Statistical Tests for Model Evaluation: Using Hypothesis Testing to Compare Models
发布时间: 2024-09-15 14:40:58 阅读量: 47 订阅数: 31 

Applied_Linear_Statistical_Models.rar_Statistical Models_site:ww
# Basic Concepts of Model Evaluation and Hypothesis Testing
## 1.1 The Importance of Model Evaluation
In the fields of data science and machine learning, model evaluation is a critical step to ensure the predictive performance of a model. Model evaluation involves not only the production of accurate predictions but also a profound understanding of the model's stability and generalization capabilities. Hypothesis testing, as a core concept in statistics, plays a key role in model evaluation. It allows us to infer model parameters based on existing data and test their statistical significance, thereby quantifying the reliability and predictive power of the model.
## 1.2 Introduction to Hypothesis Testing
Hypothesis testing is a statistical method used to infer population parameters based on sample data. In the context of model evaluation, it often involves constructing statistical hypotheses about model parameters and using data to decide whether to reject these hypotheses. This process typically includes setting up a null hypothesis (H0) and an alternative hypothesis (H1), and then calculating a p-value to determine whether to reject the null hypothesis. The p-value is the probability of observing the statistical result or something more extreme, and if the p-value is less than the significance level (usually 0.05), then the null hypothesis is rejected, considering the observed effect to be statistically significant.
## 1.3 The Relationship between Model Evaluation and Hypothesis Testing
In model evaluation, hypothesis testing is often used to verify whether the model's assumptions are met, such as linear relationships and normally distributed residuals. Additionally, hypothesis testing can be used to compare the predictive performance of different models, such as using cross-validation methods to test if there is a significant performance difference between two models. Ultimately, the goal of model evaluation and hypothesis testing is to ensure that the model performs well not only on sample data but also maintains consistent performance on new datasets, thereby achieving effective prediction and decision-making.
# Theoretical Basis of Statistical Tests
## 2.1 Concepts and Types of Statistical Hypotheses
A statistical hypothesis is the starting point for inferring population parameters in statistics. They are typically divided into two types: null and alternative hypotheses.
### 2.1.1 Definitions of Null and Alternative Hypotheses
The **null hypothesis** (H0) generally represents a state of no effect, no difference, or no association. It is the default state of the test, meaning that we assume there is no effect or difference until the evidence is sufficiently strong.
The **alternative hypothesis** (H1 or Ha) is opposite to the null hypothesis, indicating the presence of an effect, a difference, or some association. The alternative hypothesis is accepted after the null hypothesis has been rejected.
### 2.1.2 Differences between Two-Sided and One-Sided Tests
When conducting statistical tests, different test methods are used according to the needs of the research design:
The **two-sided test** is used to test whether sample data significantly differ from the population parameters, without considering the direction of the difference (i.e., larger or smaller).
The **one-sided test** is used to test whether sample data significantly greater or less than the population parameters, thus it is concerned with the direction of the difference.
## 2.2 Common Statistical Test Methods
### 2.2.1 Parametric and Nonparametric Tests
**Parametric tests** require that the data meet certain assumptions (e.g., normal distribution) and use sample data distribution parameters (such as mean and variance) for inference.
**Nonparametric tests** do not rely on the specific form of the population distribution and are suitable for situations that do not meet the conditions of parametric tests, such as unknown data distributions or those that significantly deviate from normal distribution.
### 2.2.2 Determining the Rejection and Acceptance Regions
When performing statistical tests, a **rejection region** (critical region) must be determined. If the test statistic falls into the rejection region, the null hypothesis is rejected. Otherwise, the null hypothesis is accepted.
The **acceptance region** is the area where the null hypothesis is not rejected, and it, along with the rejection region, constitutes all possibilities for decision-making.
## 2.3 Probability and Decision-Making Process of Statistical Tests
### 2.3.1 Types of Errors: Type I and Type II
A **Type I error** occurs when the null hypothesis is actually true but is incorrectly rejected, falsely assuming a significant difference or association. The probability of a Type I error is usually denoted by α.
A **Type II error** occurs when the null hypothesis is actually false, but not rejected. The probability of a Type II error is denoted by β, and 1-β represents **power**, which is the probability of correctly rejecting a false null hypothesis.
### 2.3.2 Significance Level and Power Analysis
The **significance level** (α level) is a predetermined threshold used to determine whether the results of a statistical test are statistically significant. Typically, α is set to 0.05 or 0.01.
**Power analysis** (power analysis) is used to evaluate the probability of correctly rejecting a false null hypothesis under specific effect sizes, α levels, and sample sizes. It helps determine the appropriate sample size and the power of statistical tests.
### 2.3.3 Calculation of Test Statistics and p-Values
Test statistics are calculated based on sample data and are used to test the null hypothesis. The calculation method of test statistics depends on the type of test selected and the distribution of the data.
A **p-value** (probability value) is the probability of observing the statistic or something more extreme under the condition that the null hypothesis is true. A small p-value means that the observed data are unlikely to be produced by random fluctuations alone, thereby providing evidence to reject the null hypothesis.
In practical applications, a threshold is usually set (e.g., 0.05), and if the p-value is less than this threshold, we reject the null hypothesis, considering the observed effect to be statistically significant.
# Hypothesis Testing Methods in Model Evaluation
### 3.1 Hypothesis Testing for Model Accuracy Evaluation
Accuracy is a key indicator of a model's predictive performance, measuring the correctness of the model's predictions. To scientifically evaluate a model's accuracy, hypothesis testing methods are often used to determine whether the model's predictive results are significantly better than random guessing.
#### 3.1.1 Applications of F-tests and t-tests in Model Evaluation
F-tests and t-tests are common parametric tests in statistics, used to assess the statistical significance of a model.
- The **t-test** is typically used to compare the mean differences between two independent samples or between a single sample mean and a known value. In model evaluation, we may use a one-sample t-test to determine if the model's predicted mean significantly differs from the actual values.
- The **F-test** is primarily used to compare the differences in variances between two or more samples and is commonly used in regression analysis to test the significance of the overall fit of a regression model. For example, in a multiple linear regression model, the F-test can help us determine if at least one explanatory variable has a statistically significant effect on the response variable.
```r
# R code example: One-sample t-test
# Assuming 'data' is a data frame containing model predicted values and actual values, where the Actual column contains actual values
t_test_result <- t.test(data$Predicted, mu=data$Actual, alternative="two.sided")
print(t_test_result)
```
In the above code, the `t.test` function is used for the one-sample t-test. The `mu` parameter is set to the mean of the actual values, and `alternative="two.sided"` indicates that we are interested in a two-tailed test.
- The application of the **F-test** is broader and can be used to determine if all explanatory variables as a whole significantly explain the model.
```r
# R code example: F-test
# Assuming 'lm_model' is a linear model fitted using the lm function
f_test_result <- anova(lm_model)
print(f_test_result)
```
In R, the `anova` function is used to perform variance analysis on linear models, and the results of the F-test will provide statistical evidence of whether the explanatory variables have a significant effect on the response variable.
#### 3.1.2 Applications of Chi-Square Test in Classification Models
In the evaluation of classification models, the Chi-square test is often used to examine whether there is an independent relationship between the predicted results of the classification model and the actual values. When the model predicts categorical variables, the Chi-square test is particularly useful.
```python
# Python code example: Chi-square test
from scipy.stats import chi2_contingency
# Assuming 'observed' is a two-dimensional array containing the frequency table of model predicted values and actual values
chi2, p, dof, expected = chi2_contingency(observed)
print(f"Chi-square statistic: {chi2}")
print(f"P-value: {p}")
```
In this example, the `chi2_contingency` function from the scipy library is used to perform the Chi-square test. The given observed frequency table (`observed`) is used to calculate the Chi-square statistic and the corresponding P-value.
### 3.2 Hypothesis Testing for Model Stability Evaluation
The stability of a model refers to its consistency and reliability under differ

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ECOTALK数据科学应用:机器学习模型在预测分析中的真实案例

# 摘要
本文对机器学习模型的基础理论与技术进行了综合概述,并详细探讨了数据准备、预处理技巧、模型构建与优化方法,以及预测分析案例研究。文章首先回顾了机器学习的基本概念和技术要点,然后重点介绍了数据清洗、特征工程、数据集划分以及交叉验证等关键环节。接
潮流分析的艺术:PSD-BPA软件高级功能深度介绍

# 摘要
电力系统分析在保证电网安全稳定运行中起着至关重要的作用。本文首先介绍了潮流分析的基础知识以及PSD-BPA软件的概况。接着详细阐述了PSD-BPA的潮流计算功能,包括电力系统的基本模型、潮流计算的数学原理以及如何设置潮流计算参数。本文还深入探讨了PSD-BPA的高级功
嵌入式系统中的BMP应用挑战:格式适配与性能优化
# 摘要
本文综合探讨了BMP格式在嵌入式系统中的应用,以及如何优化相关图像处理与系统性能。文章首先概述了嵌入式系统与BMP格式的基本概念,并深入分析了BMP格式在嵌入式系统中的应用细节,包括结构解析、适配问题以及优化存储资源的策略。接着,本文着重介绍了BMP图像的处理方法,如压缩技术、渲染技术以及资源和性能优化措施。最后,通过具体应用案例和实践,展示了如何在嵌入式设备中有效利用BMP图像,并探讨了开发工具链的重要性。文章展望了高级图像处理技术和新兴格式的兼容性,以及未来嵌入式系统与人工智能结合的可能方向。
# 关键字
嵌入式系统;BMP格式;图像处理;性能优化;资源适配;人工智能
参考资
PM813S内存管理优化技巧:提升系统性能的关键步骤,专家分享!
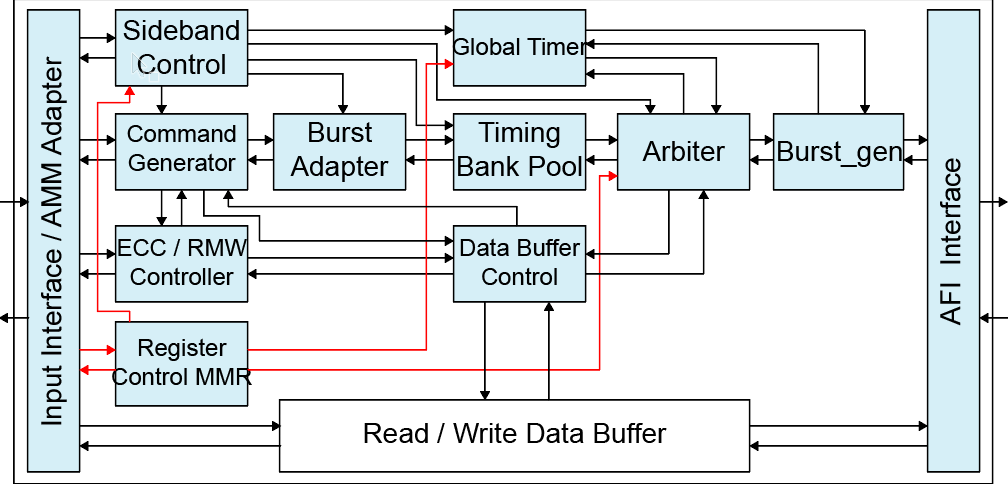
# 摘要
PM813S作为一款具有先进内存管理功能的系统,其内存管理机制对于系统性能和稳定性至关重要。本文首先概述了PM813S内存管理的基础架构,然后分析了内存分配与回收机制、内存碎片化问题以及物理与虚拟内存的概念。特别关注了多级页表机制以及内存优化实践技巧,如缓存优化和内存压缩技术的应用。通过性能评估指标和调优实践的探讨,本文还为系统监控和内存性能提
分析准确性提升之道:谢菲尔德工具箱参数优化攻略

# 摘要
本文介绍了谢菲尔德工具箱的基本概念及其在各种应用领域的重要性。文章首先阐述了参数优化的基础理论,包括定义、目标、方法论以及常见算法,并对确定性与随机性方法、单目标与多目标优化进行了讨论。接着,本文详细说明了谢菲尔德工具箱的安装与配置过程,包括环境选择、参数配置、优化流程设置以及调试与问题排查。此外,通过实战演练章节,文章分析了案例应用,并对参数调优的实验过程与结果评估给出了具体指
RTC4版本迭代秘籍:平滑升级与维护的最佳实践

# 摘要
本文重点讨论了RTC4版本迭代的平滑升级过程,包括理论基础、实践中的迭代与维护,以及维护与技术支持。文章首先概述了RTC4的版本迭代概览,然后详细分析了平滑升级的理论基础,包括架构与组件分析、升级策略与计划制定、技术要点。在实践章节中,本文探讨了版本控制与代码审查、单元测试
【Ubuntu 16.04系统更新与维护】:保持系统最新状态的策略
# 摘要
本文针对Ubuntu 16.04系统更新与维护进行了全面的概述,探讨了系统更新的基础理论、实践技巧以及在更新过程中可能遇到的常见问题。文章详细介绍了安全加固与维护的策略,包括安全更新与补丁管理、系统加固实践技巧及监控与日志分析。在备份与灾难恢复方面,本文阐述了
CC-LINK远程IO模块AJ65SBTB1现场应用指南:常见问题快速解决
# 摘要
CC-LINK远程IO模块作为一种工业通信技术,为自动化和控制系统提供了高效的数据交换和设备管理能力。本文首先概述了CC-LINK远程IO模块的基础知识,接着详细介绍了其安装与配置流程,包括硬件的物理连接和系统集成要求,以及软件的参数设置与优化。为应对潜在的故障问题,本文还提供了故障诊断与排除的方法,并探讨了故障解决的实践案例。在高级应用方面,文中讲述了如何进行编程与控制,以及如何实现系统扩展与集成。最后,本文强调了CC-LINK远程IO模块的维护与管理的重要性,并对未来技术发展趋势进行了展望。
# 关键字
CC-LINK远程IO模块;系统集成;故障诊断;性能优化;编程与控制;维护
【光辐射测量教育】:IT专业人员的培训课程与教育指南

# 摘要
光辐射测量是现代科技中应用广泛的领域,涉及到基础理论、测量设备、技术应用、教育课程设计等多个方面。本文首先介绍了光辐射测量的基础知识,然后详细探讨了不同类型的光辐射测量设备及其工作原理和分类选择。接着,本文分析了光辐射测量技术及其在环境监测、农业和医疗等不同领域的应用实例。教育课程设计章节则着重于如何构建理论与实践相结合的教育内容,并提出了评估与反馈机制。最后,本文展望了光辐射测量教育的未来趋势,讨论了技术发展对教育内容和教
SSD1306在智能穿戴设备中的应用:设计与实现终极指南
# 摘要
SSD1306是一款广泛应用于智能穿戴设备的OLED显示屏,具有独特的技术参数和功能优势。本文首先介绍了SSD1306的技术概览及其在智能穿戴设备中的应用,然后深入探讨了其编程与控制技术,包括基本编程、动画与图形显示以及高级交互功能的实现。接着,本文着重分析了SSD1306在智能穿戴应用中的设计原则和能效管理策略,以及实际应用中的案例分析。最后,文章对SSD1306未来的发展方向进行了展望,包括新型显示技术的对比、市场分析以及持续开发的可能性。
# 关键字
SSD1306;OLED显示;智能穿戴;编程与控制;用户界面设计;能效管理;市场分析
参考资源链接:[SSD1306 OLE
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )