
基于基于FPGA加速的卷积神经网络识别系统加速的卷积神经网络识别系统
针对卷积神经网络(CNN)在通用CPU以及GPU平台上推断速度慢、功耗大的问题,采用FPGA平台设计了并行化
的卷积神经网络推断系统。通过运算资源重用、并行处理数据和流水线设计,并利用全连接层的稀疏性设计稀
疏矩阵乘法器,大大提高运算速度,减少资源的使用。系统测试使用ORL人脸数据库,实验结果表明,在100
MHz工作频率下,模型推断性能分别是CPU的10.24倍,是GPU的3.08倍,是基准版本的1.56倍,而功率还不到
2 W。最终在模型压缩了4倍的情况下,系统识别准确率为95%。
0 引言引言
随着近些年深度学习的迅速发展和广泛的应用,卷积神经网络(CNN)
[1]
已经成为检测和识别领域最好的方法,它可以自动地
从数据集中学习提取特征,而且网络层数越多,提取的特征越有全局性。通过局部连接和权值共享可以提高模型的泛化能力,
大幅度提高了识别分类的精度。并且随着物联网的发展,部署嵌入式端的卷积神经网络要处理大量的数据,这将会消耗大量的
资源与能量,而嵌入式设备通常用电池维持工作,频繁更换电池将会提高成本,因此对于推断阶段的运算加速以及低功耗设计
有重要实际意义。
CNN的不同卷积核的运算之间是相互独立的,而且全连接层的矩阵乘法不同行之间也是独立的,因此神经网络的推断在
CPU平台上串行计算的方式是非常低效的。GPU可以通过流处理器实现一定的并行性,但是缺乏对于网络并行结构的深度探
索,不是最优的方案。而基于FPGA的神经网络可以更好地实现网络并行计算与资源复用,因此本文采用FPGA加速卷积神经
网络运算。
此前已有一些基于FPGA的卷积神经网络加速器,WANG D设计了流水线卷积计算内核
[2]
;宋宇鲲等人针对激活函数进行设
计优化
[3]
;王昆等人通过ARM+FPGA软硬件协同设计的异构系统加速神经网络
[4]
;张榜通过双缓冲技术与流水线技术对卷积
优化
[5]
。本文针对卷积神经网络的并行性以及数据与权值的稀疏性,对卷积层和全连接层进行优化,根据卷积核的独立性设计
单指令多数据(Single Instruction Multiple Data,SIMD)的卷积与流水线结构,提高计算速度与资源效率,利用全连接层数据极
大的稀疏性,设计稀疏矩阵乘法器减少计算冗余,然后对模型参数定点优化,最后将实验结果与CPU、GPU平台以及基准设
计
[5]
进行比较分析。
1 CNN模型与网络参数模型与网络参数
1.1 CNN模型模型
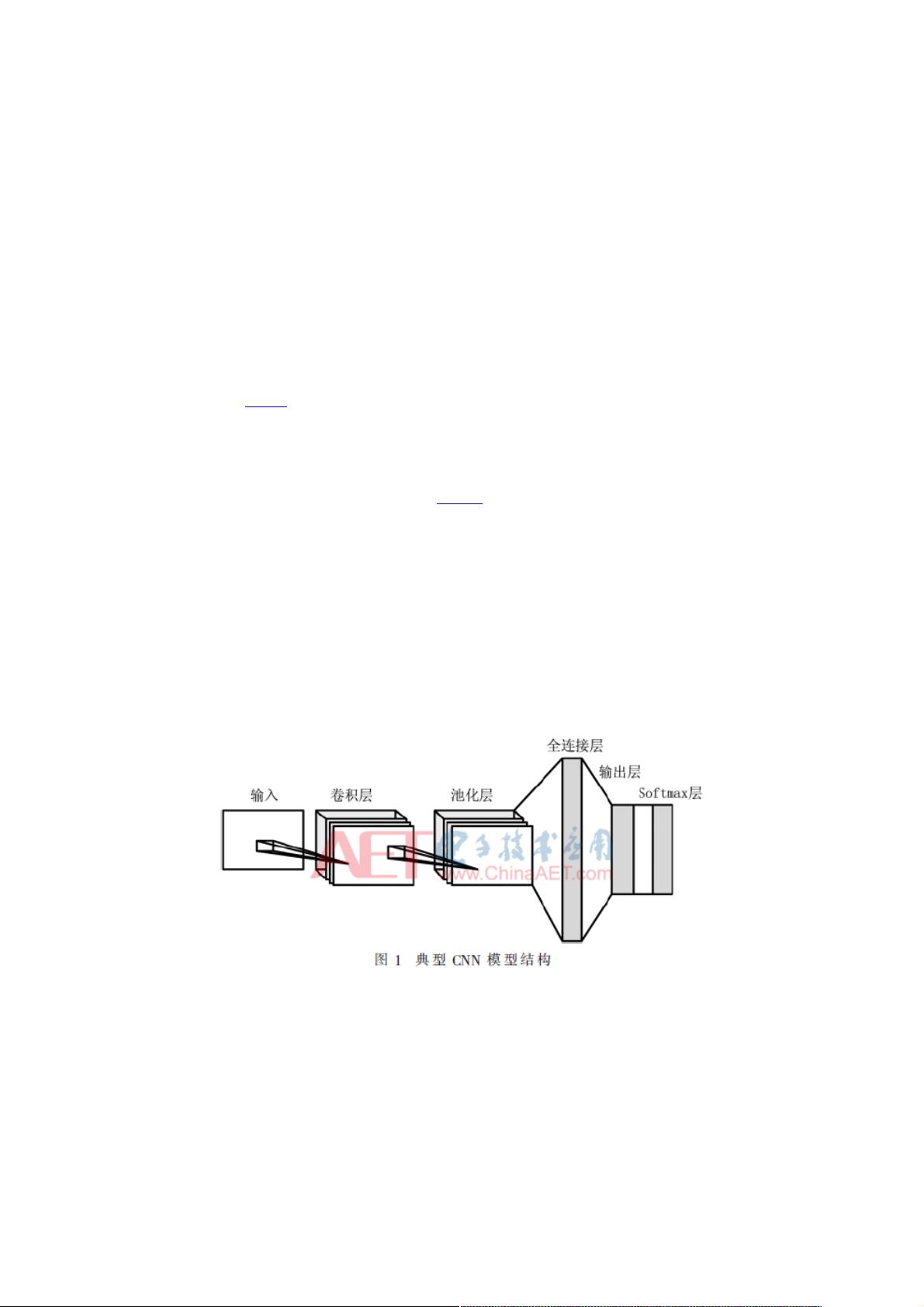
CNN是基于多层感知机的神经网络结构,典型的CNN模型由输入层、卷积层、全连接层、输出层和分类层组成,如图1所
示。由输入层读取图像数据,由卷积层通过多个卷积核分别和输入图卷积生成多个特征图,再由池化层降维提取特征图信息。
经过几个卷积层后,再将特征图展开成向量,输入给全连接层,经过全连接层与输出层的矩阵运算得到输出,然后再通过
Softmax分类层得到分类概率输出。
本文CNN模型结构如图2所示,该结构包含两个卷积层、两个池化层、一个全连接层,一个输出层、一个使用Softmax的分
类层,其中激活函数不算作一层,共7层的网络结构。其中两个卷积层的输出特征图个数分别为16、32,卷积核大小为3×3,
移动步长为1,输出尺寸与输入相同,系统使用线性修正单元(Rectified Linear Units,ReLU)作为激活函数。全连接层和输出
层分别有1 024和40个神经元。由图2计算得权值与偏置的数量,本文模型共4 765 416个参数,其中全连接层占了99%的参
数。

weixin_38701312
- 粉丝: 8
- 资源: 947
 我的内容管理
展开
我的内容管理
展开







最新资源
- Vue实现iOS原生Picker组件:详细解析与实现思路
- Arduino蓝牙小车:参数调试与功能控制
- 百度Java面试精华:200页精选资源涵盖核心知识点
- Swift使用CoreData填坑指南:CoreData在Swift 3.0的变化
- 微距离无线充电器创新设计及其实验探索
- MTK Android平台开发全攻略:44步详解流程
- RecyclerView全面解析:替代ListView的新选择
- Android开发:自动适配中英文键盘解决方案
- Android调用WebService接口教程
- Android开发:BitmapUtil图片处理全解析与实例
- Android多线程断点续传实现详解
- PCA算法在人脸识别会议签到系统中的应用
- EventBus 3.0:Android事件总线详解与实战应用
- Android FileUtil:全面解析文件操作实用技巧与实例
- RecyclerView添加头部和尾部实战教程
- Android实现微博滑动固定顶部栏实战与优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


