
0
0.5
1
1.5
1846 1932 2019
E-2
(a) Date of Birth
USA
UK
DE
CAN
IT
JP
AUS
India
(b) Nationality
Actor
Screenwriter
Film Director
Film Producer
Politician
Writer
(c) Profession
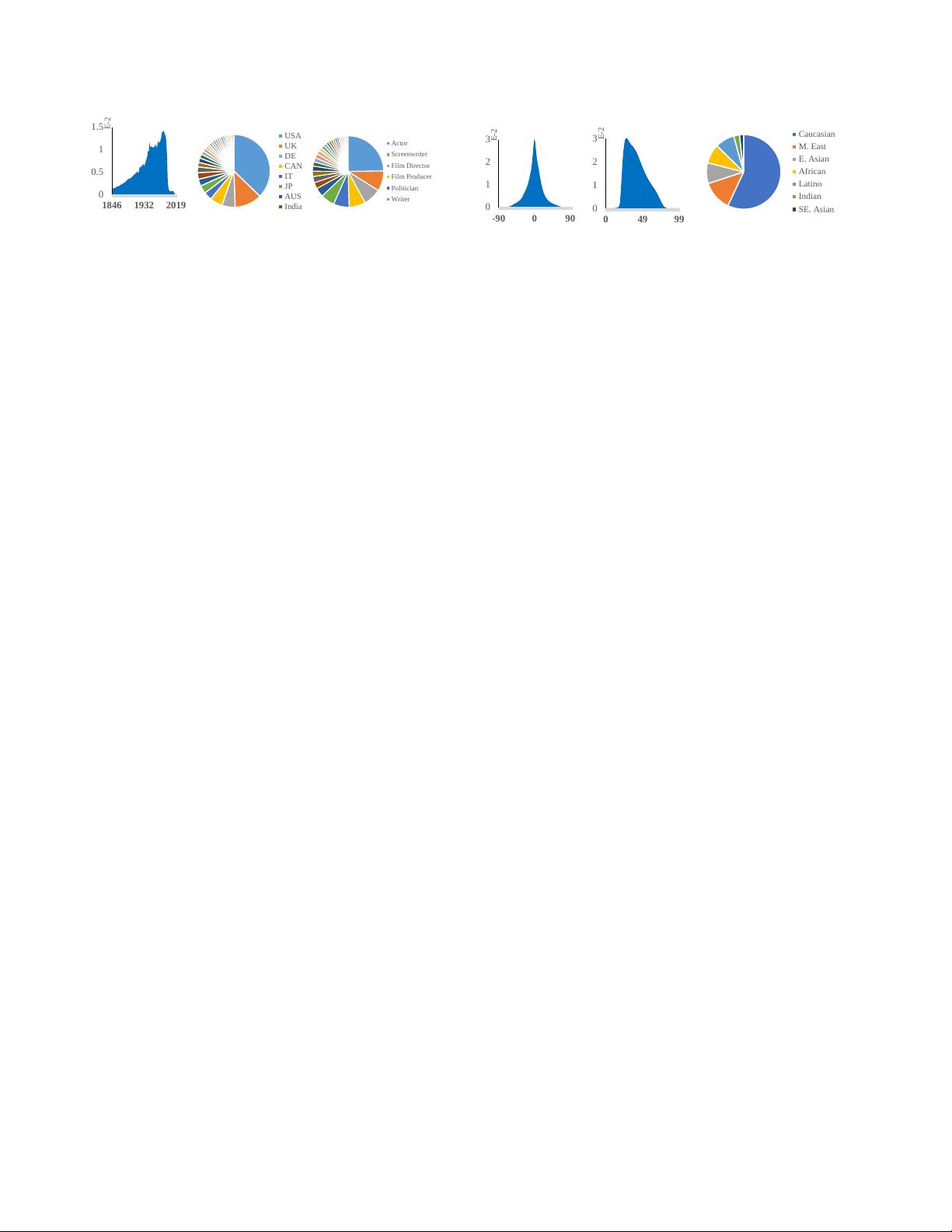
Figure 2: Date of birth, nationality and profession of WebFace260M.
referring to different deployment scenarios.
• Based on the new benchmark, we perform exten-
sive million-scale face recognition experiments. En-
abled by distributed training framework, comprehen-
sive baselines are established on our test set under the
FRUITS protocol. The results indicate substantial im-
provement room for light-weight track, as well as the
necessity of innovation in heavy-weight track.
2. WebFace260M and WebFace42M
Celebrity name list and image collection. Knowl-
edge graphs website Freebase [3] and well-curated web-
site IMDB [4] provide excellent resources for collecting
celebrity names. Furthermore, commercial search engines
such as Google [5] make it possible to collect images of
a specific identity with ranked correlation. Our celebrity
name list consists of two parts: the first one is borrowed
from MS1M (1M, constructed from Freebase) and the sec-
ond one is collected from the IMDB database. There are
nearly 4M celebrity names in the IMDB website, while
we found some subjects have no public image from search
engines. Therefore, only 3M celebrity names in IMDB
are chosen for our benchmark. Based on the name list,
celebrity faces are searched and downloaded via Google im-
age search engine. 200 images per identity are downloaded
for top 10% subjects, while 100, 50, 25 images are reserved
for remaining 20%, 30%, 40% subjects, respectively. Fi-
nally, we collect 4M identities and 265M images.
Face pre-processing. Faces are detected and aligned
through five landmarks predicted by RetinaFace [11]. For
multi-face images, we only select the largest face with
the above-threshold score, which can filter most improper
faces (e.g. background faces or wrong decoding). Af-
ter pre-processing, there remains 4M identities/260M faces
(WebFace260M) shown as Tab.1. The statistics of Web-
Face260M are illustrated in Fig.2 including date of birth,
nationality and profession. Persons in WebFace260M come
from more than 200 distinct countries/regions and more
than 500 different professions with the date of birth back
to 1846, which guarantees a great diversity in our training
data.
Cleaned WebFace42M. We perform CAST pipeline
(Sec.3) to automatically clean the noisy WebFace260M and
obtain a cleaned training set named WebFace42M, consist-
0
1
2
3
-90 0 90
E-2
(a) Pose
0
1
2
3
0 49 99
E-2
(b) Age
Caucasian
M. East
E. Asian
African
Latino
Indian
SE. Asian
(c) Race
Figure 3: Pose (yaw), age and race of WebFace42M.
ing of 42M faces of 2M subjects. Face number in each
identity varies from 3 to more than 300, and the average
face number is 21 per identity. As shown in Fig.1 and
Tab.1, WebFace42M offers the largest cleaned training data
for face recognition. Compared with the MegaFace2 [38]
dataset, the proposed WebFace42M includes 3 times more
identities (2M vs. 672K), and near 10 times more im-
ages (42M vs. 4.7M). Compared with the widely used
MS1M [21], our training set is 20 times (2M vs. 100K)
and 4 times (42M vs. 10M) more in terms of # identities
and # photos. According to [64], there are more than 30%
and 50% noises in MegaFace2 and MS1M, while noise ra-
tio of WebFace42M is lower than 10% (similar to CASIA-
WebFace [84]) based on our sampling estimation. With
such a large data size, we take a significant step towards
closing the data gap between academia and industry.
Face attributes on WebFace42M. We further provide 7
face attribute annotations for WebFace42M, including pose,
age, race, gender, hat, glass, and mask. Fig.3 presents the
distribution of our cleaned training data in different aspects.
WebFace42M covers a large range of poses (Fig.3(a)), ages
(Fig.3(b)) and most major races in the world (Fig.3(c)).
3. Cleaning Automatically by Self-Training
Since the images downloaded from the web are consid-
erably noisy, it is necessary to perform a cleaning step to
obtain high-quality training data. Original MS1M [21] does
not perform any dataset cleaning, resulting in near 50%
noise ratio, and significantly degrades the performance of
the trained models. VGGFace [41], VGGFace2 [8] and
IMDB-Face [64] adopt semi-automatic or manual clean-
ing pipelines, which require expensive labor efforts. It
becomes challenging to scale up the current annotation
size to even more identities. Although the purification in
MegaFace2 [38] is automatic, its procedure is complicated
and there are considerably more than 30 % noises [64]. An-
other relevant exploration is to cluster faces via unsuper-
vised approaches [40, 35, 51] and supervised graph-based
algorithm [85, 82, 81, 20, 72]. However, these methods as-
sume the whole dataset is clean, which is not suitable for
the extremely noisy WebFace260M.
Recently, self-training [77, 79, 42, 43], a standard ap-
proach in semi-supervised learning [48, 83], is explored to
significantly boost the performance of image classification.
3
剩余10页未读,继续阅读


kupeThinkPoem
- 粉丝: 3w+
- 资源: 38
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


