"CLIP_ Connecting text and images.pdf"
这篇PDF文件介绍了CLIP( Contrastive Language-Image Pre-training,对比语言-图像预训练)模型,这是一个由OpenAI在2021年推出的重要人工智能研究项目。CLIP的目标是通过自然语言监督高效地学习视觉概念,从而实现文本与图像的连接。这一技术对于AI领域,尤其是计算机视觉和自然语言处理方面,具有深远的影响。
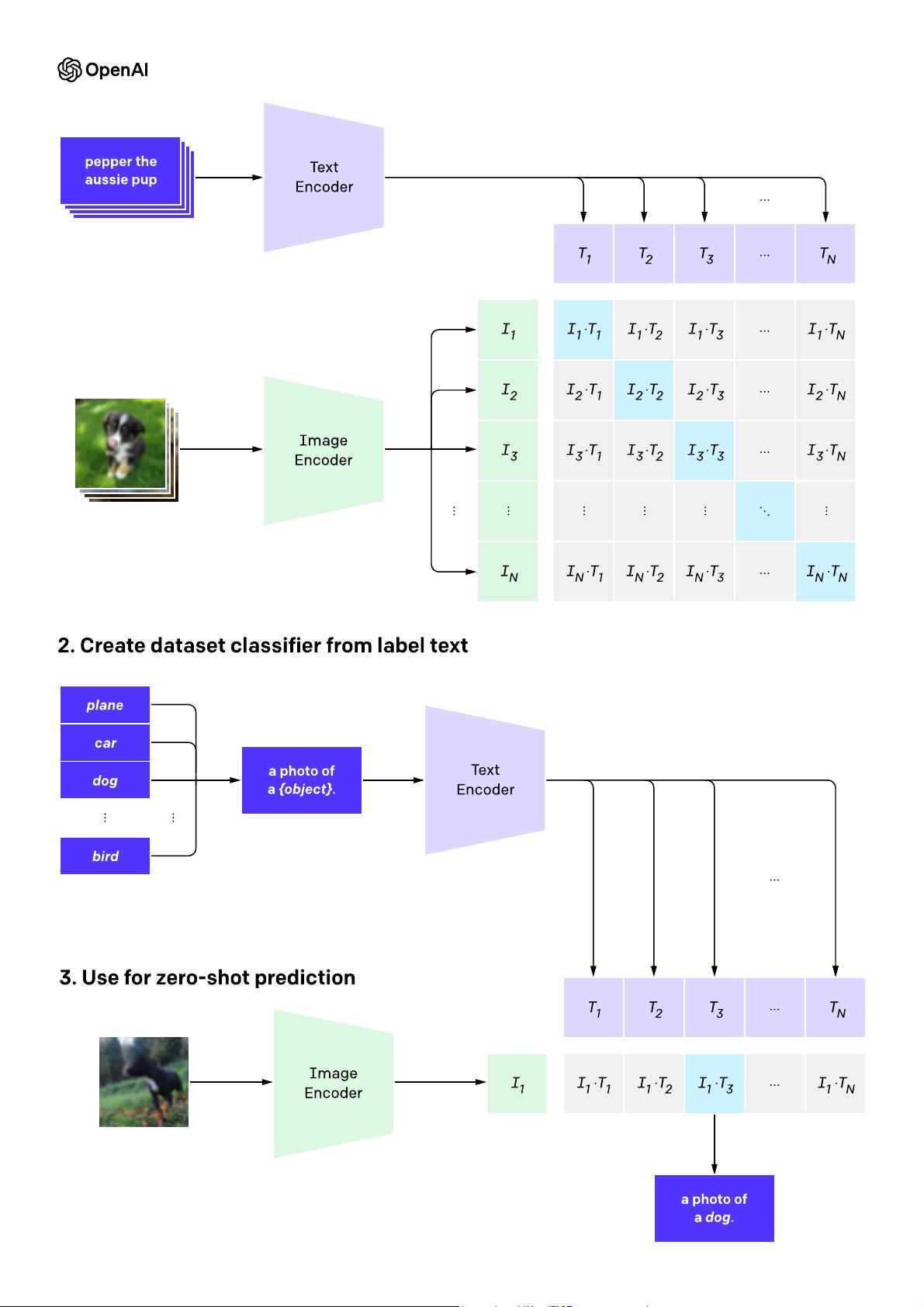
CLIP的核心在于其零样本(zero-shot)学习能力,类似于GPT-2和GPT-3模型,它无需针对特定任务进行大量标注数据的训练,只需提供视觉类别的名称,就能进行识别。这解决了传统计算机视觉方法中存在的几个主要问题:
1. 数据集问题:当前的计算机视觉数据集通常需要大量的人工标注,成本高昂且仅涵盖有限的视觉概念。
2. 模型泛化性:标准的视觉模型往往只能擅长单一任务,适应新任务时需要大量调整和训练。
3. 性能局限:在基准测试中表现出色的模型在压力测试下性能往往令人失望,引发了对深度学习方法在计算机视觉应用中的有效性质疑。
CLIP的出现,通过对比学习的方法,使得模型可以从大量未标注的文本-图像对中学习通用的表示,增强了模型的泛化能力和跨任务适应性。这种方法不仅减少了对特定任务数据的依赖,还提升了模型在现实世界复杂场景下的理解能力。
CLIP的贡献和里程碑意义在于:
- 它开创了预训练模型在视觉任务上的应用,尤其是在零样本或少样本学习上的突破,为计算机视觉和自然语言处理的融合提供了新的途径。
- 通过对比学习,CLIP能够在大规模的无标注数据上学习到丰富的语义信息,提高了模型的泛化能力。
- 它为解决深度学习在实际应用中的局限性,如数据集依赖、模型泛化差等问题,提供了可能的解决方案。
CLIP模型是人工智能领域的一个重要进展,它在连接文本和图像的理解上取得了显著成果,对于未来AI的发展,尤其是ChatGpt等AI聊天机器人在理解和生成与图像相关的上下文时,具有重要的参考价值。