The Gold Standard for Model Selection: Mastering the Bayesian Information Criterion (BIC)
发布时间: 2024-09-15 14:22:34 阅读量: 22 订阅数: 30 

React Cookbook: Recipes for Mastering the React Framework
# The Gold Standard for Model Selection: Mastering the Bayesian Information Criterion (BIC)
In the fields of statistics and machine learning, model selection is a crucial step that involves determining which model best describes our data. The Bayesian Information Criterion (BIC) is a widely used tool in statistical modeling that provides a quantitative method to balance the goodness-of-fit of a model with its complexity. With BIC, researchers can select a model that offers the best predictive performance while considering the number of model parameters.
## 1.1 Definition and Purpose of BIC
The Bayesian Information Criterion was introduced by Gideon Schwarz in 1978, and it is a model selection criterion based on Bayesian theory. The core idea of BIC is to reduce the impact of model complexity by incorporating a specific penalty term, thus avoiding overfitting. In simple terms, BIC aims to find a model that fits the data well without being overly complex.
## 1.2 Advantages and Limitations of BIC
The benefit of using BIC lies in its simplicity and effectiveness in many application scenarios. BIC does not require a complex cross-validation process, hence it is computationally efficient. However, BIC also has limitations, such as assuming that the true distribution of model parameters is close to normal, and it is more suitable for situations with a larger sample size. When the sample size is small, BIC may not be the best choice.
The calculation and use of BIC will be discussed in detail in subsequent sections, but first, let's explore the profound foundation of Bayesian theory to provide the necessary theoretical support for a deeper understanding of BIC.
# 2. The Foundation of Bayesian Theory
## 2.1 A Brief History of Bayes' Theorem
### 2.1.1 The Origin and Development of Bayes' Theorem
Bayes' Theorem was first introduced by the British mathematician Thomas Bayes. The origin of the theorem can be traced back to the 18th century, but its true influence and importance were recognized in the 20th century, especially in the fields of statistics and machine learning. The theorem was proposed to solve the problem of how to make reasonable inferences in uncertain situations. Bayes' Theorem provides a method to update beliefs by combining prior information with new observations.
Bayes' Theorem was initially published in an article titled "An Essay towards solving a Problem in the Doctrine of Chances" after Bayes' death, which was edited and published by his friend Richard Price. Bayes' method was in stark contrast to the then-popular frequentist approach, which focused more on long-term frequencies and large-sample behavior.
In the following decades, Bayes' Theorem did not receive much attention in the statistical community until the second half of the 20th century, when the development of computer technology made complex Bayesian calculations possible. This allowed Bayesian methods to make significant theoretical and practical advancements. Bayesian statisticians developed various computational methods, especially Markov chain Monte Carlo (MCMC) methods, which greatly expanded the scope and influence of Bayesian methods.
### 2.1.2 The Role of Bayes' Theorem in Statistics
Today, Bayes' Theorem holds an extremely important position in statistics. It is not only a tool for statistical inference but also a way of thinking. The core of Bayesian methods is to use probability to express uncertainty and update beliefs through new information. This approach has shown its flexibility and practicality in many situations, especially when dealing with small-sample data and highly uncertain problems.
Bayes' Theorem is widely applied in various scientific fields, such as economics, medicine, biology, and engineering, and it has found significant applications in machine learning, such as Bayesian networks, naive Bayes classifiers, etc. Bayesian methods provide strong theoretical support for dealing with uncertainty and conducting complex data analysis.
In terms of statistical inference, Bayesian methods allow us to quantify uncertainty and reach conclusions in the form of probabilities, complementing the results of the frequentist school. In practical applications, Bayesian methods make models more flexible and adaptable by considering prior knowledge.
## 2.2 The Mathematical Principles of Bayesian Inference
### 2.2.1 Probability Distributions and Prior Probabilities
In Bayesian inference, probability distributions are a form of expressing uncertainty. The stochastic process of data generation is described by probability distributions, and the uncertainty of these distribution parameters is expressed through prior probabilities. Prior probabilities are based on prior knowledge or beliefs and quantify our subjective beliefs about parameters before observing any data.
Prior probabilities can be non-informative (e.g., uniform distribution or Jeffreys prior) or informative (based on specific domain knowledge or previous research). The choice of prior can significantly affect the posterior distribution, so in practical applications, the choice of prior often needs to be made carefully to ensure its reasonableness and applicability.
### 2.2.2 Methods for Calculating Posterior Distributions
The posterior distribution is the conditional probability distribution of parameters after observing the data. It combines prior probabilities and the likelihood function (evidence of data for model parameters), which is calculated using Bayes' Theorem. The core formula of Bayes' Theorem is as follows:
\[ P(\theta | X) = \frac{P(X | \theta) P(\theta)}{P(X)} \]
Where \( P(\theta | X) \) is the posterior distribution, \( P(X | \theta) \) is the likelihood function, \( P(\theta) \) is the prior distribution, and \( P(X) \) is the marginal likelihood (evidence).
Calculating the posterior distribution often involves solving high-dimensional integrals, which is a computational challenge. This is especially true when dealing with a large amount of data or complex models, direct computation is impractical. At this point, we often resort to numerical methods such as Monte Carlo simulation, Markov chain Monte Carlo (MCMC) methods, or variational inference for approximate solutions.
### 2.2.3 An Example Analysis of Bayesian Inference
To more specifically understand the process of Bayesian inference, let's consider a simple example: the coin toss problem. Suppose we want to determine whether a coin is fair, that is, to judge whether the probability of heads is 0.5.
We first set a prior distribution. Since the manufacturing process of a coin usually makes it close to fair, we can assume a symmetric Beta distribution, such as Beta(2,2), as the prior. The Beta distribution is the conjugate prior of the binomial distribution, which means the posterior distribution is also a Beta distribution.
We then conduct an experiment, tossing the coin 10 times, with the result being 5 heads and 5 tails. The likelihood function can be expressed as a binomial form, that is, \( P(X = k | \theta) = {n \choose k} \theta^k (1-\theta)^{n-k} \), where \( n \) is the total number of tosses, \( k \) is the number of heads, and \( \theta \) is the true probability of heads.
According to Bayes' Theorem, we can calculate the posterior distribution as:
\[ P(\theta | X = 5) = \frac{P(X = 5 | \theta) P(\theta)}{P(X = 5)} \]
We can use integration techniques or numerical methods to calculate this posterior distribution. Here we omit the calculation steps and directly give the result. Through calculation, it can be found that the posterior distribution has been significantly adjusted relative to the prior, more concentrated around 0.5, indicating that the data has influenced our beliefs.
Bayesian inference demonstrates its unique advantages through this process: it not only provides a point estimate of parameters (such as taking the mean of the posterior distribution) but also provides a complete probability distribution, which can be used to further calculate confidence intervals or other probabilistic judgments for parameters.
Next, we will delve into the theoretical framework of the Bayesian Information Criterion (BIC), its important applications in Bayesian inference, and how it helps us solve the problem of model selection.
# 3. Theoretical Framework of the Bayesian Information Criterion (BIC)
## 3.1 Definition and Mathematical Expression of BI

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘ETA6884移动电源的超速充电:全面解析3A充电特性

# 摘要
本文详细探讨了ETA6884移动电源的技术规格、充电标准以及3A充电技术的理论与应用。通过对充电技术的深入分析,包括其发展历程、电气原理、协议兼容性、安全性理论以及充电实测等,我们提供了针对ETA6884移动电源性能和效率的评估。此外,文章展望了未来充电技术的发展趋势,探讨了智能充电、无线充电以
【编程语言选择秘籍】:项目需求匹配的6种语言选择技巧

# 摘要
本文全面探讨了编程语言选择的策略与考量因素,围绕项目需求分析、性能优化、易用性考量、跨平台开发能力以及未来技术趋势进行深入分析。通过对不同编程语言特性的比较,本文指出在进行编程语言选择时必须综合考虑项目的特定需求、目标平台、开发效率与维护成本。同时,文章强调了对新兴技术趋势的前瞻性考量,如人工智能、量子计算和区块链等,以及编程语言如何适应这些技术的变化。通
【信号与系统习题全攻略】:第三版详细答案解析,一文精通

# 摘要
本文系统地介绍了信号与系统的理论基础及其分析方法。从连续时间信号的基本分析到频域信号的傅里叶和拉普拉斯变换,再到离散时间信号与系统的特性,文章深入阐述了各种数学工具如卷积、
微波集成电路入门至精通:掌握设计、散热与EMI策略

# 摘要
本文系统性地介绍了微波集成电路的基本概念、设计基础、散热技术、电磁干扰(EMI)管理以及设计进阶主题和测试验证过程。首先,概述了微波集成电路的简介和设计基础,包括传输线理论、谐振器与耦合结构,以及高频电路仿真工具的应用。其次,深入探讨了散热技术,从热导性基础到散热设计实践,并分析了散热对电路性能的影响及热管理的集成策略。接着,文章聚焦于EMI管理,涵盖了EMI基础知识、
Shell_exec使用详解:PHP脚本中Linux命令行的实战魔法

# 摘要
本文详细探讨了PHP中的Shell_exec函数的各个方面,包括其基本使用方法、在文件操作与网络通信中的应用、性能优化以及高级应用案例。通过对Shell_exec函数的语法结构和安全性的讨论,本文阐述了如何正确使用Shell_exec函数进行标准输出和错误输出的捕获。文章进一步分析了Shell_exec在文件操作中的读写、属性获取与修改,以及网络通信中的Web服
NetIQ Chariot 5.4高级配置秘籍:专家教你提升网络测试效率

# 摘要
NetIQ Chariot是网络性能测试领域的重要工具,具有强大的配置选项和高级参数设置能力。本文首先对NetIQ Chariot的基础配置进行了概述,然后深入探讨其高级参数设置,包括参数定制化、脚本编写、性能测试优化等关键环节。文章第三章分析了Net
【信号完整性挑战】:Cadence SigXplorer仿真技术的实践与思考
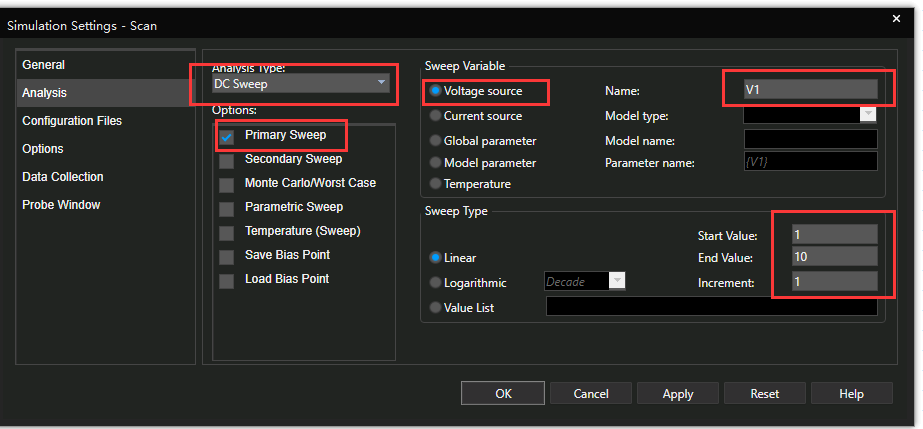
# 摘要
本文全面探讨了信号完整性(SI)的基础知识、挑战以及Cadence SigXplorer仿真技术的应用与实践。首先介绍了信号完整性的重要性及其常见问题类型,随后对Cadence SigXplorer仿真工具的特点及其在SI分析中的角色进行了详细阐述。接着,文章进入实操环节,涵盖了仿真环境搭建、模型导入、仿真参数设置以及故障诊断等关键步骤,并通过案例研究展示了故障诊断流程和解决方案。在高级
【Python面向对象编程深度解读】:深入探讨Python中的类和对象,成为高级程序员!

# 摘要
本文深入探讨了面向对象编程(OOP)的核心概念、高级特性及设计模式在Python中的实现和应用。第一章回顾了面向对象编程的基础知识,第二章详细介绍了Python类和对象的高级特性,包括类的定义、继承、多态、静态方法、类方法以及魔术方法。第三章深入讨论了设计模式的理论与实践,包括创建型、结构型和行为型模式,以及它们在Python中的具体实现。第四
Easylast3D_3.0架构设计全解:从理论到实践的转化
# 摘要
Easylast3D_3.0是一个先进的三维设计软件,其架构概述及其核心组件和理论基础在本文中得到了详细阐述。文中详细介绍了架构组件的解析、设计理念与原则以及性能评估,强调了其模块间高效交互和优化策略的重要性。
【提升器件性能的秘诀】:Sentaurus高级应用实战指南

# 摘要
Sentaurus是一个强大的仿真工具,广泛应用于半导体器件和材料的设计与分析中。本文首先概述了Sentaurus的工具基础和仿真环境配置,随后深入探讨了其仿真流程、结果分析以及高级仿真技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )