Evaluating Model Overfitting and Underfitting: Diagnosis and Solutions
发布时间: 2024-09-15 14:38:22 阅读量: 28 订阅数: 38 

This Python project involves building and evaluating Convolution
# Model Overfitting and Underfitting: Diagnosis and Solutions
## 1. Concepts of Model Overfitting and Underfitting
### Definitions of Model Overfitting and Underfitting
In machine learning, model overfitting and underfitting are two common training issues. In simple terms, underfitting occurs when a model is too simple to capture the true relationships in the data, leading to poor performance on both training and test sets. Overfitting, on the other hand, refers to a model that is too complex and learns not only the true patterns in the data but also the noise and outliers. This results in the model performing well on the training set but poorly on the test set, indicating weak generalization.
### The Impact of Model Overfitting
Overfitting is a significant challenge in model training. It signifies that while the model performs perfectly on the training data, it fails to adapt to new, unseen data. This is undesirable in practical applications, as the ultimate goal is to enable the model to make accurate predictions in real-world scenarios. Therefore, understanding the concepts of overfitting and underfitting, as well as how to diagnose and solve these issues, is crucial for building effective and robust machine learning models.
## 2. Theoretical Foundations of Overfitting and Underfitting
### Model Complexity and Fitting Ability
#### Definition of Model Complexity and Its Impact on Fitting
Model complexity refers to the degree of complexity of the functional relationships that a model can describe. In machine learning, a complex model with many parameters can capture subtle features and patterns in the data. However, overly complex models are also prone to capturing noise and outliers, leading to overfitting.
Highly complex models, such as deep neural networks, may perform exceptionally well on training data but poorly on unseen data, as they may have learned specific attributes of the training data rather than the underlying, universal patterns. This phenomenon is known as overfitting. In contrast, simple models, such as linear models, may fail to capture the complexity in the data, leading to underfitting.
In practice, choosing a model with the right complexity is challenging. Selecting a model that is too complex may result in overfitting, while one that is too simple may underfit. Typically, more complex models require more data to train to ensure they generalize beyond the training set.
#### Balancing Fitting Ability with Generalization Ability
Fitting ability refers to the degree of match between a model and the training data, while generalization ability refers to the model's performance on new data. Ideally, a model should find a balance between fitting ability and generalization ability.
Increasing a model's fitting ability often means increasing its complexity, such as adding more layers or neurons. However, an overemphasis on fitting ability may lead to the model learning the noise in the training data, which in turn results in poor performance on new data, or overfitting.
Enhancing generalization ability involves reducing model complexity, increasing the amount of data, data augmentation, or applying regularization techniques. These methods can help the model to make more accurate predictions on unseen data more stably.
### Theoretical Methods for Identifying Overfitting and Underfitting
#### Comparative Analysis of Performance on Training and Test Sets
In machine learning projects, dividing the dataset into training and test sets is the basic method for identifying overfitting and underfitting. By comparing the performance of a model on the training and test sets, one can assess the model's generalization ability.
A model that is overfitting performs well on the training set but poorly on the test set, indicating that it has captured noise in the training data rather than the underlying distribution. Conversely, if a model's performance on the test set is similar to or not significantly different from that on the training set, overfitting may not be present. However, if both performances are poor, underfitting may be the issue.
#### The Importance of Cross-Validation
Cross-validation is a technique for assessing a model's generalization ability, particularly useful when the amount of data is small. In k-fold cross-validation, the dataset is divided into k similar-sized mutually exclusive subsets. Each subset is轮流 used as a test set, while the remaining subsets form the training set. The model is trained and validated on k different training and test sets, with the final performance evaluation being the average of all k training instances.
The importance of cross-validation lies in its ability to provide more stable performance assessments and reduce the variation in evaluation results due to different data partitioning methods. This is crucial for preventing overfitting and choosing the appropriate model complexity.
#### The Role of Statistical Tests in Diagnosis
Statistical tests are techniques that use statistical methods to determine if the performance differences in a model are statistically significant. Hypothesis testing, such as t-tests or ANOVA, can ascertain whether performance differences across different configurations or datasets are significant.
In the diagnosis of overfitting and underfitting, statistical tests can help us understand whether the performance differences between the training and test sets are within normal bounds or significant enough to indicate overfitting or underfitting. Furthermore, statistical tests can assist in comparing multiple models or datasets to select the best one.
Up to this point, we have introduced the theoretical foundations of overfitting and underfitting and discussed methods for identifying these phenomena. In the next chapter, we will explore techniques for identifying model issues using visualization, as well as how to diagnose models using numerical indicators.
## 3. Diagnostic Techniques for Overfitting and Underfitting
During the training process of machine learning models, overfitting or underfitting may occur due to data, incorrect parameter settings, or other reasons. Effectively diagnosing overfitting and underfitting is an important step in model tuning, as it helps us understand the current performance and potential problems of the model. This chapter will focus on introducing various diagnostic techniques, including visualization methods, numerical diagnostic indicators, and the use of performance monitoring tools.
### 3.1 Identifying Model Issues Using Visualization
#### Analytical Techniques for Residual Plots
Residual plots are an effective tool for analyzing whether a regression model is overfitting or underfitting. Residuals are the differences between the model's predicted values and actual values, and a residual plot is a scatter plot of residuals plotted in the order of input data.
```python
import matplotlib.pyplot as plt
# Assuming y_actual is the actual values and y_pred is the model's predicted values
y_actual = [actual data]
y_pred = [model predicted data]
residuals = y_actual - y_pred
plt.scatter(range(len(y_actual)), residuals)
plt.title('Residual Plot')
plt.xlabel('Sample Index')
plt.ylabel('Residual Value')
plt.axhline(y=0, color='r', linestyle='--')
plt.show()
```
When analyzing the residual plot, we should focus on whether the residuals are randomly distributed, whether the mean of the residuals is close to 0, and whether there are any obvious patterns or trends. If the residuals display specific patterns or trends, this may indicate that the model has failed to capture certain features in the data or that overfitting is present.
#### Plotting and Interpreting Learning Curves
Learning curves are charts obtained by plotting a model's performance on the training and validation sets as a function of the number of training samples. By analyzing the learning curve, we can identify whether the model is overfitting or underfitting.
```python
# Assuming train_scores and valid_scores are the performance metrics for the model at different numbers of training samples
import numpy as np
import matplotlib.pyplot as plt
train_sizes = np.linspace(0.1, 1.0, 10)
train_scores_mean = [some value] # Training set mean
train_scores_std = [some value] # Training set standard deviation
valid_scores_mean = [some value] # Validat
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB中MSK调制的艺术】:差分编码技术的优化与应用

# 摘要
MSK调制技术作为现代通信系统中的一种关键调制方式,与差分编码相结合能够提升信号传输的效率和抗干扰能力。本文首先介绍了MSK调制技术和差分编码的基础理论,然后详细探讨了差分编码在MSK调制中的应用,包括MSK调制器设计与差分编码
从零开始学习RLE-8:一文读懂BMP图像解码的技术细节

# 摘要
本文从编码基础与图像格式出发,深入探讨了RLE-8编码技术在图像处理领域的应用。首先介绍了RLE-8编码机制及其在BMP图像格式中的应用,然后详细阐述了RLE-8的编码原理、解码算法,包括其基本概念、规则、算法实现及性能优化策略。接着,本文提供了BMP图像的解码实践指南,解析了文件结构,并指导了RLE-8解码器的开发流程。文章进一步分析了RLE-8在图像压缩中的优势和适用场景,以及其在高级图像处
Linux系统管理新手入门:0基础快速掌握RoseMirrorHA部署
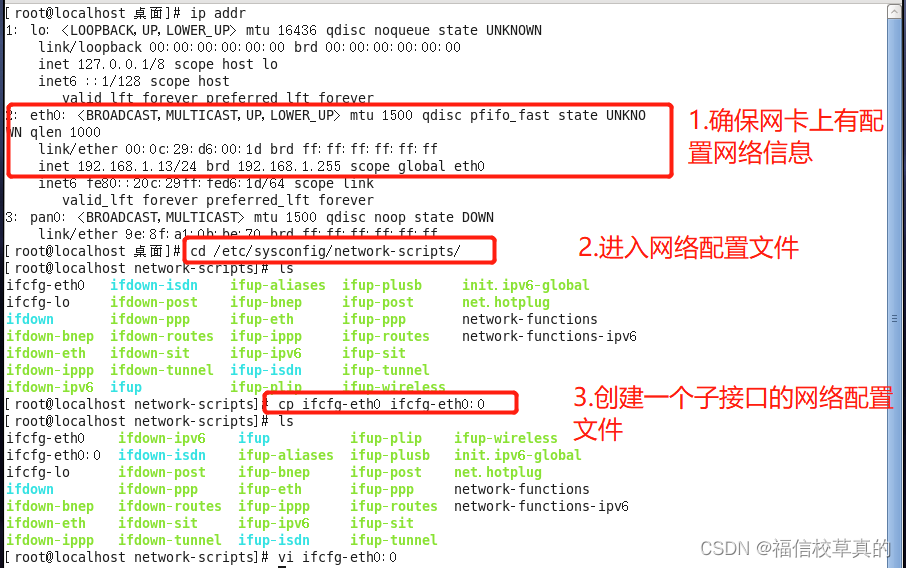
# 摘要
本文首先介绍了Linux系统管理的基础知识,随后详细阐述了RoseMirrorHA的理论基础及其关键功能。通过逐步讲解Linux环境下RoseMirrorHA的部署流程,包括系统要求、安装、配置和启动,本文为系统管理员提供了一套完整的实施指南。此外,本文还探讨了监控、日常管理和故障排查等关键维护任务,以及高可用场景下的实践和性能优化策略。最后,文章展望了Linux系统管理和R
用户体验:华为以用户为中心的设计思考方式与实践
# 摘要
用户体验在当今产品的设计和开发中占据核心地位,对产品成功有着决定性影响。本文首先探讨了用户体验的重要性及其基本理念,强调以用户为中心的设计流程,涵盖用户研究、设计原则、原型设计与用户测试。接着,通过华为的设计实践案例分析,揭示了用户研究的实施、用户体验的改进措施以及界面设计创新的重要性。此外,本文还探讨了在组织内部如何通过
【虚拟化技术】:smartRack资源利用效率提升秘籍
# 摘要
本文全面介绍了虚拟化技术,特别是smartRack平台在资源管理方面的关键特性和实施技巧。从基础的资源调度理论到存储和网络资源的优化,再到资源利用效率的实践技巧,本文系统阐述了如何在smartRack环境下实现高效的资源分配和管理。此外,本文还探讨了高级资源管理技巧,如资源隔离、服务质量(QoS)保障以及性能分析与瓶颈诊
【聚类算法选型指南】:K-means与ISODATA对比分析
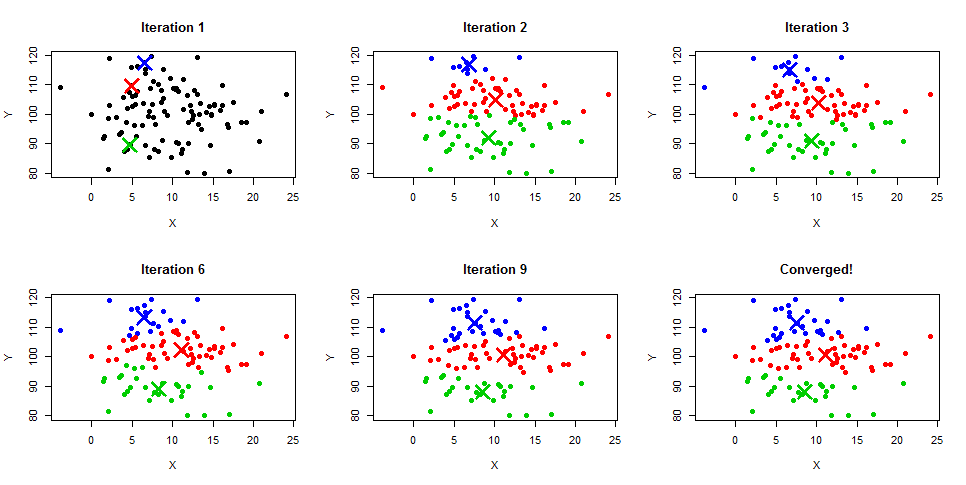
# 摘要
本文系统地介绍了聚类算法的基础知识,着重分析了K-means算法和ISODATA算法的原理、实现过程以及各自的优缺点。通过对两种算法的对比分析,本文详细探讨了它们在聚类效率、稳定性和适用场景方面的差异,并展示了它们在市场细分和图像分割中的实际应用案例。最后,本文展望了聚类算法的未来发展方向,包括高维数据聚类、与机器学习技术的结合以及在新兴领域的应用前景。
# 关
小米mini路由器序列号恢复:专家教你解决常见问题

# 摘要
本文对小米mini路由器序列号恢复问题进行了全面概述。首先介绍了小米mini路由器的硬件基础,包括CPU、内存、存储设备及网络接口,并探讨了固件的作用和与硬件的交互。随后,文章转向序列号恢复的理论基础,阐述了序列号的重要性及恢复过程中的可行途径。实践中,文章详细描述了通过Web界面和命令行工具进行序列号恢复的方法。此外,本文还涉及了小米mini路由器的常见问题解决,包括
深入探讨自然辩证法与软件工程的15种实践策略

# 摘要
自然辩证法作为哲学原理,为软件工程提供了深刻的洞见和指导原则。本文探讨了自然辩证法的基本原理及其在软件开发、设计、测试和管理中的应用。通过辩证法的视角,文章分析了对立统一规律、质量互变规律和否定之否定原则在软件生命周期、迭代优化及软件架构设计中的体现。此外,还讨论了如何将自然辩证法应用于面向对象设计、设计模式选择以及测试策略的制定。本文强调了自然辩证法在促进软
【自动化控制】:PRODAVE在系统中的关键角色分析

# 摘要
本文对自动化控制与PRODAVE进行了全面的介绍和分析,阐述了PRODAVE的基础理论、应用架构以及在自动化系统中的实现。文章首先概述了PRODAVE的通信协议和数据交换模型,随后深入探讨了其在生产线自动化、能源管理和质量控制中的具体应用。通过对智能工厂、智能交通系统和智慧楼宇等实际案例的分析,本文进一步揭示了PR
【VoIP中的ITU-T G.704应用】:语音传输最佳实践的深度剖析

# 摘要
本文系统地分析了ITU-T G.704协议及其在VoIP技术中的应用。文章首先概述了G.704协议的基础知识,重点阐述了其关键特性,如帧结构、时间槽、信道编码和信号传输。随后,探讨了G.704在保证语音质量方面的作用,包括误差检测控制机制及其对延迟和抖动的管理。此外,文章还分析了G.704
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )