
Python文本统计功能之西游记用字统计操作示例文本统计功能之西游记用字统计操作示例
主要介绍了Python文本统计功能之西游记用字统计操作,结合实例形式分析了Python文本读取、遍历、统计等相关操作技巧,需要的朋友可以参考下
本文实例讲述了Python文本统计功能之西游记用字统计操作。分享给大家供大家参考,具体如下:
一、数据一、数据
xyj.txt,《西游记》的文本,2.2MB
致敬吴承恩大师,4020行(段)
二、目标二、目标
统计《西游记》中:
1. 共出现了多少个不同的汉字;
2. 每个汉字出现了多少次;
3. 出现得最频繁的汉字有哪些。
三、涉及内容:三、涉及内容:
1. 读文件;
2. 字典的使用;
3. 字典的排序;
4. 写文件
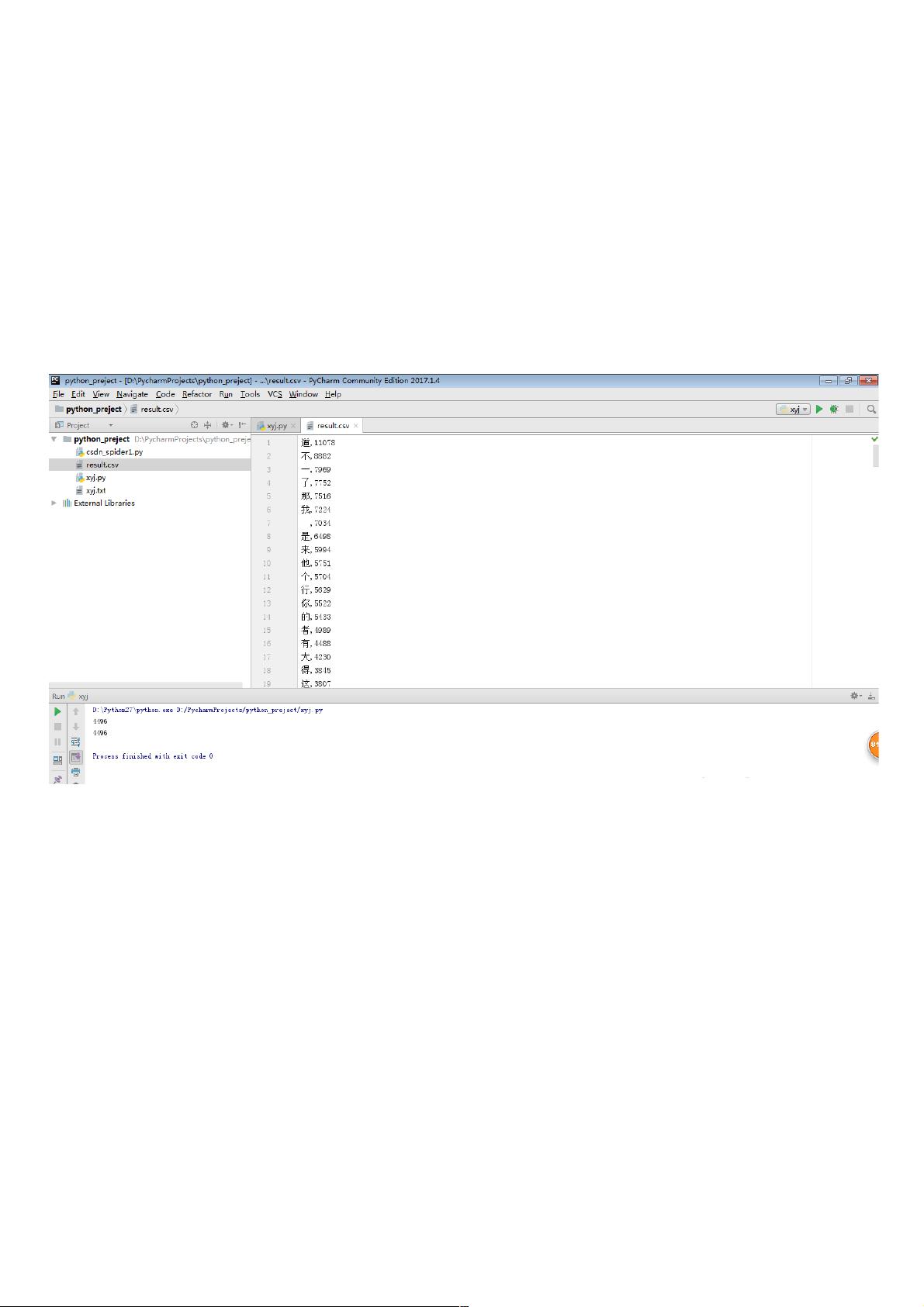
四、效果四、效果
五、源代码五、源代码
# coding:utf8
import sys
reload(sys)
sys.setdefaultencoding("utf8")
fr = open('xyj.txt', 'r')
characters = []
stat = {}
for line in fr:
# 去掉每一行两边的空白
line = line.strip()
# 如果为空行则跳过该轮循环
if len(line) == 0:
continue
# 将文本转为unicode,便于处理汉字
line = unicode(line)
# 遍历该行的每一个字
for x in xrange(0, len(line)):
# 去掉标点符号和空白符
if line[x] in [' ','', '\t', '', '。', ',', '(', ')', '(', ')', ':', '□', '?', '!', '《', '》', '、', ';', '“', '”', '……']:
continue
# 尚未记录在characters中
if not line[x] in characters:
characters.append(line[x])
# 尚未记录在stat中
if not stat.has_key(line[x]):
stat[line[x]] = 0
# 汉字出现次数加1
stat[line[x]] += 1
print len(characters)
print len(stat)
# lambda生成一个临时函数
# d表示字典的每一对键值对,d[0]为key,d[1]为value
# reverse为True表示降序排序
stat = sorted(stat.items(), key=lambda d:d[1], reverse=True)
fw = open('result.csv', 'w')
for item in stat:
# 进行字符串拼接之前,需要将int转为str
fw.write(item[0] + ',' + str(item[1]) + '')
fr.close()
fw.close()
PS:这里再为大家推荐:这里再为大家推荐2款非常方便的统计工具供大家参考:款非常方便的统计工具供大家参考:
在线字数统计工具:在线字数统计工具:

weixin_38590456
- 粉丝: 1
- 资源: 884
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 京瓷TASKalfa系列维修手册:安全与操作指南
- 小波变换在视频压缩中的应用
- Microsoft OfficeXP详解:WordXP、ExcelXP和PowerPointXP
- 雀巢在线媒介投放策划:门户网站与广告效果分析
- 用友NC-V56供应链功能升级详解(84页)
- 计算机病毒与防御策略探索
- 企业网NAT技术实践:2022年部署互联网出口策略
- 软件测试面试必备:概念、原则与常见问题解析
- 2022年Windows IIS服务器内外网配置详解与Serv-U FTP服务器安装
- 中国联通:企业级ICT转型与创新实践
- C#图形图像编程深入解析:GDI+与多媒体应用
- Xilinx AXI Interconnect v2.1用户指南
- DIY编程电缆全攻略:接口类型与自制指南
- 电脑维护与硬盘数据恢复指南
- 计算机网络技术专业剖析:人才培养与改革
- 量化多因子指数增强策略:微观视角的实证分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


