Avoiding the Accuracy Pitfall: Evaluating Indicators with Support Vector Machines
发布时间: 2024-09-15 14:09:13 阅读量: 30 订阅数: 41 
# 1. Support Vector Machine Fundamentals
Support Vector Machine (SVM) is a machine learning method developed on the basis of statistical learning theory. It is widely used in classification and regression analysis. The core idea of SVM is to find an optimal hyperplane to correctly classify data points of different categories, maximizing the margin between different categories. It can handle both linearly separable and nonlinearly separable data and has shown superior performance in many practical applications.
In the first chapter, we first introduce the basic concepts of SVM, then explore its unique advantages and basic working principles in data classification. We will use simple examples to explain the core idea of SVM, building a preliminary understanding of SVM for readers.
## 1.1 Basic Concepts of SVM
Support Vector Machine (SVM) is a supervised learning model used to solve classification problems. It separates datasets into two categories by finding a hyperplane. The choice of hyperplane needs to maximize the margin between two categories of data, that is, the "maximum margin" principle. In the ideal case, the classification margin is the largest, meaning that the hyperplane can be as far away from the nearest data points as possible, thereby improving the model's generalization ability.
## 1.2 Core Advantages of SVM
A significant advantage of SVM is its excellent generalization ability, especially outstanding when the feature space dimension is much larger than the number of samples. In addition, SVM introduces the kernel trick, which allows SVM to effectively deal with nonlinearly separable problems. By nonlinearly mapping the data, SVM can find a linear decision boundary in a high-dimensional space, thereby achieving nonlinear classification in the original space.
On this basis, we will delve into the principles and applications of SVM, laying a solid theoretical foundation for the in-depth analysis of SVM theory, discussion of evaluation metrics, and introduction of practical applications in subsequent chapters.
# 2. Theoretical Foundations and Mathematical Principles of Support Vector Machines
## 2.1 Linearly Separable Support Vector Machines
### 2.1.1 Linearly Separable Problems and Hyperplanes
Linearly separable problems are a special case of classification problems in machine learning. In such cases, samples of two categories can be completely separated by a hyperplane. Mathematically, if we have an n-dimensional feature space, then the hyperplane can be represented as an (n-1)-dimensional subspace. For example, in two-dimensional space, the hyperplane is a straight line; in three-dimensional space, the hyperplane is a plane.
In Support Vector Machines (SVM), finding this hyperplane is crucial. We hope to find a hyperplane that not only correctly separates the two types of data but also has the largest margin (the distance from the hyperplane to the nearest data points, support vectors, is as large as possible). The purpose of doing this is to obtain better generalization ability, that is, to perform better on unseen data.
### 2.1.2 Definition and Solution of Support Vectors
Support vectors are the training data points closest to the decision boundary. They directly determine the position and direction of the hyperplane and are the most critical factors in forming the optimal decision boundary. When solving linearly separable SVMs, the goal is to maximize the margin between the two categories.
The solution to support vector machines can be accomplished through an optimization problem. Specifically, we need to solve the following optimization problem:
\begin{aligned}
& \text{minimize} \quad \frac{1}{2} \|\mathbf{w}\|^2 \\
& \text{subject to} \quad y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq 1, \quad i = 1, \ldots, m
\end{aligned}
Where $\mathbf{w}$ is the normal vector of the hyperplane, $b$ is the bias term, $y_i$ is the class label, $\mathbf{x}_i$ is the sample point, and $m$ is the number of samples. The constraints of this optimization problem ensure that all sample points are correctly classified and that the distance from the hyperplane is at least 1.
The above optimization problem is typically solved using the Lagrange multiplier method, transforming it into a dual problem for solution. The solution will give a model determined by the support vectors and their corresponding weights.
## 2.2 Kernel Trick and Non-Linear Support Vector Machines
### 2.2.1 Concept and Types of Kernel Functions
The concept of kernel functions is the core of SVM's ability to handle nonlinear problems. Kernel functions can map the original feature space to a higher-dimensional feature space, making data that is not linearly separable in the original space linearly separable in the new space.
An important property of kernel functions is that they do not need to explicitly calculate the high-dimensional feature vectors after mapping, but achieve im***mon types of kernel functions include linear kernel, polynomial kernel, Gaussian Radial Basis Function (RBF) kernel, and sigmoid kernel, among others.
Taking the Gaussian RBF kernel as an example, its mathematical expression is as follows:
K(\mathbf{x}, \mathbf{z}) = \exp\left(-\gamma \|\mathbf{x} - \mathbf{z}\|^2\right)
Where $\mathbf{x}$ and $\mathbf{z}$ are two sample points, and $\gamma$ is the parameter of the kernel function. The RBF kernel can control the distribution of the mapped data by adjusting the value of $\gamma$ to control the "influence range" of sample points.
### 2.2.2 Application of the Kernel Trick in Non-Linear Problems
By introducing kernel functions, support vector machines can be extended from linear classifiers to nonlinear classifiers. When dealing with nonlinear problems, SVM uses the kernel trick to implicitly construct hyperplanes in high-dimensional spaces.
The application of the kernel trick in nonlinear SVMs can be summarized in the following steps:
1. Select an appropriate kernel function and its corresponding parameters.
2. Use the kernel function to calculate the inner product between sample points in the high-dimensional space.
3. Construct an optimization problem in the high-dimensional space and solve it to obtain the hyperplane.
4. Define the final classification decision function using support vectors and weights.
The effectiveness of the kernel trick depends on whether the selected kernel function can map to a feature space in which the sample points become linearly separable. Through the kernel trick, SVM has shown strong capabilities in dealing with complex nonlinear classification problems in image recognition, text classification, and other fields.
## 2.3 Support Vector Machine Optimization Problems
### 2.3.1 Introduction to Lagrange Multiplier Method
The Lagrange multiplier method is an effective method for solving optimization problems with constraint conditions. In support vector machines, by introducing Lagrange multipliers (also known as Lagrange dual variables), the original problem can be transformed into a dual problem, which is easier to solve.
The original optimization problem can be written in the following form:
\begin{aligned}
& \text{minimize} \quad \frac{1}{2} \|\mathbf{w}\|^2 \\
& \text{subject to} \quad y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq 1, \quad i = 1, \ldots, m
\end{aligned}
Using the Lagrange multiplier method, we construct the Lagrange function:
L(\mathbf{w}, b, \alpha) = \frac{1}{2} \|\mathbf{w}\|^2 - \sum_{i=1}^{m} \alpha_i \left( y_i (\mathbf{w} \cdot \mathbf{x}_i + b) - 1 \right)
Where $\alpha_i \geq 0$ are Lagrange multipliers. Next, by taking the partial derivative of $L$ with respect to $\mathbf{w}$ and $b$ and setting the derivative to zero, we can obtain the expressions for $\mathbf{w}$ and $b$.
### 2.3.2 Dual Problem and KKT Conditions
The dual problem obtained by the Lagrange multiplier method is the equivalent form of the original problem and is usually easier to solve. The goal of the dual problem is to maximize the expression of the Lagrange function with respect to the Lagrange multipliers, while satisfying certain conditions.
\begin{aligned}
& \text{maximize} \quad \sum_{i=1}^{m} \alpha_i - \frac{1}{2} \sum_{i, j=1}^{m} y_i y_j \alpha_i \alpha_j \mathbf{x}_i \cdot \mathbf{x}_j \\
& \text{subject to} \quad \alpha_i \geq 0, \quad i = 1, \ldots, m \\
& \quad \quad \sum_{i=1}^{m} y_i \alpha_i = 0
\end{aligned}
This problem is a quadratic programming problem about the Lagrange multipliers $\alpha_i$ and can be solved by existing optimization algorithms.
After solving the dual problem, we also need to check whether the Karush-Kuhn-Tucker (KKT) conditions are met. The KKT conditions are the necessary conditions for the optimization problem of support vector machines, including:
- Smoothness conditions
- Stationarity conditions
- Dual feasibility conditions
- Primal feasibility conditions
If all KKT conditions are met, then the optimal solution to the original problem is found.
### 2.3.3 Code Implementation for Solving the Dual Problem
Below is a simple example code using Python's `cvxopt` library to solve the SVM dual problem:
```python
import numpy as np
from cvxopt import matrix, solvers
# Training data, X is the feature matrix, y is the label vector
X = np.array([[1, 2], [2, 3], [3, 3]])
y = np.array([-1, -1, 1])
# Calculate the kernel matrix
def kernel_matrix(X, gamma=0.5):
K = np.zeros((X.shape[0], X.shape[0]))
for i in range(X.shape[0]):
for j in range(X.shape[0]):
K[i, j] = np.exp(-gamma * np.linalg.norm(X[i] - X[j]) ** 2)
return K
# Construct Lagrange multipliers
K = kernel_matrix(X)
P = matrix(np.outer(y, y) * K)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入揭秘:欧姆龙E5CZ温控表的五大核心工作原理及特性
# 摘要
本文全面介绍了欧姆龙E5CZ温控表的设计原理、操作特性以及在实际应用中的表现。首先,文章从硬件架构和关键传感器工作原理的角度,阐述了欧姆龙E5CZ的核心工作原理。接着,通过分析温度检测原理和控制算法模型,深入探讨了其控制流程,包括系统初始化、监控与调整。文章重点说明了E5CZ的主要特性,如用户界面设计、精确控制、稳定性和网络通信能力。在高级应用方面,本文讨论了自适应与预测控制技术,故障诊断与预防性维护策略,以及智能化功能的改进和行业特定解决方案。最后,提供安装调试的实践操作指导和案例研究,分享了行业应用经验和用户反馈,为读者提供改进建议和未来应用的展望。
# 关键字
欧姆龙E5CZ
【Lustre文件系统性能提升秘籍】:专家解析并行I_O与集群扩展
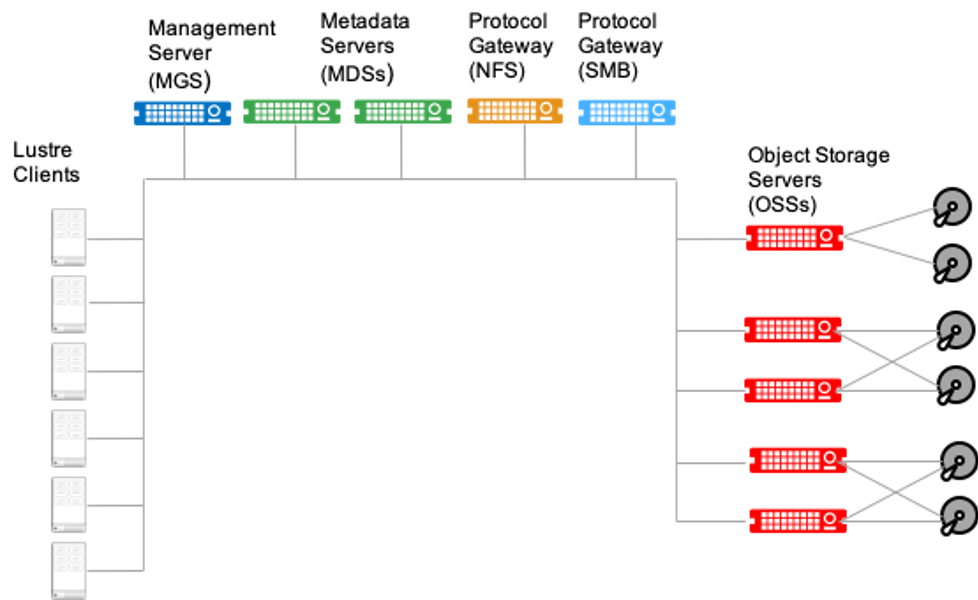
# 摘要
本文全面探讨了Lustre文件系统的基本概念、并行I/O的原理及其在Lustre中的实现,集群扩展的策略与实践,以及性能监控和调优技巧。在并行I/O部分,文章深入解析了并行I/O的定义、关键特性和性能影响因素。接着,文中详细介绍了集群扩展的基本概念,重点讨论了Lustre集群扩展的方法以及优化技巧。性能监控和调优章节则提供了实
Element UI表格头部合并教程】:打造响应式界面的关键步骤与代码解析
# 摘要
本文系统地探讨了Element UI表格头部合并的基础知识、理论基础、实践操作以及高级技巧,并通过综合案例分析来深入研究其在实际项目中的应用。文章首先介绍了响应式界面的理论基础,包括响应式设计的重要性和常用布局技术,同时阐述了Element UI框架的设计原则和组件库概述。随后,文章详细讲解了Ele
SAP安全审计核心:常用表在数据访问控制中的关键作用

# 摘要
随着企业信息化的深入发展,SAP系统作为企业资源规划的核心,其安全审计变得尤为重要。本文首先介绍了SAP安全审计的核心概念和常用数据表,阐述了数据表结构和数据访问控制的基础。通过具体案例分析,探讨了审计中数据表的应用和数据访问控制策略的制定与实施。同时,本文还提出了高级数据分析技术的应用,优化审计流程并提升安全审计的效果。最后,本文探讨了SAP安全
Cadence 16.2 库管理秘籍:最佳实践打造高效设计环境
# 摘要
本文全面介绍了Cadence 16.2版本的库管理功能和实践技巧。首先概述了库管理的基本概念和Cadence库的结构,包括设计数据的重要性、库管理的目标与原则、库的类型和层次结构等。接着,详细探讨了库文件的操作、版本控制、维护更新、安全备份以及数据共享与协作
H3C交换机SSH配置全攻略:精炼步骤、核心参数与顶级实践

# 摘要
随着网络安全要求的提高,H3C交换机的SSH配置变得尤为重要。本文旨在全面概述H3C交换机SSH配置的各个方面,包括SSH协议的基础知识、配置前的准备工作、详细配置步骤、核心参数解析,以及配置实践案例。通过理解SSH协议的安全通信原理和加密认证机制,介绍了确保交换机SSH安全运行的必要配置,如系统时间同步、本地用户管理、密钥生成和配置等。本文还分析了SSH
【CentOS 7 OpenSSH密钥管理】:密钥生成与管理的高级技巧

# 摘要
本文系统地介绍了OpenSSH的使用及其安全基础。首先概述了OpenSSH及其在安全通信中的作用,然后深入探讨了密钥生成的理论与实践,包括密钥对生成原理和OpenSSH工具的使用步骤。文章接着详细讨论了密钥管理的最佳实践、密钥轮换和备份策略,以及如何
【EMAC接口深度应用指南】:如何在AT91SAM7X256_128+中实现性能最大化
# 摘要
本文针对EMAC接口的基础知识、硬件配置、初始化过程以及网络性能调优进行了全面的探讨。首先介绍了EMAC接口基础和AT91SAM7X256_128+微控制器的相关特性。接着详细阐述了EMAC接口的硬件配置与初始化,包括接口信号、固件设置、驱动加载和初始化关键配置项。在此基础上,本文深入分析了网络性能调优策略,包括MAC地址配置、流控制、DMA传输优化、中断管理及实时性能提升。此外,还探讨了EMAC接口在多通道、QoS
viliv S5电池续航大揭秘:3个技巧最大化使用时间
# 摘要
本文针对viliv S5的电池续航能力进行了深入分析,并探讨了提高其电池性能的基础知识和实践技巧。文章首先介绍了电池的工作原理及影响viliv S5电池续航的关键因素,然后从硬件与软件优化两个层面阐述了电池管理策略。此外,本文提供了多种实践技巧来调整系统设置、应用管理及网络连接,以延长电池使用时间。文章还探讨了viliv S5电池续航的高级优化方法,包括硬件升级、第三方软件监控和电池保养维护的最佳实践。通过综合运用这些策略和技巧,用户可以显著提升viliv S5设备的电池续航能力,并优化整体使用体验。
# 关键字
电池续航;电池工作原理;电源管理;系统优化;硬件升级;软件监控
参
【回归分析深度解析】:SPSS 19.00高级统计技术,专家级解读
# 摘要
回归分析是统计学中用来确定两种或两种以上变量间相互依赖关系的统计分析方法。本文首先介绍了回归分析的基本概念及其在不同领域中的应用,接着详细说明了SPSS软件的操作界面和数据导入流程。进一步深入探讨了线性回归和多元回归分析的理论基础和实践技巧,包括模型假设、参数估计、模型诊断评估以及SPSS操作流程。最后,文章拓展到了非线性回归及其他高级回归技术的应用,展示了非线
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )