
KSII TRANSACTIONS ON INTERNET AND INFORMATION SYSTEMS VOL.9, NO. 4, April 2015 1427
Large-margin nearest neighbor (LMNN) [26] took the class margin into account. SDPM [35]
formulated Mahalanobis distance learning as a convex optimization problem. Distance metric
learning with eigenvalue optimization (DML-eig.) [36] casted distance learning problem as a
eigenvalue optimization problem. [33] learnt local perceptual distance function which is a
combination of a set of local distance functions. [37] proposed to learn the Mahalanobis
distance function subject to a set of pairwise constraints, i.e., must-links that associate images
which must be in the same class and cannot-links that associate images which must be in
different classes. [38] made ues of context information to learn similarity measures. [39, 16]
leveraged discriminative learning techniques to learn similarity measure.
Probabilistic similarity methods formulate explicit feautre space or similarity measure
based on the quantities of adopted probabilistic models. Probability product kernels [21] used
the posterior distributions of hidden variables to characterize the samples, and define the
similarity measure as the expectation of the inner product of the hidden variables, with respect
to the posterior distribtuions. [22] used distributions to characterize the samples and uses
Kullback–Leibler divergence over those distributions to measure the distance between
samples. [23] developed a hierarchical probabilistic model to learn image representation and
similarity. Fisher score (FS) [20] derived feature mapping by considering how the samples
affect the model parameters, and defined the similarity, i.e., Fisher kernel, as the inner product
of the feature mappings of samples. Free energy score space (FESS) [24] and posterior
divergence (PD) [25] extended Fisher score by exploring more informative measures. These
approaches are able to exploit information from probabilistic models, they however can be
further boosted through fully exploiting the class label, by fitting the similarity measure to the
retrieval performance. Dsicriminative Fisher kernel learning (DFK) [28] extents Fisher kernel
to cooperate class label, where Gaussian mixture model is used to model the distribution of
visual features. It does not utiliize semantic level information in an explicit way.
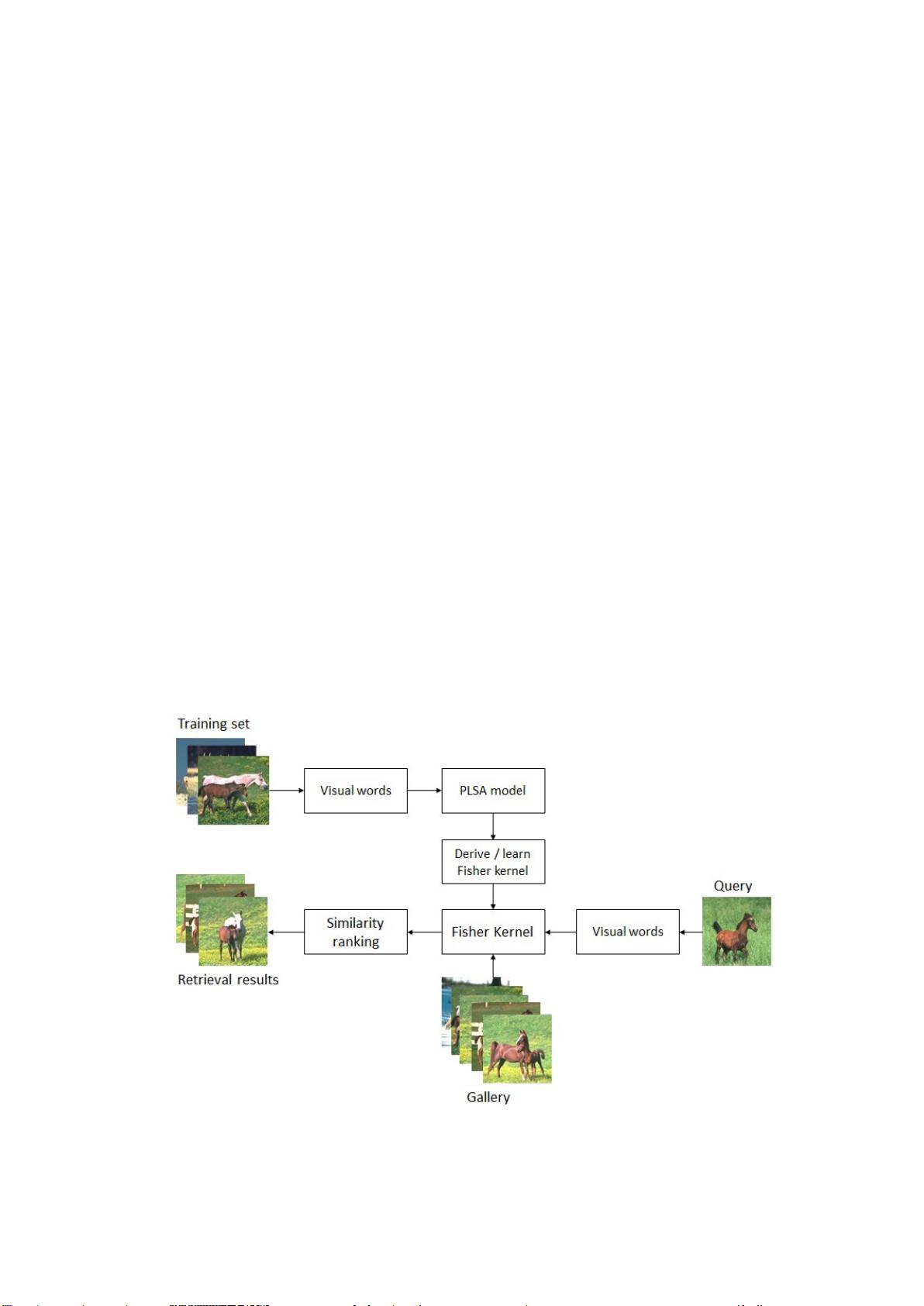
Fig. 1. The framework of our proposed approach PLSA-FK.
剩余16页未读,继续阅读

weixin_38499336
- 粉丝: 8
- 资源: 953
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


