Demystifying the Confusion Matrix: How to Evaluate the Actual Performance of Classification Models
发布时间: 2024-09-15 14:06:42 阅读量: 25 订阅数: 24 
# Theoretical Foundation of Confusion Matrix
## Introduction and Definition
The Confusion Matrix is a crucial tool in machine learning for evaluating the performance of classification models. It is a table that describes the correspondence between actual categories and predicted categories. With the help of the confusion matrix, we can gain a deeper understanding of the model's predictions, which leads to better optimization of the model.
## Composition of Confusion Matrix
A typical confusion matrix consists of four key parts: True Positives (TP), False Positives (FP), True Negatives (TN), and False Negatives (FN). By analyzing these parts, we can identify the strengths and weaknesses of the model in classification tasks.
## Calculation and Application
When constructing a confusion matrix, we need to collect sufficient test data to evaluate the model's predictions. By calculating the confusion matrix, we can derive a series of evaluation metrics such as Precision, Recall, and F1 Score, which are key indicators for measuring model performance.
In the following chapters, we will delve into the various components of the confusion matrix, their calculation methods, and their crucial role in model evaluation.
# Core Components and Calculation Methods of Confusion Matrix
## 2.1 Elements of Confusion Matrix Composition
### 2.1.1 True Positives and False Positives
In the confusion matrix, True Positives (TP) represent the number of samples that the model correctly predicted as positive cases. These samples are the target that the model aims to capture in actual problems, such as correctly diagnosed patients in disease detection. Correctly identifying these samples is the main task of the model, and therefore, the number of TP is an important indicator for evaluating model performance.
False Positives (FP) represent the number of samples that the model incorrectly predicted as positive cases. In real-world applications, this can mean false alarms, such as misjudging healthy people as having a disease, which is typically something that needs to be avoided, as it can lead to the waste of resources and unnecessary anxiety.
### 2.1.2 True Negatives and False Negatives
True Negatives (TN) are the number of samples that the model correctly predicted as negative cases, which are not target categories. TN may not be important in some problems, but they are crucial in issues involving the avoidance of negative consequences, such as excluding false alarms in security systems.
False Negatives (FN) refer to the number of samples that the model incorrectly predicted as negative cases, but are actually the target category. In decision-making processes, FN can lead to significant losses, such as missing the diagnosis of actual patients in disease detection.
## 2.2 Calculation Principles of Confusion Matrix
### 2.2.1 Cross-Comparison of Classification Results
When constructing a confusion matrix, it is necessary to cross-compare the model's predicted results with the actual categories. In operation, a threshold can be set to convert the model's predicted probabilities into specific category labels. Then, these labels are compared with the actual labels and filled into the corresponding TP, FP, TN, and FN positions in the confusion matrix.
### 2.2.2 Mathematical Representation of Category Calculation
Mathematically, TP, FP, TN, and FN can be calculated as follows:
- TP = Σ (predicted as positive and actually positive)
- FP = Σ (predicted as positive and actually negative)
- TN = Σ (predicted as negative and actually negative)
- FN = Σ (predicted as negative and actually positive)
Where Σ represents the summation operation for all samples. Based on these formulas, we can build the mathematical model of the confusion matrix and fill it with actual data.
## 2.3 Relationship Between Confusion Matrix and Evaluation Metrics
### 2.3.1 Precision, Recall, and Confusion Matrix
Precision is the proportion of truly positive cases among the samples predicted as positive by the model, with the calculation formula: Precision = TP / (TP + FP). Precision focuses on how many of the samples predicted as positive by the model are actually true positives, and it is commonly used to measure the quality of the model.
Recall, or True Positive Rate (TPR), is the proportion of truly positive cases that are correctly identified by the model, with the calculation formula: Recall = TP / (TP + FN). Recall focuses on the coverage of positive samples by the model, telling us how many target samples the model can identify.
### 2.3.2 Calculation Basis for F1 Score and ROC Curve
The F1 score is the harmonic mean of Precision and Recall, providing a single indicator to balance the relationship between Precision and Recall. The F1 score is very useful when both Precision and Recall are equally important.
The ROC (Receiver Operating Characteristic) curve is a tool for evaluating model performance, which plots the change in True Positive Rate (TPR) and False Positive Rate (FPR) at different thresholds, demonstrating the model's classification ability. The area under the ROC curve (Area Under Curve, AUC) is another important indicator for evaluating the performance of classifiers, which can provide an unbiased performance assessment.
Based on these evaluation metrics, we can comprehensively evaluate the model from different perspectives, and all these evaluation metrics are based on the calculations from the confusion matrix.
# 3. Application Examples of Confusion Matrix in Classification Models
## 3.1 Preparation for Classification Tasks and Construction of Confusion Matrix
In machine learning projects, classification tasks are a core component, involving the classification of samples in the dataset into different categories. The confusion matrix is a basic and powerful tool for evaluating the performance of classification models. It can detail the results of each category that the model predicts, serving as the basis for further analysis of the model's performance and optimization of performance.
### 3.1.1 Selection of Datasets and Preprocessing
Selecting the appropriate dataset is the first step in any machine learning task. Depending on the complexity of the task and specific requirements, datasets can be obtained from public data sources or may require acquisition and preprocessing operations. Data preprocessing includes steps such as handling missing values, noise, outliers, and data normalization. Ensuring the quality of the dataset is crucial because the quality of the data directly affects the model's performance and the reliability of the confusion matrix.
```python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Assuming we have a dataset named 'binary_dataset.csv'
data = pd.read_csv('binary_dataset.csv')
# Data preprocessing steps
# Handling missing values
data.fillna(data.mean(), inplace=True)
# Splitting the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
data.drop('target', axis=1), data['target'], test_size=0.3, random_state=42)
# Data normalization
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
```
In the above code, we first import the necessary libraries, then read the dataset and perform a series of preprocessing steps. Next, we split the dataset into a training set and a testing set and standardize the data to help the model learn better.
### 3.1.2 Model Training and Calculation of Confusion Matrix
After data preprocessing, we can begin the model training process and use the confusion matrix to evaluate the model's classification performance. Here is an example of using Python's `sklearn` library to train a simpl

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
【数据集不平衡处理法】:解决YOLO抽烟数据集类别不均衡问题的有效方法

# 1. 数据集不平衡现象及其影响
在机器学习中,数据集的平衡性是影响模型性能的关键因素之一。不平衡数据集指的是在分类问题中,不同类别的样本数量差异显著,这会导致分类器对多数类的偏好,从而忽视少数类。
## 数据集不平衡的影响
不平衡现象会使得模型在评估指标上产生偏差,如准确率可能很高,但实际上模型并未有效识别少数类样本。这种偏差对许多应
【大数据处理利器】:MySQL分区表使用技巧与实践
# 1. MySQL分区表概述与优势
## 1.1 MySQL分区表简介
MySQL分区表是一种优化存储和管理大型数据集的技术,它允许将表的不同行存储在不同的物理分区中。这不仅可以提高查询性能,还能更有效地管理数据和提升数据库维护的便捷性。
## 1.2 分区表的主要优势
分区表的优势主要体现在以下几个方面:
- **查询性能提升**:通过分区,可以减少查询时需要扫描的数据量
绿色计算与节能技术:计算机组成原理中的能耗管理
# 1. 绿色计算与节能技术概述
随着全球气候变化和能源危机的日益严峻,绿色计算作为一种旨在减少计算设备和系统对环境影响的技术,已经成为IT行业的研究热点。绿色计算关注的是优化计算系统的能源使用效率,降低碳足迹,同时也涉及减少资源消耗和有害物质的排放。它不仅仅关注硬件的能耗管理,也包括软件优化、系统设计等多个方面。本章将对绿色计算与节能技术的基本概念、目标及重要性进行概述
【数据分片技术】:实现在线音乐系统数据库的负载均衡
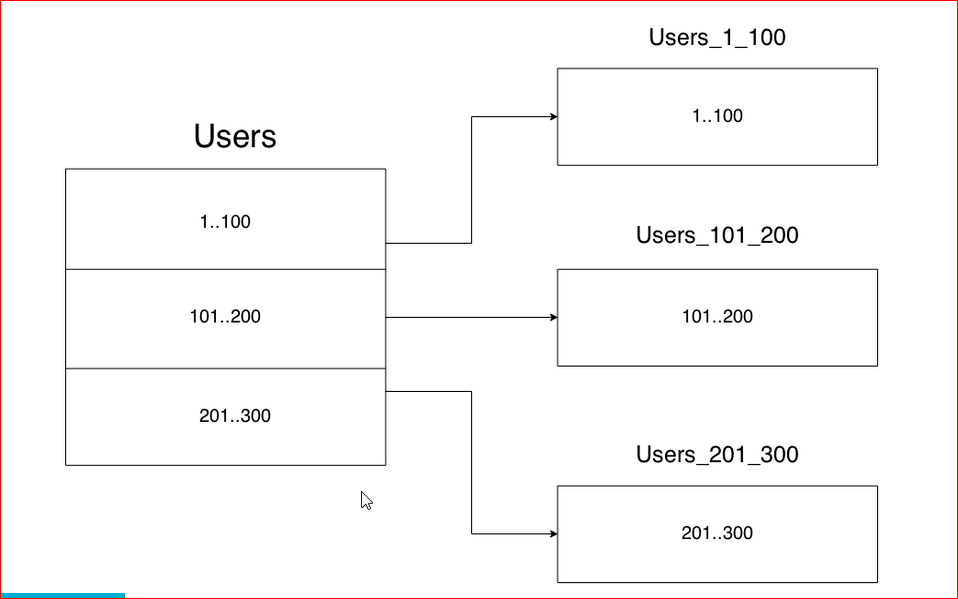
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
【用户体验设计】:创建易于理解的Java API文档指南
# 1. Java API文档的重要性与作用
## 1.1 API文档的定义及其在开发中的角色
Java API文档是软件开发生命周期中的核心部分,它详细记录了类库、接口、方法、属性等元素的用途、行为和使用方式。文档作为开发者之间的“沟通桥梁”,确保了代码的可维护性和可重用性。
## 1.2 文档对于提高代码质量的重要性
良好的文档
【Python讯飞星火LLM问题解决】:1小时快速排查与解决常见问题
# 1. Python讯飞星火LLM简介
Python讯飞星火LLM是基于讯飞AI平台的开源自然语言处理工具库,它将复杂的语言模型抽象化,通过简单易用的API向开发者提供强大的语言理解能力。本章将从基础概览开始,帮助读者了解Python讯飞星火LLM的核心特性和使用场景。
## 星火LLM的核心特性
讯飞星火LLM利用深度学习技术,尤其是大规模预训练语言模型(LLM),提供包括但不限于文本分类、命名实体识别、情感分析等自然语言处理功能。开发者可以通过简单的函数调用,无需复杂的算法知识,即可集成高级的语言理解功能至应用中。
## 使用场景
该工具库广泛适用于各种场景,如智能客服、内容审
【数据库连接池管理】:高级指针技巧,优化数据库操作

# 1. 数据库连接池的概念与优势
数据库连接池是管理数据库连接复用的资源池,通过维护一定数量的数据库连接,以减少数据库连接的创建和销毁带来的性能开销。连接池的引入,不仅提高了数据库访问的效率,还降低了系统的资源消耗,尤其在高并发场景下,连接池的存在使得数据库能够更加稳定和高效地处理大量请求。对于IT行业专业人士来说,理解连接池的工作机制和优势,能够帮助他们设计出更加健壮的应用架构。
# 2. 数据库连
面向对象编程与函数式编程:探索编程范式的融合之道

# 1. 面向对象编程与函数式编程概念解析
## 1.1 面向对象编程(OOP)基础
面向对象编程是一种编程范式,它使用对象(对象是类的实例)来设计软件应用。
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )