Another Resource Negotiator,另一种资源管理器)作为核心组件之一,承担着分布式计算系统中资源的有效管理和调度。本文将深入探讨YARN的资源调度器,特别是CapacityScheduler和FairScheduler这两种常见的调度策略。
首先,YARN资源调度器本质上是一个事件驱动的处理器,它处理来自外部的六种事件类型,包括NODE_REMOVED(节点移除)、NODE_ADDED(节点增加)、APPLICATION_ADDED(应用添加)、APPLICATION_REMOVED(应用移除)、CONTAINER_EXPIRED(容器过期)以及NODE_UPDATE(节点状态更新)。每当发生这些事件,调度器会相应地调整资源分配,确保系统的动态响应能力。
YARN采用双层资源调度模型:首先是全局的资源调度器,即RM中的调度器,负责分配资源给应用程序的Application Master(AM);然后,AM再与NodeManager(NM)进行交互,将Container资源分配给具体的任务。这种设计允许YARN在全局层面优化资源分配,同时保持任务级的灵活性。
CapacityScheduler是一种基于容量分配的调度策略,它根据预定义的资源配额来决定各个用户或队列的资源份额。用户或队列的资源分配基于它们预先设定的容量比例,有助于保证公平性和稳定性。然而,这可能导致长尾效应,即某些用户或队列可能长时间等待资源。
相比之下,FairScheduler旨在提供更细粒度的资源公平性。它根据每个用户的使用历史和当前需求动态调整资源分配,确保每个用户都能获得与其使用情况相匹配的资源。这种调度器更加注重实时性和响应用户行为,但可能会牺牲全局优化。
在配置YARN时,理解这些调度器的工作原理和调整参数至关重要。例如,了解如何设置队列优先级、最大和最小资源限制,以及如何监控和调整资源分配策略,都是提升YARN性能和资源利用率的关键。此外,熟悉常用的命令行工具如`yarn.scheduler.capacity.root.QueueA.capacity`和`yarn.nodemanager.resource.cpu-vcores`,可以帮助管理员更好地管理和优化资源。
总结来说,YARN资源调度器是Hadoop生态系统中不可或缺的部分,理解其工作原理、调度策略以及如何配置,对于有效利用大数据资源、提高系统效率和优化用户体验具有重要意义。随着大数据和AI技术的发展,对YARN的理解和优化将继续成为数据科学家和工程师的重要技能。
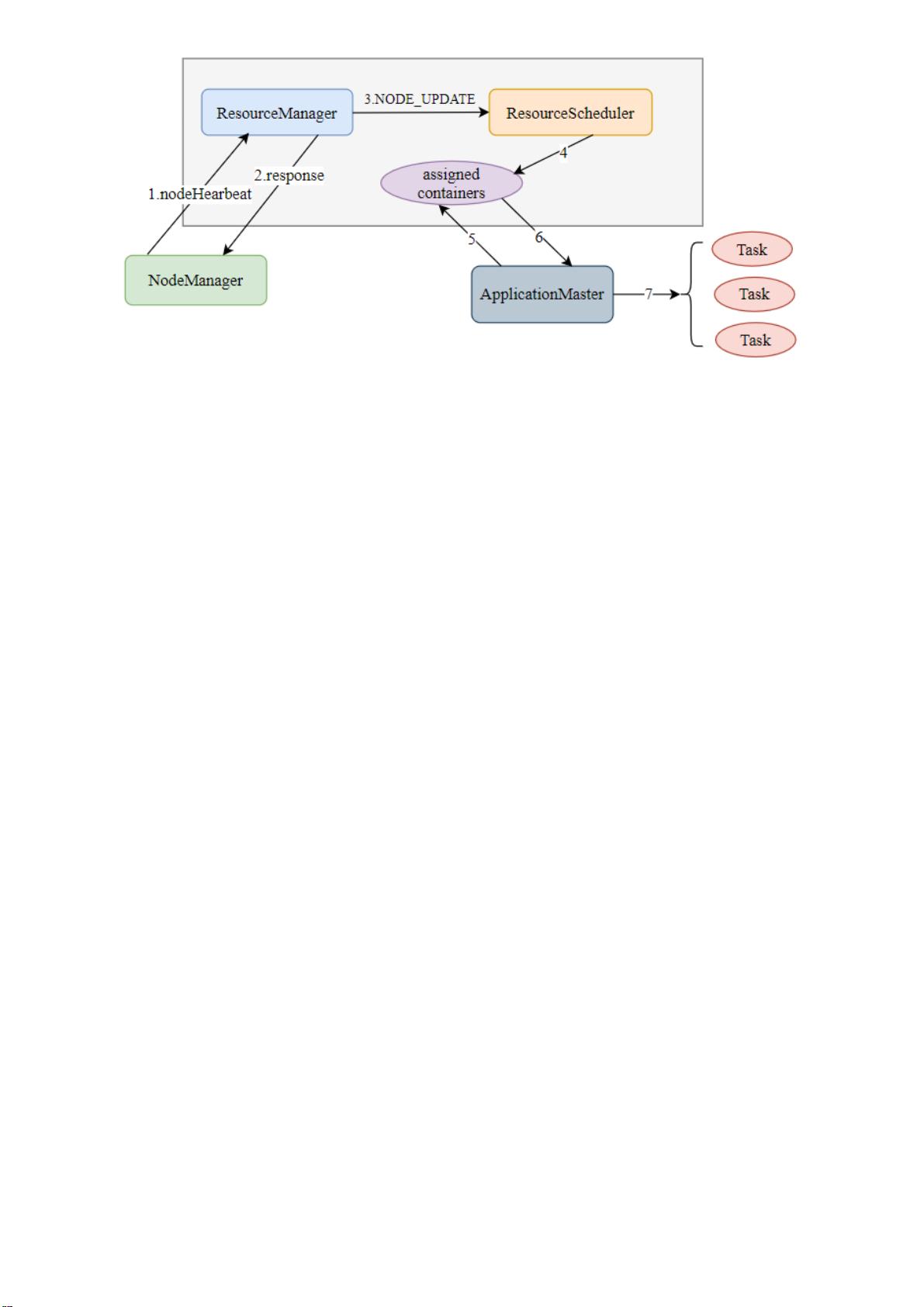
上述资源分配过程中是异步的,资源调度器采取的是 pull-based (拉模型)通信模型。当资源调度器将
资源分配出去后,它不会立刻将该资源推给 ApplicationMaster,而是会将其放到一个缓冲区中,等待
ApplicationMaster 通过周期性的心跳主动来取。
在 YARN 中,资源分配过程主要分为以下几个步骤:
1. NM 通过心跳向 RM 汇报节点资源信息;
2. RM 向 NM 返回一个心跳应答,并且返回需要释放的 Container 列表信息;
3. RM 收到节点信息后,触发 NODE_UPDATE 事件;
4. RM 中的资源调度器收到 NODE_UPDATE 事件,并将该节点上的资源分配给各个应用程序,且将
分配结果放到一个内存数据结果中;
5. 应用程序的 AM 向 RM 发送心跳,领取最新分配好的 Container;
6. RM 收到来自 AM 的心跳信息后,将分配好的 Container 以心跳应答形式返回给
ApplicationMaster;
7. 最后,AM 将受到的 Container 进一步分配给各个 Task 任务。
1.2.2资源保证机制
在分布式计算中,,有两种资源保证机制,来保障应用程序的资源申请。第一种,当应用程序申请的资
源暂时无法保证时, 会优先为应用程序预留一个节点上的资源直到累计释放的空闲资源,满足应用程序
需求,这种称为增量资源分配。
第二种,当应用程序申请的资源无法保证时,其会暂时放弃当前资源直到出现一个节点剩余资源一次性
满足应用程序需求,这种称为一次性资源分配。
上述两种机制都存在优缺点,对于增量资源分配而言,资源预留会导致资源浪费,降低集群资源利用
率;一次性资源分配产生饿死现象,应用资源可能一直等不到满足资源需求的节点出现。
YARN 采取的是增量资源分配机制。
1.3资源分配算法
YARN 资源调度器采取的是主资源公平调度算法(Dominant Resource Fairness,DRF)。DRF 算法将
所需要的资源份额(资源比例)最大的资源,称为主资源,而 DRF 的基本设计思想是将最大最小公平算
法应用在主资源上,从而将多维度资源调度问题转化为单维度资源调度问题。理解起来是不是有点抽
象,下面举一个实例:
剩余10页未读,继续阅读
2022-10-06 上传
2018-06-09 上传
2023-09-05 上传
2023-09-18 上传
2023-10-24 上传
2023-07-12 上传
2023-12-24 上传
2023-04-29 上传
2023-07-12 上传
2023-07-12 上传

毕设小程序软件程序猿
- 粉丝: 154
- 资源: 655
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
