
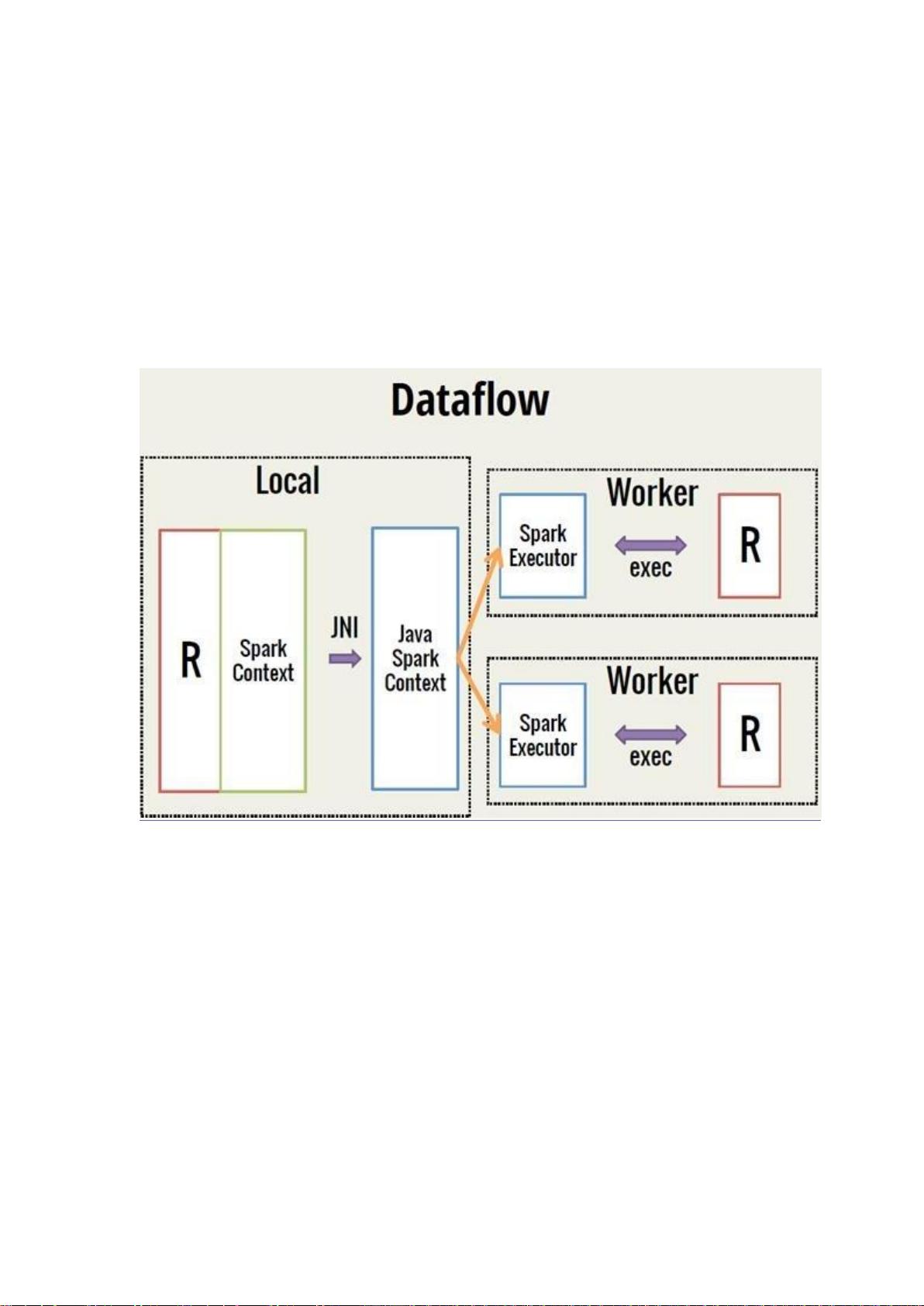
上,极大得扩展了 R 的数据处理能力。
SparkR 的几个特性:
l 提供了 Spark 中弹性分布式数据集(RDD)的 API,用户可以在集群上通过 R shell 交互性的运行 Spark
job。
l 支持序化闭包功能,可以将用户定义函数中所引用到的变量自动序化发送到集群中其他的机器上。
l SparkR 还可以很容易地调用 R 开发包,只需要在集群上执行操作前用 includePackage 读取 R 开发包
就可以了,当然集群上要安装 R 开发包。
2.8 Tachyon
Tachyon 是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像
Spark 和 MapReduce 那样。通过利用信息继承,内存侵入,Tachyon 获得了高性能。Tachyon 工作集文件
缓存在内存中,并且让不同的 Jobs/Queries 以及框架都能内存的速度来访问缓存文件”。因此,Tachyon
可以减少那些需要经常使用的数据集通过访问磁盘来获得的次数。Tachyon 兼容 Hadoop,现有的 Spark 和
MR 程序不需要任何修改而运行。
在 2013 年 4 月,AMPLab 共享了其 Tachyon 0.2.0 Alpha 版本的 Tachyon,其宣称性能为 HDFS 的 300 倍,
继而受到了极大的关注。Tachyon 的几个特性如下:
lJAVA-Like File API

剩余454页未读,继续阅读

duoduo_die
- 粉丝: 57
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- Lombok 快速入门与注解详解
- SpringSecurity实战:声明式安全控制框架解析
- XML基础教程:从数据传输到存储解析
- Matlab实现图像空间平移与镜像变换示例
- Python流程控制与运算符详解
- Python基础:类型转换与循环语句
- 辰科CD-6024-4控制器说明书:LED亮度调节与触发功能解析
- AE particular插件全面解析:英汉对照与关键参数
- Shell脚本实践:创建tar包、字符串累加与简易运算器
- TMS320F28335:浮点处理器与ADC详解
- 互联网基础与结构解析:从ARPANET到多层次ISP
- Redhat系统中构建与Windows共享的Samba服务器实战
- microPython编程指南:从入门到实践
- 数据结构实验:顺序构建并遍历链表
- NVIDIA TX2系统安装与恢复指南
- C语言实现贪吃蛇游戏基础代码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


