
4
of adding self-edges with same edge-labels is to keep track of the edg e labels that appear in a given
SCC. These edges help in determining paths going through an SCC without having to traverse the
entire SCC subgraph at query time.
:the_thirteenth_floor
:the_matrix
"1999"
:the_matrix_reloaded
1
2
3
4
5
:movie
6
:the_thirteenth_floor
"1999"
:the_matrix
:the_matrix_reloaded
:movie
Node N−SUCC−E
111111
001110
000000
000000
000000
N−PRED−E
110100
010000
000000
011000
010011
Edge Label
:releasedIn
:similar_to
rdf:type
EL−ID
100100
011000
000011
:similar_to
:similar_to
:releasedIn
:releasedIn
rdf:type
rdf:type
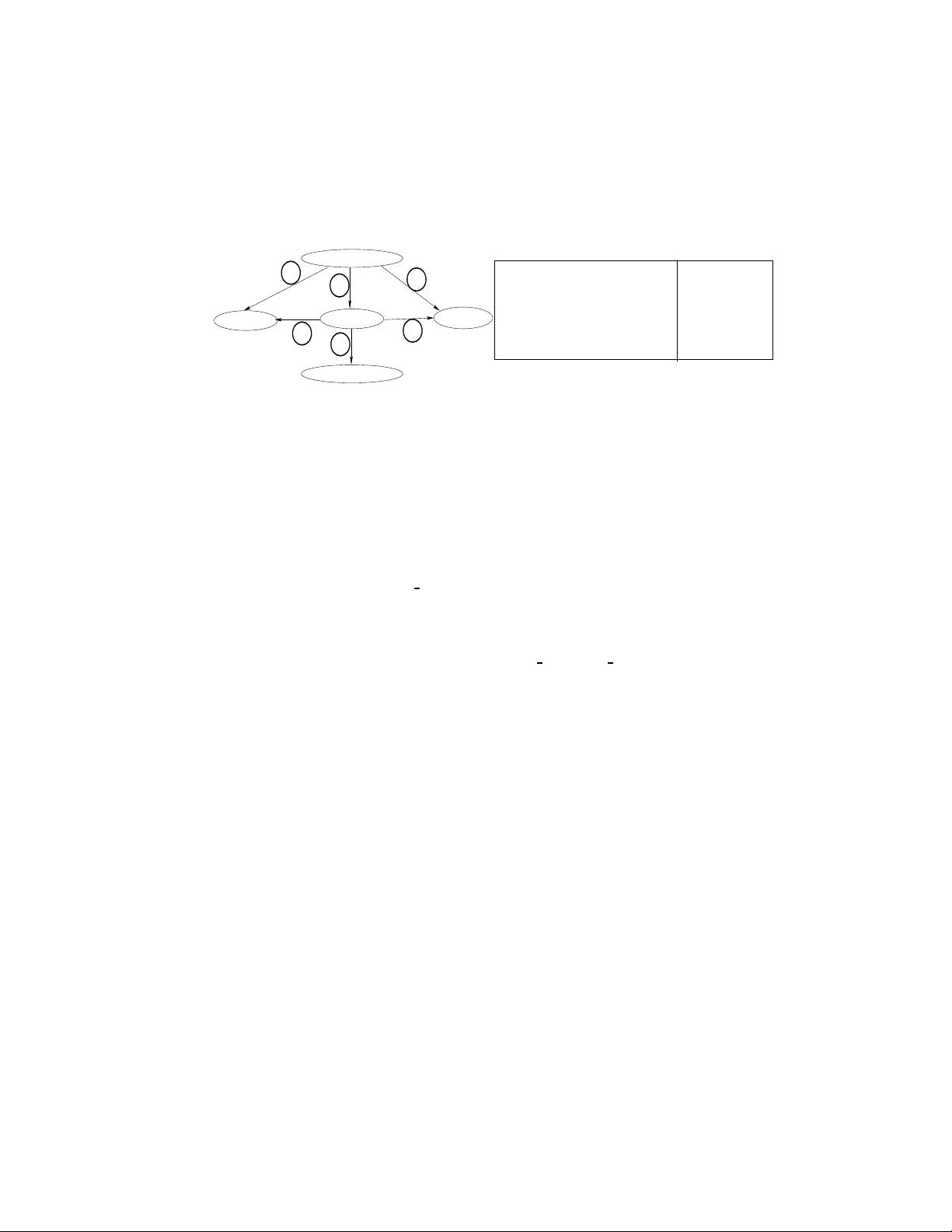
Fig. 2. BitPath Indexes using Compressed Bit-vectors
A label-order-constrained-reachability (LOCR) query requires knowledge of the relative order
of edge labels occurr ing on a given path. As pointed out in Section 1 a nd 2 previously, it is
computationally infeasible to index paths of the order of 10
25
or more due to time and space
constraints. We solve the problem of LOCR queries by creating four types of indexes on a graph,
and using a query answering algorithm, based on a combination of greedy-pruning and divide-and-
conquer method. The four types of indexes are as follows:
1. EID (edge-to-ID): Each edge e ∈ E is mapped to a unique integer ID. For instance, for the
graph shown in Fig. 2, edge (:the
matrix, :movie) with label rdf:type is mapped to ID 5.
2. N-SUCC-E (node’s successor edges): For each node, we index IDs of all the successor edges,
i.e., edges that w ill get visited if we traverse the subgraph under the given node. The self edges
added to the graph a s a result of collapsing an SCC ca n be handled trivially by examining the
head and tail of the given edge. In Fig. 2, node :the
thirteenth floor will have edge IDs 1, 2, 3,
4, 5, 6 in its successor list.
3. N-PRED-E (node’s predecessor edges): Similarly, for each node we index the pr edecessor edges,
i.e., edges that will get vis ited if we make a backward traversal on the entire subgraph above
the given node. In Fig. 2, node :movie will have edge IDs 2, 5, 6 in its predecessor list.
4. EL-ID (edge label to edge ID): For each unique edge label l ∈ L, we index IDs of all the edges
in E which have edge label l. In Fig. 2, edge label rdf:type will have IDs 5 and 6 in its list.
In practice, we use bit-vectors of length |E| (total number of edges in the graph), for building
N-SUCC-E, N-PRED-E, and EL-ID indexes. Each bit position in the bit-vector corresponds to
the unique ID assigned to an edge as per the EID index. Fig. 2 shows the indexes for the given
example graph. We apply run-length-encoding on N-SUCC-E a nd N-PRED-E indexes of each node
depe nding on the compression ratio. Typically the unique edge labels in the graph are much fewer
compared to the number of nodes. Hence in an EL-ID index of an edge label, there are many
more interleaved 0s and 1s as c ompared to an N-SUCC-E or N-PRED-E index, which precludes
the benefit of run-length-encoding. Hence we do not apply run-length encoding on the EL-ID
index. Note that at the time of querying we do not uncompress any compressed indexes. All the
algorithms are implemented to perform bitwise operations on both the gap-compres sed indexes as
well as non-compressed indexes.
3.1 BitPath Index Creation Procedure
We create EID, N-SUCC-E, and EL-ID indexes in one depth-first-search (DFS) pass over the DAG
generated after collapsing the SCCs as outlined previously. N-PRED-E index is created by making
one backward DFS pass on the graph and using the EID mapping generated in the first pass.
剩余16页未读,继续阅读

weixin_38703669
- 粉丝: 8
- 资源: 879
 我的内容管理
展开
我的内容管理
展开







最新资源
- 最优条件下三次B样条小波边缘检测算子研究
- 深入解析:wav文件格式结构
- JIRA系统配置指南:代理与SSL设置
- 入门必备:电阻电容识别全解析
- U盘制作启动盘:详细教程解决无光驱装系统难题
- Eclipse快捷键大全:提升开发效率的必备秘籍
- C++ Primer Plus中文版:深入学习C++编程必备
- Eclipse常用快捷键汇总与操作指南
- JavaScript作用域解析与面向对象基础
- 软通动力Java笔试题解析
- 自定义标签配置与使用指南
- Android Intent深度解析:组件通信与广播机制
- 增强MyEclipse代码提示功能设置教程
- x86下VMware环境中Openwrt编译与LuCI集成指南
- S3C2440A嵌入式终端电源管理系统设计探讨
- Intel DTCP-IP技术在数字家庭中的内容保护
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


