Assessing Model Generalization Capability: The Right Approach to Cross-Validation
发布时间: 2024-09-15 14:20:04 阅读量: 29 订阅数: 30 

FUNNEL: Assessing Software Changes in Web-based Services
# The Importance and Challenges of Model Generalization Capability
In the process of building machine learning models, a key criterion for success is whether a model performs well on unknown data. This ability to make correct predictions on unseen data is known as the model's generalization capability. However, as model complexity increases, a common problem—overfitting—emerges, challenging the model's generalization capability.
Overfitting occurs when a model fits too well to the training data, capturing noise and details that cannot be generalized to new datasets. This leads to decreased performance in real-world applications, as the model fails to correctly identify new features in the data.
To enhance model generalization and address overfitting, cross-validation has become an effective strategy. By dividing the dataset into training and validation sets, cross-validation helps us evaluate the model's performance more accurately under limited data conditions. This chapter will explore the importance of generalization capability, the problem of overfitting, and the relevant theories of cross-validation, laying a solid foundation for subsequent practical operations and advanced applications.
# Theoretical Foundations of Cross-Validation
## Concepts of Generalization Capability and Overfitting
### Definition of Generalization Capability
Generalization capability is an important indicator of machine learning model performance, referring to the model's predictive performance on unseen examples. A model with strong generalization capability can learn the essential patterns from the training data and generalize well to new, unknown data. The ideal model should perform well on both the training and test sets, but this is often difficult to achieve in practice.
In machine learning, we strive for a state where the model does not overfit to the training data and yet maintains sufficient complexity to capture the true patterns of the data, thus possessing good generalization capability.
### Causes and Impacts of Overfitting
Overfitting refers to a model performing well on the training set but poorly on new, independent test sets. There are various causes, including but not limited to the following:
1. Excessive model complexity: The model may have too many parameters, exceeding the amount of information that the actual data can provide, leading the model to memorize noise and details in the training data.
2. Insufficient training data: When the training data is relatively less than the model parameters, the model cannot generalize to new data.
3. Improper feature selection: Including irrelevant features or omitting important ones can lead to overfitting.
4. Excessive training time: Prolonged training may cause the model to overfit to the training data rather than learning generalized rules.
Overfitting results in low accuracy in real-world applications, poor generalization performance, and poor performance on unseen data. This is an issue we need to pay special attention to and try to avoid when using cross-validation.
## Principles of Cross-Validation
### Division of Training and Test Sets
In machine learning, datasets are typically divided into training, validation, and test sets. The training set is used for the model training process, the validation set is used for adjusting model hyperparameters and preventing overfitting, and the test set is used for evaluating the final model performance.
The principle of cross-validation is based on dividing the dataset into multiple smaller training and test sets to increase the number of model training and validation iterations, allowing for a more comprehensive assessment of the model's generalization capability.
### Objectives and Benefits of Cross-Validation
The main objectives of cross-validation are:
1. To reduce the variance of model evaluation and provide a more accurate estimate of model performance.
2. To make full use of limited data for effective training and evaluation.
The benefits of cross-validation include:
1. Improved accuracy of model evaluation: By dividing the data multiple times, the fluctuation of evaluation results due to different data divisions can be reduced.
2. Rational use of data resources: In cases where the amount of data is limited, cross-validation ensures that all data is used for model training and evaluation.
3. Reduction of bias in model selection: Helps to compare different models or algorithms more fairly.
## Overview of Common Cross-Validation Methods
### Leave-One-Out (LOO)
Leave-One-Out Cross-Validation (LOO) is an extreme form of cross-validation where the model is trained on all data except the current sample and then used to predict the current sample. This process is repeated n times, where n is the total number of samples, resulting in n model prediction results.
The advantages and disadvantages of LOO are as follows:
**Advantages:**
- For datasets with a small amount of data, LOO can make maximum use of the data.
- Each sample is predicted by a model trained on almost the entire dataset, making the evaluation results more reliable.
**Disadvantages:**
- Computation costs are very high. Since the model needs to be trained n times, the computational overhead is significant when the data size n is large.
- May be influenced by outliers.
### K-Fold Cross-Validation
K-Fold cross-validation divides the dataset into K equally sized, mutually exclusive subsets, with each subset maintaining consistent data distribution as much as possible. Then, K model training and evaluation processes are performed, each time choosing one subset as the test set and the rest as the training set. Finally, the model's performance is evaluated based on the average of these K test results.
The main parameter for K-Fold cross-validation is the number of folds K, common choices include 3, 5, 10, etc. Choosing the appropriate K value is crucial, requiring a balance between computational cost and evaluation accuracy.
### Stratified K-Fold Cross-Validation
Stratified K-Fold cross-validation takes into account the class distribution in the dataset on the basis of K-Fold cross-validation. After dividing the dataset into K subsets, it ensures that the proportion of each class in each subset is roughly the same. This is particularly effective for problems of class imbalance.
Stratified K-Fold cross-validation is suitable for situations where the label class distribution in the dataset is uneven, ensuring that each class can be reasonably evaluated in different folds, thus improving the model's generalization capability.
In this chapter, we have understood the theoretical foundations of cross-validation, including the definition of generalization capability, the causes and impacts of overfitting, the principles, objectives, and benefits of cross-validation, and common cross-validation methods. These theoretical knowledge are the basis for performing cross-validation operations and are also key to further understanding and practicing cross-validation.
The next section will continue to delve into the practical operations of cross-validation, including specific implementation steps and the selection and application of evaluation metrics, and demonstrate how to apply cross-validation methods in practice through code implementation.
# Practical Operations of Cross-Validation
## Steps for Implementing Cross-Validation
### Preprocessing of Data
Data preprocessing is the first step of cross-validation and a key step that determines model performance. In practical applications, data preprocessing includes cleaning data, handling missing values, standardizing or normalizing data, feature selection and extraction, and splitting the dataset.
Specific operational steps include:
- Cleaning data: Removing or filling in outliers, handling duplicate records, etc.
- Handling missing values: Filling in with means, medians, or more complex algorithms to predict missing values.
- Feature transformation: Standardizing or normalizing data, such as using min-max normalization or Z-score standardization, to reduce the impact of different dimensional features on the model.
- Feature selection: Using methods such as Principal Component Analysis (PCA) for feature dimensionality reduction.
The splitting o

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【OBDD技术深度剖析】:硬件验证与软件优化的秘密武器

# 摘要
有序二元决策图(OBDD)是一种广泛应用于硬件验证、软件优化和自动化测试的高效数据结构。本文首先对OBDD技术进行了概述,并深入探讨了其理论基础,包括基本概念、数学模型、结构分析和算法复杂性。随后,本文重点讨论了OBDD在硬件验证与软件优化领域的具体应用,如规范表示、功能覆盖率计算、故障模拟、逻辑分析转换、程序验证和测试用例生成。最后,文章分析了OBDD算法在现代
【微服务架构的挑战与对策】:从理论到实践
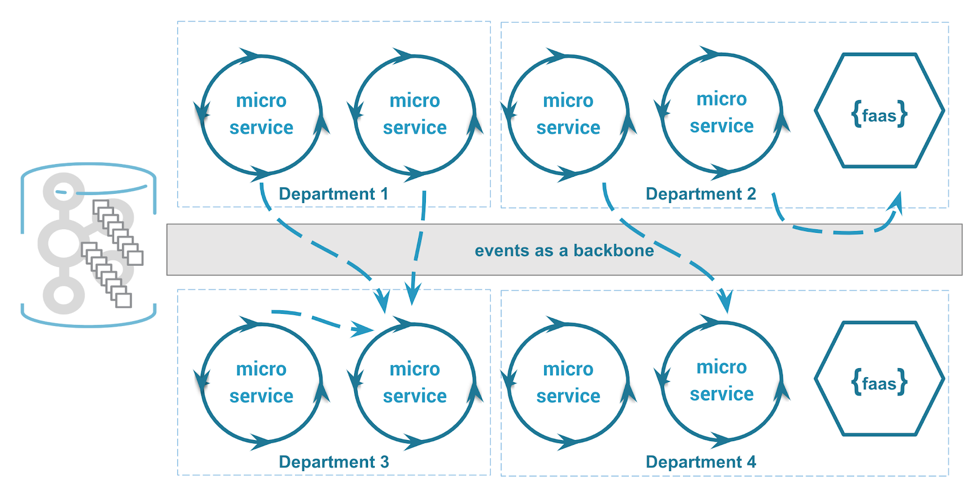
# 摘要
微服务架构作为一种现代化的软件架构方式,通过服务的划分和分布式部署,提高了应用的灵活性和可扩展性。本文从基本概念和原则出发,详细探讨了微服务架构的技术栈和设计模式,包括服务注册与发现、负载均衡、通信机制以及设计模式。同时,文章深入分析了实践中的挑战,如数据一致性、服务治理、安全问题等。在优化策略方面,本文讨论了性能、可靠性和成本控制的改进方法。最后,文章展望了微服务架构的未来趋势,包括服
RadiAnt DICOM Viewer错误不再难:专家解析常见问题与终极解决方案
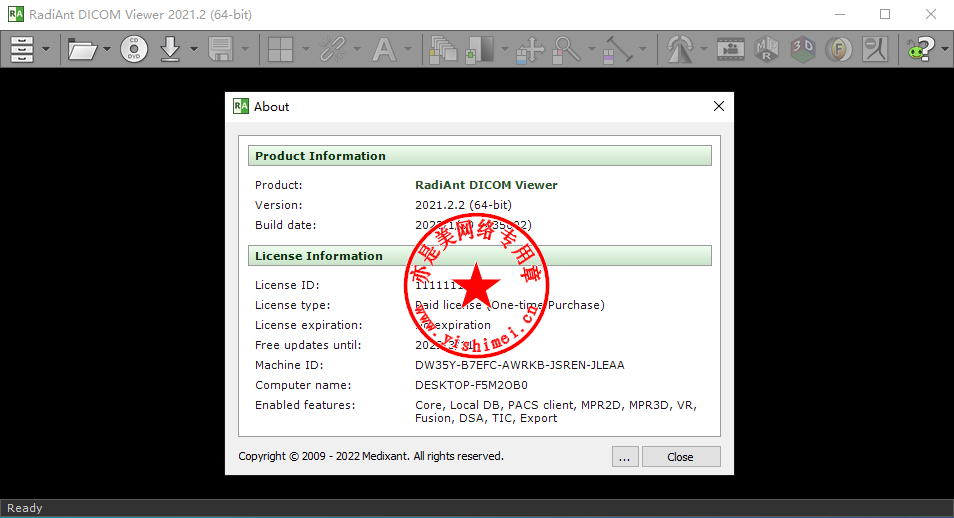
# 摘要
本文对RadiAnt DICOM Viewer这款专业医学影像软件进行了全面的介绍与分析。首先概述了软件的基本功能和常见使用问题,接着深入探讨了软件的错误分析和解决策略,包括错误日志的分析方法、常见错误原因以及理论上的解决方案。第四章提供了具体的终极解决方案实践,包括常规问题和高级问题的解决步骤、预防措施与最佳实践。最后,文章展望了软件未来的优化建议和用户交互提升策略,并预测了技术革新和行业应
macOS用户必看:JDK 11安装与配置的终极指南

# 摘要
本文全面介绍了JDK 11的安装、配置、高级特性和性能调优。首先概述了JDK 11的必要性及其新特性,强调了其在跨平台安装和环境变量配置方面的重要性。随后,文章深入探讨了配置IDE和使用JShell进行交互式编程的实践技巧,以及利用Maven和Gradle构建Java项目的具体方法。在高级特性部分,本文详细介绍了新HTTP Client API的使用、新一代垃圾收集器的应用,以及
华为产品开发流程揭秘:如何像华为一样质量与效率兼得
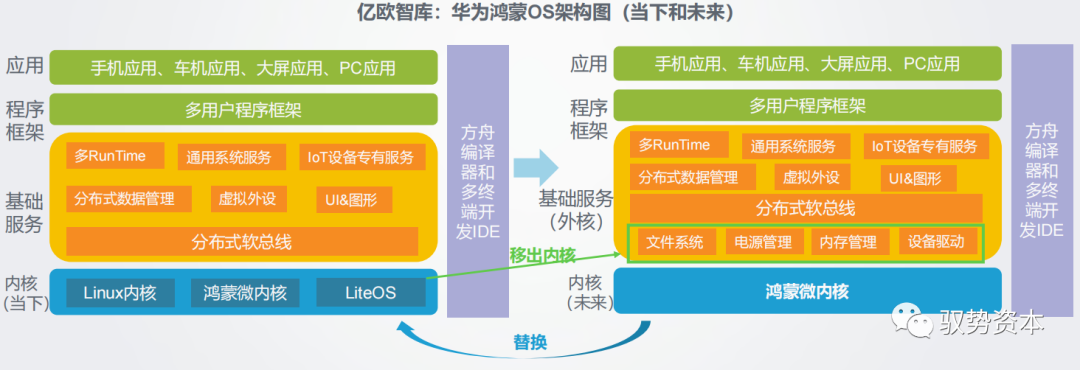
# 摘要
本文详细探讨了华为公司产品开发流程的理论与实践,包括产品生命周期管理理论、集成产品开发(IPD)理论及高效研发组织结构理论的应用。通过对华为市场需求分析、产品规划、项目管理、团队协作以及质量控制和效率优化等关键环节的深入分析,揭示了华为如何通过其独特的开发流程实现产品创新和市场竞争力的提升。本文还着重评估了华为产品的
无线通信深度指南:从入门到精通,揭秘信号衰落与频谱效率提升(权威实战解析)
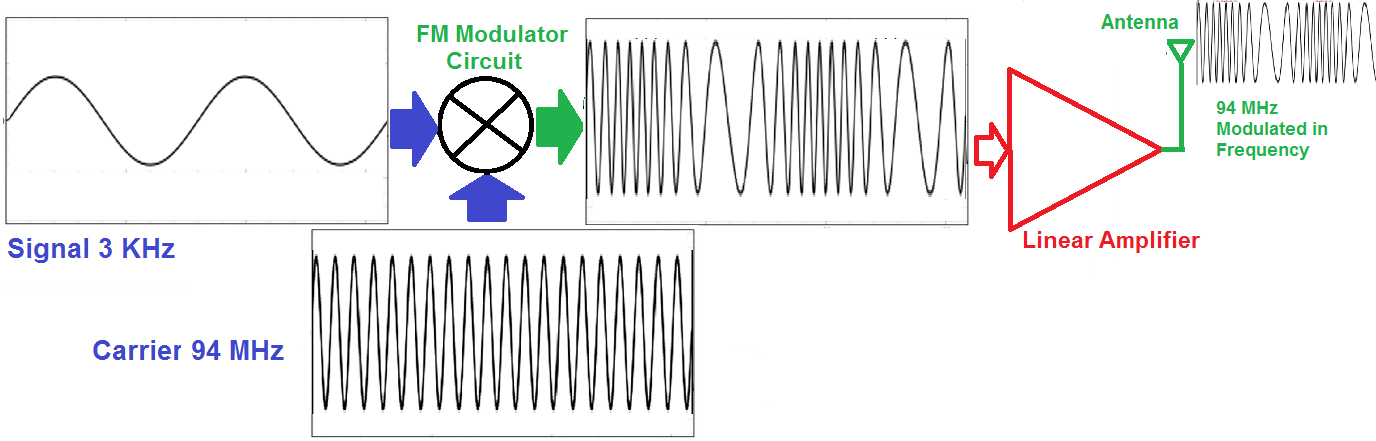
# 摘要
本文深入探讨了无线通信中的频谱效率和信号衰落问题,从基础理论到实用技术进行了全面分析。第一章介绍了无线通信基础及信号衰落现象,阐述了无线信号的传播机制及其对通信质量的影响。第二章聚焦于频谱效率提升的理论基础,探讨了提高频谱效率的策略与方法。第三章则详细讨论了信号调制与解调技
【HOMER最佳实践分享】:行业领袖经验谈,提升设计项目的成功率

# 摘要
本文全面介绍了HOMER项目管理的核心概念、理论基础、实践原则、设计规划技巧、执行监控方法以及项目收尾与评估流程。首先概述了HOMER项目的管理概述,并详细阐释了其理论基础,包括生命周期模型和框架核心理念。实践原则部分强调了明确目标、资源优化和沟通的重要性。设计与规划技巧章节则深入探讨了需求分析、设计方案的迭代、风险评估与应对策略。执行与监控部分着重于执行计划、团队协作、进度跟踪、成本控制和问题解决。最后,在项目收尾与评估章节中,本文涵盖了交付流
【SCSI Primary Commands的终极指南】:SPC-5基础与核心概念深度解析
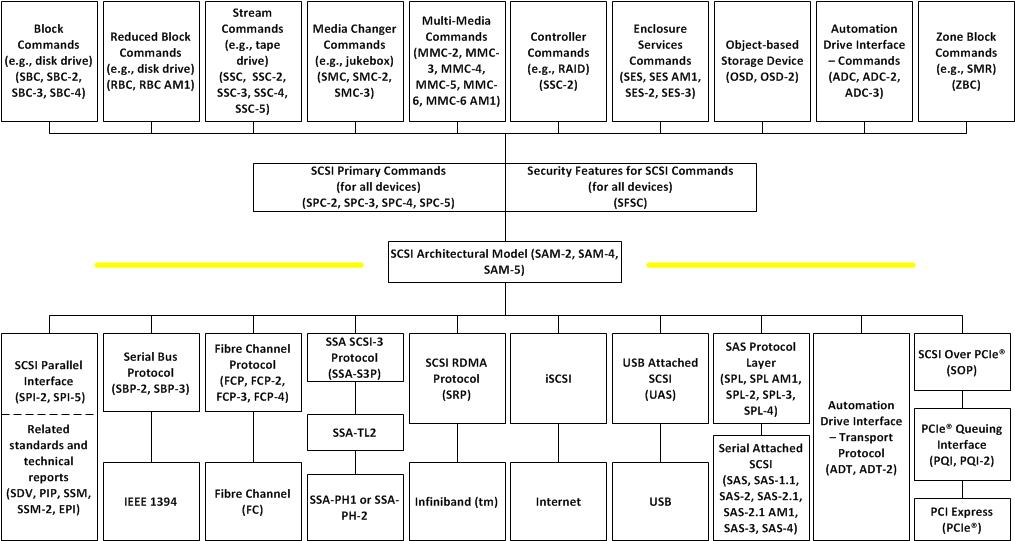
# 摘要
本文系统地探讨了SCSI协议与SPC标准的发展历程、核心概念、架构解析以及在现代IT环境中的应用。文章详细阐述了SPC-5的基本概念、命令模型和传输协议,并分析了不同存储设备的特性、LUN和目标管理,以及数据保护与恢复的策略。此外,本文还讨论了SPC-5在虚拟化环境、云存储中的实施及其监控与诊断工具,展望了SPC-5的技术趋势、标准化扩展和安全性挑战,为存储协议的发展和应用提供了深入的见解。
# 关键字
SCSI协议;S
【工业自动化新星】:CanFestival3在自动化领域的革命性应用

# 摘要
CanFestival3作为一款流行的开源CANopen协议栈,在工业自动化领域扮演着关键角色。本文首先概述了CanFestival3及其在工业自动化中的重要性,随后深入分析其核心原理与架构,包括协议栈基础、配置与初始化以及通信机制。文章详细介绍了CanFestival3在不同工业应用场景中的实践应用案例,如制造业和智慧城市,强调了其对机器人控制系统
【海康威视VisionMaster SDK秘籍】:构建智能视频分析系统的10大实践指南

# 摘要
本文详细介绍了海康威视VisionMaster SDK的核心概念、基础理论以及实际操作指南,旨在为开发者提供全面的技术支持和应用指导。文章首先概述了智能视频分析系统的基础理论和SDK架构,紧接着深入探讨了实际操作过程中的环境搭建、核心功能编程实践和系统调试。此外,本文还分享了智能视频分析系统的高级应用技巧,如多通道视频同步分析、异常行为智能监测和数据融合
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )