林业应用:逻辑回归模型解析
需积分: 9 21 浏览量
更新于2024-07-18
收藏 878KB PDF 举报
"这篇工作论文是关于逻辑回归模型的介绍,包含了林业应用的实际示例。由温迪·伯格鲁德编写,属于生物统计信息手册第7号,旨在讨论和教育目的,由英属哥伦比亚森林部研究计划出版。"
逻辑回归是一种广泛应用的统计分析方法,尤其适用于处理包含分类响应变量的数据。在描述中提到的几个例子,如树的生存、物种存在与否、种子幼苗疾病或损害的存在,都是典型的二元或者多分类问题,这些问题可以通过逻辑回归进行分析。
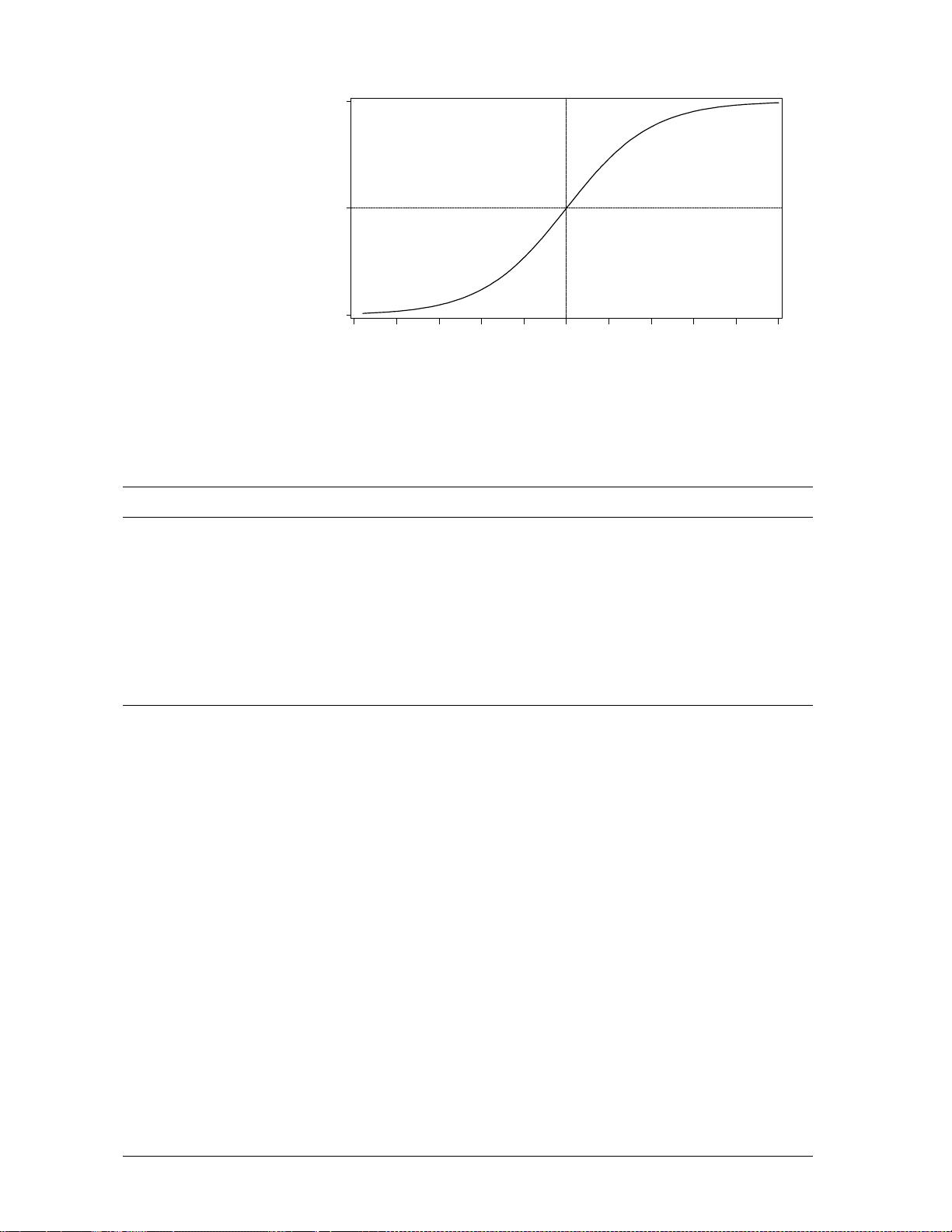
逻辑回归的核心在于它能够预测一个事件发生的概率。与线性回归不同,逻辑回归不直接预测连续数值,而是预测因变量(响应变量)属于某一类别的概率。在模型中,我们用一个线性函数(通常是自变量的线性组合)来描述影响结果的因素,然后通过一个非线性的 logistic 函数(Sigmoid 函数)将线性部分转化为0到1之间的概率值。
在林业应用中,例如,我们可以使用逻辑回归来研究影响树种生存率的因素,如土壤类型、气候条件、种植密度等。通过这种方法,我们可以估计在特定条件下树种存活的概率,并对不同的管理策略进行比较,以优化森林的健康和生产力。
逻辑回归模型的构建通常包括以下几个步骤:
1. 数据收集:首先需要收集包括响应变量和预测变量在内的数据。
2. 模型拟合:利用最大似然估计法找到最佳的参数,使得模型在训练数据上的预测概率最接近实际观测的类别。
3. 模型评估:通过诸如AUC-ROC曲线、准确率、召回率、F1分数等指标评估模型的性能。
4. 预测与解释:模型可用于新数据的预测,并且可以解释各预测变量对响应变量的影响大小。
在论文中,温迪·伯格鲁德提供了具体的林业实例,可能包括数据的预处理、模型的选择、参数估计和模型验证等步骤,读者可以通过这些实例深入理解逻辑回归在实际问题中的应用。
逻辑回归模型是一种强大的工具,尤其在处理分类预测问题时,能够帮助研究人员和决策者理解变量间的关联并进行预测。通过温迪·伯格鲁德的工作论文,林业工作者和其他相关领域的专业人士可以学习如何运用逻辑回归解决实际问题,提高工作效率和决策的科学性。
6
0.0
0.1
0.2
0.3
0.4
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
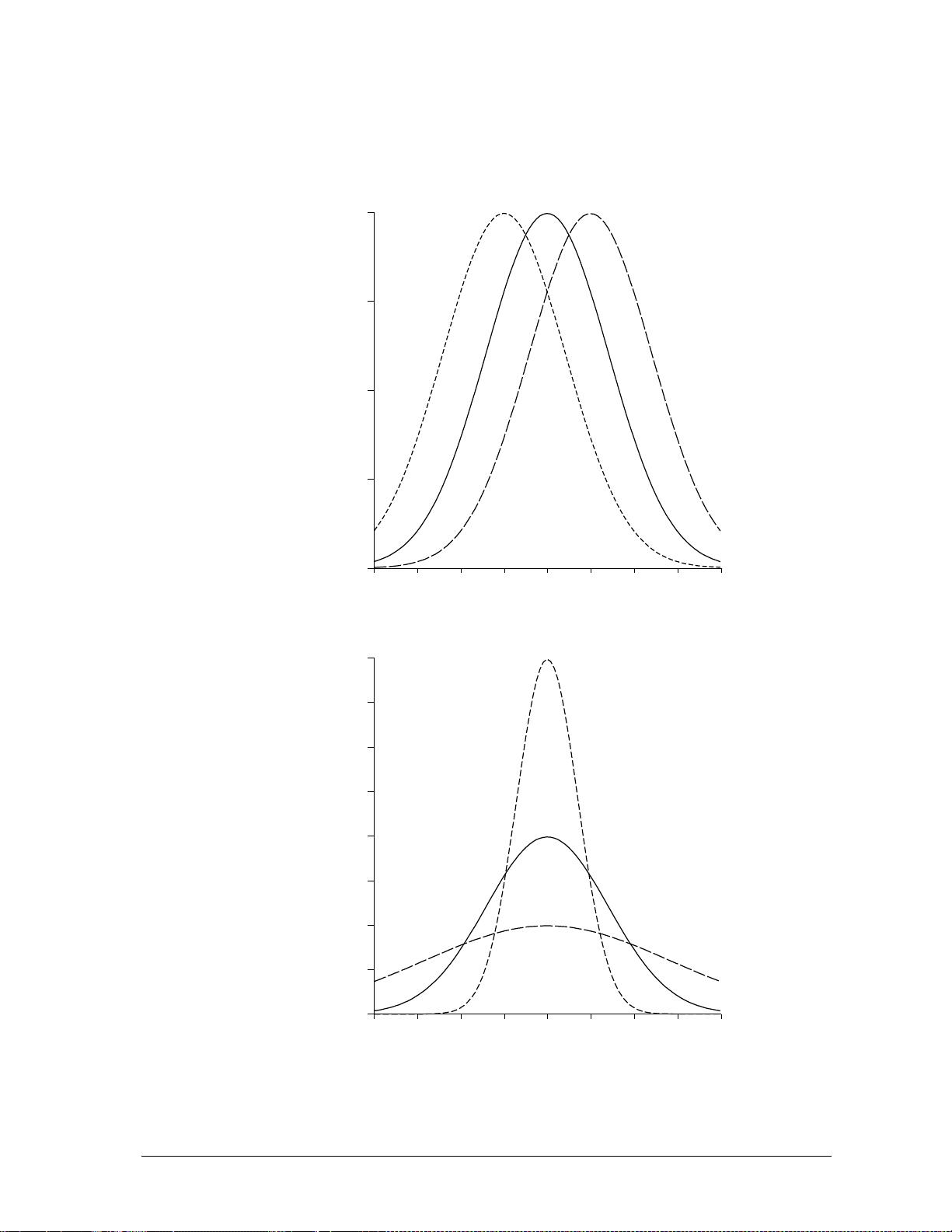
a) Normal distribution with different means
b) Normal distribution with different variances
-4-3-2-101234
-4-3-2-101234
σ
2
≤1
σ
2
≥1
σ
2
=1
µ = -1 µ = 0
µ = 1
1
The normal distribution with different values for (a) the mean, and (b) the
variance.


剩余156页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-09-10 上传
2019-04-23 上传
点击了解资源详情
: Exploring the Similarities and Differences Between Generalized Linear Models and Linear Regression
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

Alladins
- 粉丝: 1
- 资源: 57
 我的内容管理
展开
我的内容管理
展开







