Model Interpretability and Evaluation: Balancing Complexity with Interpretability
发布时间: 2024-09-15 14:24:51 阅读量: 27 订阅数: 26 
# 1. The Importance of Model Interpretability and Evaluation
In the realm of data science today, the performance of machine learning models is crucial, but so is their interpretability. Model interpretability refers to the ability to understand the reasons and processes behind a model's specific predictions or decisions. Its importance stems from several aspects:
- **Trust Building**: In critical application areas, such as healthcare and finance, the transparency of models can enhance trust among users and regulatory bodies.
- **Error Diagnosis**: Interpretability helps us identify and correct errors in the model, optimizing its performance.
- **Compliance Requirements**: Many industries have regulatory requirements that mandate the ability to explain the decision-making process of models to comply with legal stipulations.
To ensure model interpretability, it is necessary to establish and employ various evaluation methods and metrics to monitor and enhance model performance. These methods and metrics span every step from data preprocessing to model deployment, ensuring that while models pursue predictive accuracy, they also provide clear and understandable decision logic. In the following sections, we will delve into the theoretical foundations of model interpretability, different types of interpretation methods, and specific techniques for evaluating model performance.
# 2. Theoretical Foundations and Model Complexity
### 2.1 Theoretical Framework of Model Interpretability
#### 2.1.1 What is Model Interpretability
Model interpretability refers to the transparency and understandability of model predictions, that is, the ability to clearly explain to users how a model makes specific predictions. In the field of artificial intelligence, models are often viewed as "black boxes" because they typically contain complex parameters and structures that make it difficult for laypeople to understand their internal mechanisms. The importance of interpretability not only lies in increasing the transparency of the model but is also crucial for increasing user trust in model outcomes, diagnosing errors, and enhancing the reliability of the model.
#### 2.1.2 The Relationship Between Interpretability and Model Complexity
Model complexity is an important indicator for measuring a model's predictive power, learning efficiency, ***plex models, such as deep neural networks, excel at handling nonlinear problems but are difficult to understand internally, increasing their lack of interpretability. On the other hand, simpler models, such as linear regression models, are more intuitive but may perform inadequately when dealing with complex patterns. Ideally, models should maintain sufficient complexity to achieve the desired performance while also striving to improve their interpretability.
### 2.2 Measures of Model Complexity
#### 2.2.1 Time Complexity and Space Complexity
Time complexity and space complexity are two primary indicators for measuring the resource consumption of algorithms. Time complexity describes the trend of growth in the time required for an algorithm to execute as the input scale increases, commonly expressed using Big O notation. Space complexity is a measure of the amount of storage space an algorithm uses during execution. For machine learning models, time complexity is typically reflected in training and prediction times, while space complexity is evident in model size and storage requirements. When selecting models, in addition to considering model performance, it is also necessary to balance the constraints of time and space.
#### 2.2.2 Model Capacity and Generalization Ability
Model capacity refers to the ability of a model to capture complex patterns in data. High-capacity models (e.g., deep neural networks) can fit complex functions but are at high risk of overfitting, potentially performing poorly when generalizing to unknown data. The level of model capacity is determined not only by the model structure but also by the number of model parameters, the choice of activation functions, etc. Generalization ability refers to the model's predictive power for unseen examples. The complexity of the model needs to match its generalization ability to ensure that the model not only memorizes the training data but also learns the underlying patterns in the data.
### 2.3 The Relationship Between Complexity and Overfitting
#### 2.3.1 Causes and Consequences of Overfitting
Overfitting occurs when a model learns the training data too well, capturing noise and details that are not universally applicable in new, unseen data. Overfitting typically occurs when the model capacity is too high or when there is insufficient training data. The consequence is that the model performs well on the training set but significantly worse on validation or test sets. Overfitting not only affects the predictive accuracy of the model but also reduces its generalization ability, resulting in unreliable predictions when applied in practice.
#### 2.3.2 Strategies to Avoid Overfitting
There are various strategies to avoid overfitting, including but not limited to: increasing the amount of training data, data augmentation, reducing model complexity, introducing regularization terms, using cross-validation, and early stopping of training. These strategies help balance the learning and generalization abilities of the model to varying degrees. For instance, regularization techniques add a penalty term (e.g., L1, L2 regularization) to limit the size of model parameters, thus preventing the model from fitting too closely to the training data. These methods can improve the generalization ability of the model and reduce the risk of overfitting.
In the next chapter, we will delve deeper into interpretability methods and techniques and discuss how to apply these technologies to enhance the transparency and interpretability of models. We will first introduce local interpretability methods, such as LIME and SHAP, then move on to global interpretability methods, such as model simplification and rule-based interpretation frameworks. Finally, we will discuss model visualization techniques and how these technologies help us understand the working principles of models more intuitively.
# 3. Interpretability Methods and Techniques
## 3.1 Local Interpretability Methods
### 3.1.1 Principles and Applications of LIME and SHAP
Local Interpretable Model-agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP) are two popular local interpretability methods that help understand a model's behavior on specific instances by providing a succinct explanation for each prediction.
The core idea of LIME is to approximate the predictive behavior of the original model within the local space of an instance. It learns a simplified model that captures the behavior of the original model in that local by perturbing the input data and observing the changes in output. It is applicable to any model, including tabular and image data.
```python
from lime import LimeTabularExplainer
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# Load dataset
data = load_iris()
X, y = data.data, data.target
# Train a random forest model as the black box model
model = RandomForestClassifier()
model.fit(X, y)
# Create a LIME explainer
explainer = LimeTabularExplainer(X, feature_names=data.feature_names, class_names=data.target_names)
# Select a data point for explanation
idx = 10
exp = explainer.explain_instance(X[idx], model.predict_proba, num_features=4)
exp.show_in_notebook(show_table=True, show_all=False)
```
In the code above, we first load the Iris dataset and train a random forest classifier. Then we create a `LimeTabularExplainer` instance and use it to explain the prediction results of the 11th sample in the dataset.
SHAP is a method based on game theory that uses the average marginal contribution of the feature value function to explain predictions. SHAP values assign a value to each feature, indicating the contribution of that feature to the prediction result.
```python
import shap
import numpy as np
# Use SHAP's TreeExplainer, designed for tree models
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
# Visualize the SHAP values for the first prediction
shap.initjs()
shap.force_plot(explainer.expected_value[0], shap_values[0][idx,:], X[idx,:])
```
In this code snippet, we use the `TreeExplainer` to calculate the SHAP values for each sample and then use the `force_plot` method to generate an interactive visualization chart that shows the contribution of the model to the specific sample's prediction result.
### 3.1.2 Feature Importance Assessment Techniques
Feature importance is a core concept in model interpretability that helps us understand which features play a key role in model predictions. There are various methods to assess feature importance, including model-specific methods (such as feature importance from random forests) and model-agnostic methods (such as permutation importance).
```python
import eli5
from sklearn.ensemble import RandomForestClassifier
# Use the eli5 library to compute feature importance
perm = eli5.permutation_importance(model, X, y, n_iter=100)
eli5.show_weights(perm, feature_names=data.feature_names, show_stdv=True)
```
Here, we use the `eli5` library's `permutation_importance` function to compute the permutation importance of the model and use the `sho

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【目标变量优化】:机器学习中因变量调整的高级技巧
# 1. 目标变量优化概述
在数据科学和机器学习领域,目标变量优化是提升模型预测性能的核心步骤之一。目标变量,又称作因变量,是预测模型中希望预测或解释的变量。通过优化目标变量,可以显著提高模型的精确度和泛化能力,进而对业务决策产生重大影响。
## 目标变量的重要性
目标变量的选择与优化直接关系到模型性能的好坏。正确的目标变量可以帮助模
【Python预测模型构建全记录】:最佳实践与技巧详解
# 1. Python预测模型基础
Python作为一门多功能的编程语言,在数据科学和机器学习领域表现得尤为出色。预测模型是机器学习的核心应用之一,它通过分析历史数据来预测未来的趋势或事件。本章将简要介绍预测模型的概念,并强调Python在这一领域中的作用。
## 1.1 预测模型概念
预测模型是一种统计模型,它利用历史数据来预测未来事件的可能性。这些模型在金融、市场营销、医疗保健和其
探索与利用平衡:强化学习在超参数优化中的应用
# 1. 强化学习与超参数优化的交叉领域
## 引言
随着人工智能的快速发展,强化学习作为机器学习的一个重要分支,在处理决策过程中的复杂问题上显示出了巨大的潜力。与此同时,超参数优化在提高机器学习模型性能方面扮演着关键角色。将强化学习应用于超参数优化,不仅可实现自动化,还能够通过智能策略提升优化效率,对当前AI领域的发展产生了深远影响。
## 强化学习与超参数优化的关系
强化学习能够通过与环境的交互来学
【生物信息学中的LDA】:基因数据降维与分类的革命
# 1. LDA在生物信息学中的应用基础
## 1.1 LDA的简介与重要性
在生物信息学领域,LDA(Latent Dirichlet Allocation)作为一种高级的统计模型,自其诞生以来在文本数据挖掘、基因表达分析等众多领域展现出了巨大的应用潜力。LDA模型能够揭示大规模数据集中的隐藏模式,有效地应用于发现和抽取生物数据中的隐含主题,这使得它成为理解复杂生物信息和推动相关研究的重要工具。
## 1.2 LDA在生物信息学中的应用场景
模型参数泛化能力:交叉验证与测试集分析实战指南

# 1. 交叉验证与测试集的基础概念
在机器学习和统计学中,交叉验证(Cross-Validation)和测试集(Test Set)是衡量模型性能和泛化能力的关键技术。本章将探讨这两个概念的基本定义及其在数据分析中的重要性。
## 1.1 交叉验证与测试集的定义
交叉验证是一种统计方法,通过将原始数据集划分成若干小的子集,然后将模型在这些子集上进行训练和验证,以
机器学习模型验证:自变量交叉验证的6个实用策略
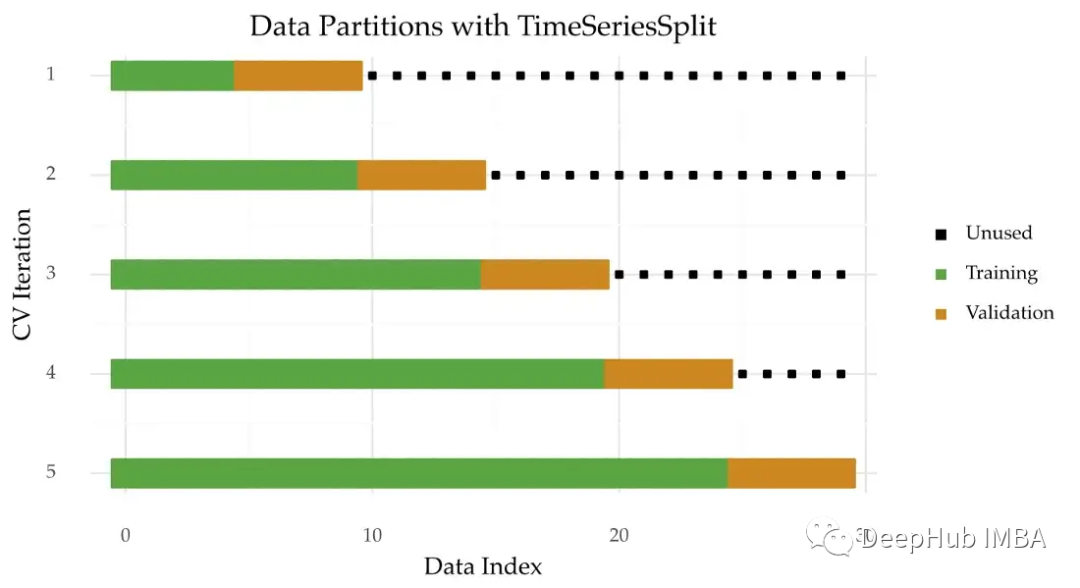
# 1. 交叉验证在机器学习中的重要性
在机器学习和统计建模中,交叉验证是一种强有力的模型评估方法,用以估计模型在独立数据集上的性能。它通过将原始数据划分为训练集和测试集来解决有限样本量带来的评估难题。交叉验证不仅可以减少模型因随机波动而导致的性能评估误差,还可以让模型对不同的数据子集进行多次训练和验证,进而提高评估的准确性和可靠性。
## 1.1 交叉验证的目的和优势
交叉验证
【从零开始构建卡方检验】:算法原理与手动实现的详细步骤
# 1. 卡方检验的统计学基础
在统计学中,卡方检验是用于评估两个分类变量之间是否存在独立性的一种常用方法。它是统计推断的核心技术之一,通过观察值与理论值之间的偏差程度来检验假设的真实性。本章节将介绍卡方检验的基本概念,为理解后续的算法原理和实践应用打下坚实的基础。我们将从卡方检验的定义出发,逐步深入理解其统计学原理和在数据分析中的作用。通过本章学习,读者将能够把握卡方检验在统计学中的重要性
贝叶斯优化:智能搜索技术让超参数调优不再是难题
# 1. 贝叶斯优化简介
贝叶斯优化是一种用于黑盒函数优化的高效方法,近年来在机器学习领域得到广泛应用。不同于传统的网格搜索或随机搜索,贝叶斯优化采用概率模型来预测最优超参数,然后选择最有可能改进模型性能的参数进行测试。这种方法特别适用于优化那些计算成本高、评估函数复杂或不透明的情况。在机器学习中,贝叶斯优化能够有效地辅助模型调优,加快算法收敛速度,提升最终性能。
接下来,我们将深入探讨贝叶斯优化的理论基础,包括它的工作原理以及如何在实际应用中进行操作。我们将首先介绍超参数调优的相关概念,并探讨传统方法的局限性。然后,我们将深入分析贝叶斯优化的数学原理,以及如何在实践中应用这些原理。通过对
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
多变量时间序列预测区间:构建与评估

# 1. 时间序列预测理论基础
在现代数据分析中,时间序列预测占据着举足轻重的地位。时间序列是一系列按照时间顺序排列的数据点,通常表示某一特定变量随时间变化的情况。通过对历史数据的分析,我们可以预测未来变量的发展趋势,这对于经济学、金融、天气预报等诸多领域具有重要意义。
## 1.1 时间序列数据的特性
时间序列数据通常具有以下四种主要特性:趋势(Tre
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )